Knowledge collapse and the epistemic commons
What happens to collective knowledge when individual learning becomes optional
2023-03-23 — 2026-04-21
Wherein Welfare Is Shown to Be Non-Monotone in the Precision of Agentic AI Recommendations, an Interior Optimum Being Identified Past Which Aggregate Wellbeing Is Diminished by Further Improvements in Accuracy.
Well, it’s really terribly simple, […] it works any way you want it to. You see, the computer that runs it is a rather advanced one. In fact, it is more powerful than the sum total of all the computers on this planet including—and this is the tricky part—including itself.
— Douglas Adams, Dirk Gently’s Holistic Detective Agency

How do foundation models change the economics of knowledge production?
To a first-order approximation, LLMs provide a way of massively compressing collective knowledge and synthesizing the bits I need on demand. They do seem pretty good at being “nearly as smart as everyone on the internet combined.” I’m not sure the distinction between “synthesizing” and “generating” is so clear-cut; certainly much of my publication track record is “merely” synthesizing, and it was bitter and hard work.
Using these models will test how much collective knowledge depends on our participation in boring, boilerplate grunt work, and which incentives are necessary to encourage us to produce and share our individual contributions.
There is an interesting economic question about what externalities we internalise, or vice versa, with this new mode of knowledge usage. When I solve a problem myself, I get a private return: the answer I needed. I can also produce a public by-product — general understanding that other people can reuse later. Nobody pays me for the by-product; it is a positive externality. The shared stock of human knowledge is the accumulation of those externalities.
What happens when an LLM supplies the private return — the answer — without my doing the learning that used to generate the by-product? If individual learning becomes optional, does the commons that depended on it continue?
1 Complement or substitute?
Is AI a bicycle or a snowmobile?
The question looks different at the individual and societal scales.
Consider a doctor diagnosing a patient. She needs two kinds of knowledge: broad medical understanding (how diseases work, which treatments exist, what the literature says about drug interactions) and knowledge specific to this patient (their symptoms, history, lifestyle, preferences). Neither kind is much use without the other — knowing everything about the patient is worthless if she doesn’t understand the disease, and vice versa. And the process of learning generates both at once: reading the patient’s chart and examining them sharpens her understanding of their case and deposits a thin layer of general medical insight that could, in principle, help other doctors with other patients. Which is to say there are economies of scope in learning — the private return (context-specific knowledge) and the public by-product (general knowledge) are jointly produced.
Acemoglu, Kong, and Ozdaglar (2026) build a formal model of this process: a private return that motivates the effort, and a public by-product that nobody is paid for. When a software engineer diagnoses a rare bug, the private payoff is fixing their product. Turning the insight into a maintained Stack Overflow answer would help many future developers, but yields only a small private return — so many such insights never get written down even before AI comes along.
Now we introduce agentic AI. It’s good at the context-specific part: given a patient’s records, it can synthesize a personalised recommendation. This substitutes for the doctor’s own investigative effort — she doesn’t need to work as hard to reach a decent diagnosis. But general medical knowledge complements that effort: the more she understands, the higher the marginal return from examining this particular patient. It seems likely that agentic AI improves individual decisions right now, while eroding the learning effort that sustains the long-run stock of human-generated collective knowledge.
2 Knowledge collapse
Acemoglu, Kong, and Ozdaglar (2026) argue that this dynamic can tip into a knowledge-collapse steady state. In their baseline model when human effort is sufficiently elastic and agentic recommendations exceed an accuracy threshold, the economy converges to an equilibrium in which the human-generated stock of general knowledge vanishes entirely. No human learning, no human-generated externality, no commons. The AI can still give personalised advice, but it’s drawing on a depleted well.
The mechanism:
- Agentic AI improves → less incentive for costly human learning effort
- Less effort → less general knowledge generated as a by-product
- Less general knowledge → lower marginal return to remaining effort
- Repeat until the high-knowledge equilibrium disappears
In this baseline — assuming humans to be the sole source of new general knowledge — welfare is non-monotone in the accuracy of agentic AI. In their model, \(\tau_A\) measures the precision of the agentic recommendation (how good the AI’s personalised advice is), and \(\alpha > 1\) governs how elastic learning effort is — higher \(\alpha\) means effort drops off more steeply when the AI gets better. There is a finite welfare-maximising precision \(\tau_A^*\), and going past it makes everyone worse off. As \(\tau_A \to \infty\), welfare converges to zero — because there is nobody left generating the general knowledge that everything depends on.
When effort is very elastic (\(\alpha - 1 < \frac{1}{4}\)), the system admits multiple steady states: a high-knowledge one and a knowledge-collapse trap. Above a threshold \(\tau_A^c\), the high-knowledge steady state vanishes and collapse becomes inevitable regardless of initial conditions.
More effective aggregation of human-generated general knowledge — more effective sharing and pooling — unambiguously raises welfare and increases resilience to collapse. The asymptotic result is a kind of scaling law: both the collapse threshold and the optimal precision grow only logarithmically in aggregation capacity, and the planner optimally stays bounded away from the tipping point (by a factor of \(1/\alpha\)).
3 Empirical signs
For some early empirical indications that AI is already substituting for human effort, see Microsoft Study Finds AI Makes Human Cognition “Atrophied and Unprepared” (Lee 2025). I have many specific qualms about the experimental question the authors are answering there, but it’s a start.
On the coding Q&A site Stack Overflow, activity has dropped: fewer questions, less engagement, and less of the new knowledge that gets generated when experienced coders work through novel problems. Activity fell around 25% in the year after ChatGPT’s release, concentrated on exactly the questions a chatbot can answer (Del Rio-Chanona, Laurentsyeva, and Wachs 2024). The pattern looks similar on Wikipedia, where views and edits fell most for the articles ChatGPT can readily substitute (Lyu et al. 2025).
Kosmyna et al. (2025) find that leaning on ChatGPT for writing assistance reduces writers’ ability to remember and accurately quote their own arguments. The resulting essays also look more alike across writers, which the authors read as an erosion of individual voice and agency. Or maybe it just nudges every writer towards the truth(tm).
Invective: Why Quora isn’t useful anymore: A.I. came for the best site on the internet. is a more popular-press version of the same story.
4 Intellectual property and incentive shifts

