UNSW Stats reading group 2016 - Causal DAGs
An introduction to conditional independence DAGs and their use for causal data.
October 17, 2016 — October 20, 2016
tl;dr: These are the notes from a reading group I led in 2016 on causal DAGs. When I have time to expand these notes into complete sentences, I will migrate the good bits to an expanded and improved notebook on causal DAGS. For now, see the updated and fixed version of this.
We follow Pearl’s summary (Pearl (2009a)). (approx sections 1-3 of the Pearl paper.)
In particular, I want to get to the identification of causal effects given an existing causal DAG from observational data with unobserved covariates via criteria such as the back-door criterion. We’ll see.
Approach: casual, motivate Pearl’s pronouncements, without deriving everything from axioms. Not statistical; will not answer the question of how we infer graph structure from data. Will skip many complexities by taking several slightly over-restrictive conditions, which we would relax if we were not doing this in 1 hour.
Not covered: UGs, PDAGs…
Assumptions: No-one here is an expert in this DAG graphical formalism for causal inference.
1 Motivational examples
- Wet pavements
- Obesity contagion
- Nobel prizes and chocolate
- Simpson’s paradox
- etc
2 Machinery
We are interested in representing influence between variables in a non-parametric fashion.
Our main tool to do this will be conditional independence DAGs, and causal use of these. Alternative name: “Bayesian Belief networks”. (Overloads “Bayesian”, so not used here)
2.1 DAGs
DAG: Directed (probabilistic) graphical model. Graph defined, as usual, by a set of vertexes and edges.
We show the directions of edges by writing them as arrows.
For nodes
Familiar from, e.g., Structural equation models, hierarchical models, expert systems. General graph theory…
A graph with directed edges, and no cycles. (you cannot return to the same starting node traveling only forward along the arrows)
We need some terminology.
- Parents
-
The parents of a node
- Children
-
similarly,
- Co-parent
-
Ancestors and descendants should be clear as well. For convenience, we define
2.2 Random variables
I will deal with finite collections of random variables
For simplicity of exposition, each of the RVs will be supported on
Also, we are working with sets of random variables rather than sets of events and the discrete state space reduces the need to discuss sets of events.
Extension to continuous RVs, or arbitrary RVs is trivial for everything I discuss here. (A challenge is if the probabilities are not all strictly positive.)
Motivation in terms of structural models.
Without further information about the forms of
We are “nonparametric” in the sense that working with this conditional factorisation does not require any further parametric assumptions on the model.
However, we would like to proceed from this factorisation to conditional independence, which is non-trivial. Specifically, we would like to know which variables are conditionally independent of others, given such an (assumed) factorisation.
More notation: We write
for
We also use this notation for sets of random variables, and will bold them when it is necessary to emphasise this.
Questions:
However, this product notation is not illuminating; we use a graph formalism. That’s where the DAGs come in.
This will proceed in 3 steps
The graphs will describe conditional factorisation relations.
We do some work to construct from these relations some conditional independence relations, which may be read off the graph.
From these relations plus a causal interpretation we derive rules for identification of causal relations
If we get further than that, it will be all about coffee
Anyway, a joint distribution
Uniqueness?
It would be tempting to suppose that a node is independent of its children given its parents or somesuch. But things are not quite so simple.
Questions:
To make precise statements about conditional independence relations we do more work.
We need new graph vocabulary and conditional independence vocabulary.
Axiomatic characterisation of conditional independence. (Pearl 2008; Steffen L. Lauritzen 1996).
Theorem: ((Pearl 2008)) For disjoint subsets
Then the relation
(*) The Intersection axiom only holds for strictly positive distributions.
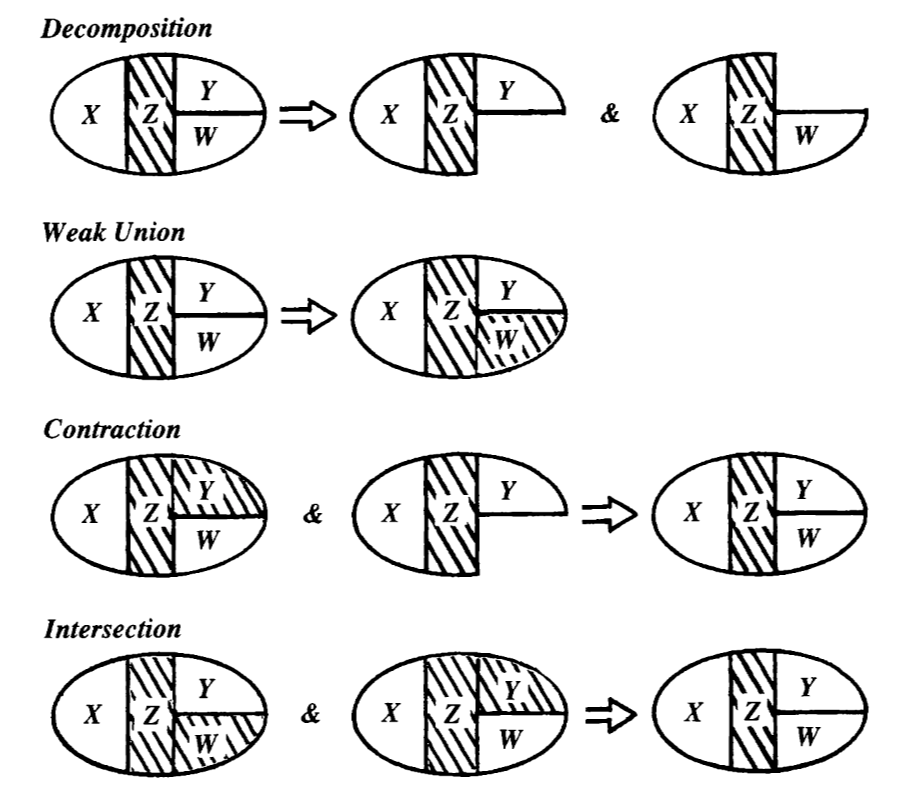
How can we relate this to the topology of the graph?
The flow of conditional information does not correspond exactly to the marginal factorisation, but it relates. (mention UG connections?)



Definition: A set
There is a node
There is a node
If a path is not blocked, it is active.
Definition: A set
This looks ghastly and unintuitive, but we have to live with it because it is the shortest path to making simple statements about conditional independence DAGs without horrible circumlocutions, or starting from undirected graphs, which is tedious.
Theorem: (Pearl 2008; Steffen L. Lauritzen 1996). If the joint distribution of
This puts us in a position to make non-awful, more intuitive statements about the conditional independence relationships that we may read off the DAG.
Corollary: The DAG Markov property.
Corollary: The DAG Markov blanket.
Define
Then
3 Causal interpretation
Finally!
We have a DAG
Assume
- The
- We additionally assume faithfulness, that is, that
So, are we done? Only if correlation equals causation.
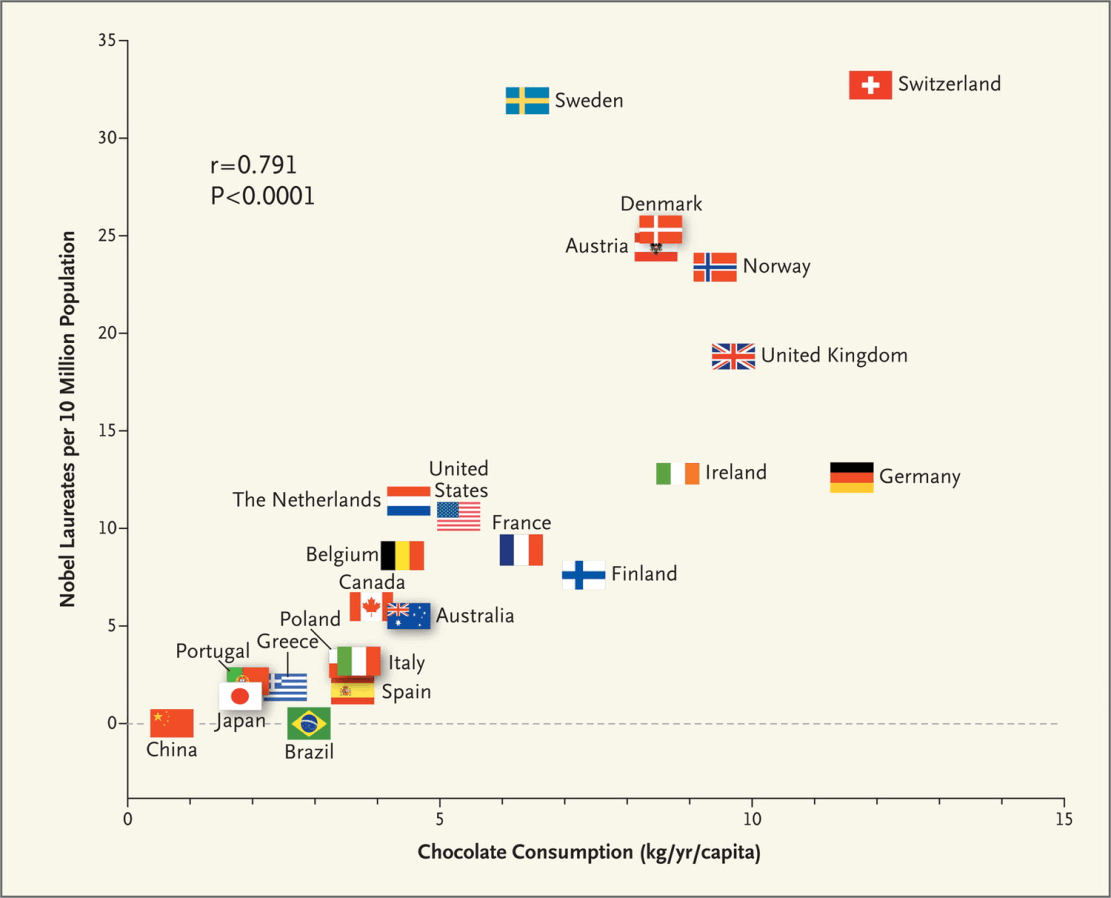

We add the additional condition that
- all the relevant variables are included in the graph. (We coyly avoid making this precise)
The BBC raised one possible confounding variable:
[…] Eric Cornell, who won the Nobel Prize in Physics in 2001, told Reuters “I attribute essentially all my success to the very large amount of chocolate that I consume. Personally I feel that milk chocolate makes you stupid… dark chocolate is the way to go. It’s one thing if you want a medicine or chemistry Nobel Prize but if you want a physics Nobel Prize it pretty much has got to be dark chocolate.”