Historically, there was a strong incentive for open publishing. In a world where LLMs effectively use all openly published knowledge, we might see a shift towards more closed publishing, secret knowledge, and hidden data, and away from reproducible research, open-source software, and open data, since publishing those things will be more likely to erode our competitive advantage.
Generally: will we wish to share truth and science in the future, or will economic incentives push us towards a fragmentation of reality into competing narratives, each with its own private knowledge and secret sauce?
Consider the incentives for humans to opt out of the tedious work of being themselves in favour of AI emulators: The people paid to train AI are outsourcing their work… to AI. This makes models worse (Shumailov et al. 2023).
We might ask: “Which bytes did you contribute to GPT4?”
5 Organizational knowledge dynamics
There is a theory of career moats — unique value propositions only I have, which make me unsackable. I’m quite fond of Cedric Chin’s writing on this theme, which is often about developing valuable skills. But he, and organizational literature generally, acknowledges there are other ways of ensuring unsackability that are less pro-social — for example, gaining power over resources, becoming a gatekeeper, or using opaque decision-making.
Both these strategies co-exist in organizations, but I think it’s likely that LLMs, by automating skills and knowledge, tilt incentives towards the latter. In that scenario, it’s rational for us to worry less about how well we use our skills and command of open (e.g. scientific, technical) knowledge to be effective, and instead to focus on how we can privatise or sequester secret knowledge that we control exclusively if we want to show a value-add to the organization.
How would that shape an organization, especially a scientific employer? Longer term, I’d expect to see a shift (in terms both of who is promoted and how staff personally spend time) from skill development and collaboration, towards resource control, competition, and privatization: less scientific publication, less open documentation of processes, less time doing research and more time doing funding applications, more processes involving service desk tickets to speak to an expert whose knowledge resides in documents we cannot see.
6 Synthetic data, model collapse, and the feedback loop

An obvious objection to the knowledge-collapse model: can’t AI generate its own training data and sidestep the dependence on human effort entirely?
Sometimes, yes. AlphaGo Zero learned to play Go from self-play alone, with no human games at all. More recently, AI systems have discovered faster matrix multiplication algorithms and proved theorems by generating candidates and checking them against formal verification. These domains have an objective correctness signal — we can tell whether a proof is valid or a move wins the game without needing a human to evaluate it. In such domains, synthetic data can substitute for human-generated knowledge. The total stock of knowledge (human + AI-generated) stays positive even if humans stop contributing, because the AI keeps discovering things on its own.
In such a world, the Acemoglu, Kong, and Ozdaglar (2026) model still has the human contribution collapsing. The total knowledge stock bottoms out above zero, however, so the welfare consequences while still potentially dire, are at least less so.
In domains without an objective correctness signal — open-ended text, policy advice, medical judgement, legal and scientific interpretation — synthetic data is not independent from the state of the world. An AI trained on its own outputs has no external check on whether it’s drifting. Recursive self-training becomes self-referential and degrades the information environment. Shumailov et al. (2023) call this model collapse: each generation of model, trained on the previous generation’s outputs, loses the tails of the distribution and converges on an something of potentially low goodness.
The distinction between these two hypothesized failure modes is approximately that
- Model collapse is about training on one’s own outputs.
- Knowledge collapse is about humans opting out of generating the inputs.
It seems imaginable to have both at once, e.g. in spamularity.
7 Why learn, young humans
If the machine can answer, why learn anything ourselves?
Jan Kulveit’s cyborg periods — windows in which human and AI together beat either alone — are the regimes where that understanding pays (Jan_Kulveit and rosehadshar 2023). The knowledge we are tempted to skip is the knowledge that lets us steer.
The second answer is: we learning is not only for ourselves (although it learning purely altruistically sounds like a slog).
It may be welfare-improving to deliberately limit how good agentic AI is allowed to be — adding noise to its recommendations so that people still have a reason to learn. The knowledge-collapse model argues that a planner optimally keeps AI accuracy bounded away from the level at which human learning gives out, and there is no regime in which “as accurate as possible” is the right setting. Airlines already enforce a version of this, mandating hand-flying so pilots keep their stick-and-rudder skills.
“Make the AI deliberately worse” is a hard sell, and I don’t know how to operationalise it.
The Tragedy of the Cognitive Commons: How the Smartest AI Could Produce the Dumbest Society is a long polemical analysis of Acemoglu, Kong, and Ozdaglar (2026).
8 Aggregation is more optimistic
One result in the model is unambiguously good news: the better we get at pooling and sharing human knowledge, the higher the welfare — and the harder collapse becomes to fall into. One angle of attack in this case would be to invest in knowledge-sharing infrastructure: open-access publishing, well-maintained Q&A platforms, Wikipedia-like commons, open data, reproducible research. The complement to human effort is the quality of the shared commons, not the power of the agentic recommendation. How is human-facing knowledge sharing infrastructure distinct from LLMs in any case? Careful definitions needed.
Which brings us back to public sphere business models.
9 Matt Might’s PhD and the LLM
Think of Matt Might’s iconic illustrated guide to a Ph.D..