Finally, we need to discuss the relationship between conditional dependence and causal effect. This is the difference between, say,
and
Called “truncated factorization” in the paper.
If we know
Now suppose we are not given complete knowledge of
What variables must we know the conditional distributions of in order to know the conditional effect? That is, we call a set of covariates
Criterion 1: The parents of a cause are an admissible set (Pearl 2009a).
Criterion 2: The back door criterion.
A set
This is a sufficient condition.
Causal properties of sufficient sets:
Hence
4 Examples
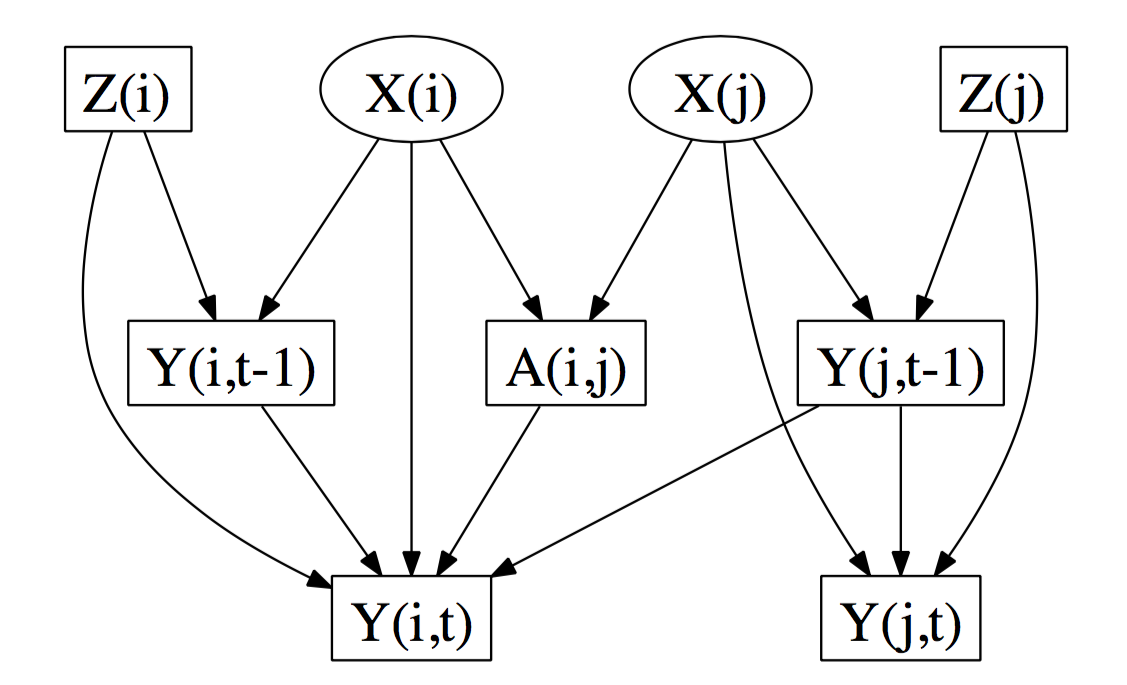
d-separates from . Since is latent and unobserved, is a confounding path from to . Likewise is a confounding path from to . Thus, and are d-connected when conditioning on all the observed (boxed) variables […] . Hence the direct effect of on is not identifiable
5 Recommended reading
People recommend Koller and Friedman, which includes many different flavours of DAG model and many different methods, (Koller and Friedman 2009) but it didn’t suit me, being somehow too detailed and too non-specific at the same time.
Spirtes et al (Spirtes, Glymour, and Scheines 2001) and Pearl (Pearl 2009a) are readable. See also Pearl’s edited highlights (Pearl 2009b). Lauritzen ((Steffen L. Lauritzen 1996)) is clear but the details of the constructions are long and detailed and more general than here. (Partially directed graphs.)
Lauritzen’s shorter introduction (Steffen L. Lauritzen 2000) is nice if you can get it; Not overwhelming, starts with a slightly more general formalism (DAGs as a special case of PDAGs, moral graphs everywhere). Murphy’s textbook (Murphy 2012) has a minimal introduction intermingled with some related models, with a more ML, “expert systems”-flavoured and more Bayesian formalism.