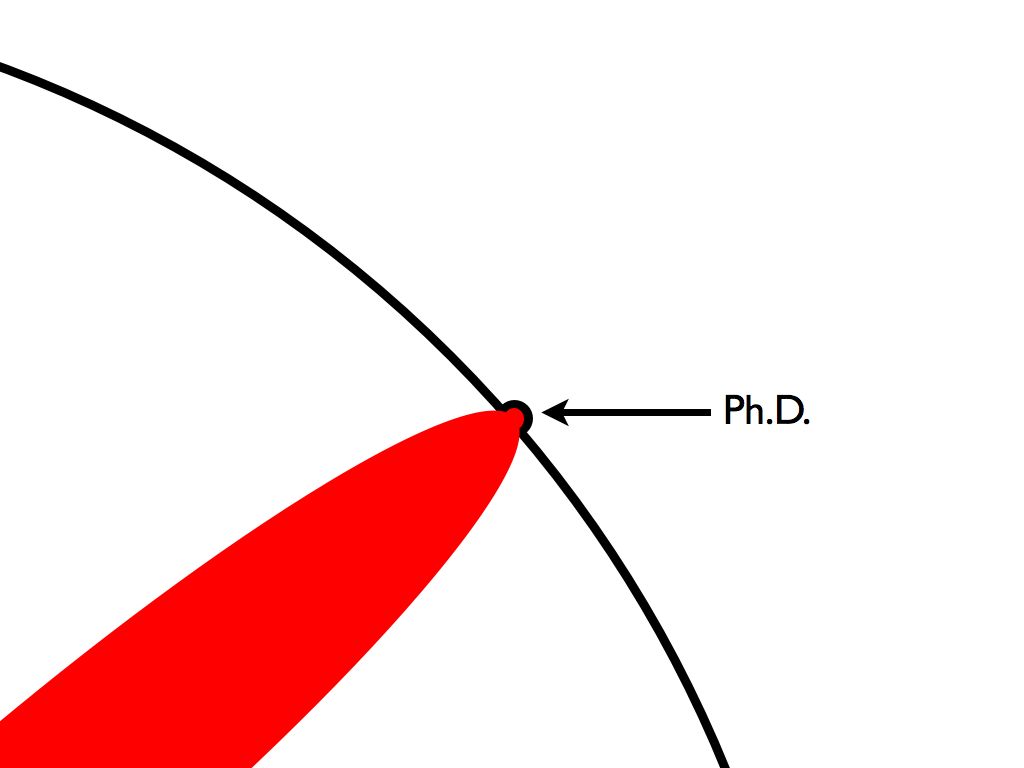
In the 2020s, does the map look like this?

If the knowledge-collapse story is right, the circle doesn’t just get a smooth bump outward. The LLM fills in context-specific synthesis — the stuff inside the circle — while the human effort that pushes the boundary outward (novel general knowledge, the externality nobody internalizes) starts to erode. In domains where AI can push the boundary on its own (formal proofs, games), this may not matter. In domains where it can’t (medicine, policy, the social sciences, most of what we mean by “understanding the world”), the dent we make during a PhD might still matter — but the substrate we’re pushing against is thinning, because fewer people are doing the unglamorous work of maintaining it.
10 Incoming
Qiu et al. (2025)
MALUS - Clean Room as a Service | Liberation from Open Source Attribution
Large AI models are cultural and social technologies (Farrell et al. 2025)
Greg Egan, Understudies
In a future where the rich kids are being raised with a digital Cyrano beside them to sweet-talk their way into the best jobs, four friends train together for a battle to prove that other kinds of minds might still have the edge.
I Do Not Think It Means What You Think It Means: Artificial Intelligence, Cognitive Work & Scale
Ilya Sutskever: “Sequence to sequence learning with neural networks: what a decade”