Formalising “everything happens for a reason” via computational complexity
2025-08-04 —
2025-11-07
Wherein a Computational No‑coincidence Conjecture Is Presented and a Neural‑network Null Model Is Developed, With an Advice String and Verifier Being Used to Certify Rare All‑negative Outputs.
adversarial
AI safety
computational complexity
game theory
machine learning
sparser than thou
Figure 1
A computational no-coincidence principle(Christiano, Neyman, and Xu 2022) is another way of approaching interpretability. What if we think about good neural network performance as learning a representation more compact than memorization of the data, expressed in the language of computational complexity? We’d call a representation simple if that principle can be “efficiently verified” in some sense from a compact proof. This feels attractive, intuitively, but, holy blazes, I suspect the search for such proofs will be punishing.
Most everything I know about this topic is from being asked to review a paper for ILLIAD2. That review is reproduced below.
1 Review of a paper
I also reviewed exactly one paper for the conference proceedings (Dunbar and Aaronson 2025). Since it was an interesting learning experience, I want to release my review. I’m not 100% sure if this will violate the rules, unilaterally de-anonymising myself, but I think it is OK, and moreover, any costs from that choice will be paid by me, rather than the authors, and the value of the review is non-zero I think.
1.1 Reviewer abstract
I know a bit about random neural networks but less about computational complexity. I put all my notes in the “abstract” in the hope that it will be useful for others with my background, and because it might expose my errors of reasoning. If you already know about such things, you can skip to the end.
Note: Since there was some notation clash between the original blog post and this paper, I introduce compromise notation. Dunbar’s \(n\) is \(m\).
If an apparently outrageous coincidence happens in mathematics, then there is a reason for it.
They see his no-coincidence principle and counter with the computational no-coincidence conjecture (CNCC), which uses computational-complexity machinery in the space of random functions to turn it into something we can imagine operationalizing.
I don’t come from computational complexity, so I’ll spell the computational no-coincidence conjecture out here for myself and others like me. I’ll give it in a form that I hope is abstract enough to cover the cases we care about but concrete enough to be pedagogical. Suppose we have a universe of functions (circuits, neural networks, Turing machines), and suppose that this universe comes equipped with a probability measure so we can draw functions at random from it.
Working with random functions has some annoying technicalities; let’s barrel through them briskly. Because I’m an ML guy, I’ll assume we only care about real vector functions — that’s specific enough for me to keep in my head, and it’s worked for me so far. Call this universe \(\Omega\). Each function \(f \in \Omega\) is a map from1\(\mathbb{R}^{m}\to\mathbb{R}^{m}\) i.e. we have an \(m\)-dimensional input space and an \(m\)-dimensional output space.2. We call the probability measure \(\mu\)3 and for technical probability-theory reasons we want a \(\sigma\)-algebra defined (“\(\mathcal{F}\)”) over our function space so that things don’t go haywire when we attempt to compute probabilities of “things” in this function space. This is generally easy for discrete function spaces but gets tedious for function spaces between vectors over continuous fields like the reals. \(\mathcal{F}\) needs to hold all the sets over which we might attempt to compute probabilities. We wrap these up in a probability tuple \((\Omega, \mu, \mathcal{F})\) that lets us do probability stuff in a well-posed way to our universe of functions.
There are various desirable properties for this function space.
For our phenomena of interest, we should be able to guesstimate how likely it is to be observed by chance, i.e. we should be able to bound probabilities of rare events of interest (we will come back to this)
We should be required to spend the absolute minimum of time arsing about with \(\sigma\)-algebras and other distracting technical machinery.
The function space should map cleanly onto some class of functions we care about (e.g. it should be “easy” to interpret things from our function space as neural nets or Turing machines or what-have-you)
The original blog post addressed these desiderata by dealing with the space of random reversible circuits, i.e. random Boolean functions with some nice structure from \(\{0,1\}^{3n}\to \{0,1\}^{3n}\) (i.e. \(m=3n\)). These objects are discrete, so desideratum (2) is easy. They have a neat approximation in terms of random permutations, so that’s (1) dealt with. (3) is addressed by deciding we care about Boolean circuits for now, and computer scientists are comfortable thinking about the space of Boolean circuits as a toy model for all kinds of things like formal logic and… other discrete problems that computer scientists care about.
Let’s fix on the setting of that Neyman blog post: random deep reversible Boolean circuits \(f: \{0,1\}^{3n} \to \{0,1\}^{3n}\). The distribution is concrete — e.g., pick a random sequence of 3-bit reversible gates, arranged in layers that touch all wires, to a given depth. For large enough depth, such circuits behave pseudorandomly: recent results apparently show they achieve strong \(k\)-wise independence.
This motivates modelling a deep random reversible circuit as though it were drawn uniformly from the symmetric group on \(\{0,1\}^{3n}\), \(\mathrm{Sym}(\{0,1\}^{3n})\).4 So that solves (1) for us. There are a lot of permutations, but we’ve studied the crap out of them, so that should be manageable. This gives us a simple, albeit approximate, distribution for circuits.
To bring us back to the main goal: we’re doing this because we want a good notion of the distributions of such functions — circuits that might, if we squint, look a bit like deductions about the world — so we can quantify what it means for their behaviour to be remarkable and what it might mean to explain remarkable behaviour \(P\). We are working toward the idea that something is remarkable if its behaviour is “outrageously coincidental”, which we can now gloss as very low probability under the null distribution.
We focus on properties \(P\) that talk about the mapping from inputs to outputs across the entire admissible input set. Formally:
\(P(f)\) means : there is no input \(x\) such that \(p_{\text{in}}(x)\) and \(p_{\text{out}}(f(x))\) are both true.
Here \(p_{\text{in}} : \{0,1\}^\ell \to \{\text{True},\text{False}\}\) and \(p_{\text{out}} : \{0,1\}^m \to \{\text{True},\text{False}\}\) are Boolean predicates on inputs and outputs, respectively.5 In Neyman’s example, let’s label it \(P^{(0)}\). \(p^0_{\text{in}}(x)\) is “the last \(n\) bits of \(x\) are all 0”, and \(p^0_{\text{out}}(y)\) is the same condition on \(y\). The \(P^{(0)}\) in Neyman’s blog post says: for every input whose last \(n\) bits are 0, the corresponding output’s last \(n\) bits are not all 0.
Spelling it out for myself: if there’s even one input in the \(p^0_{\text{in}}\) set whose output also lies in \(p^0_{\text{out}}\), then \(P^{(0)}(f)\) fails. That’s why a property like “output bit \(i > 2n\) is always 1 for all \(p_{\text{in}}\) inputs” is enough to guarantee \(P^{(0)}(f)\) — it eliminates the possibility of the output’s last \(n\) bits all being zero.
There are \(2^{3n}\) binary strings of length \(3n\). How many end in \(n\) zeros? \(2^{2n}\) of those. Permutations \(f\) that never produce a string ending in \(n\) zeros from a string ending in \(n\) zeros? Feels… enumerable. If we model it as something like a random process, it feels like we can estimate the probability of that event, and in fact the probability that a randomly chosen permutation does that, \[
(1-2^{-n})^{2^{2n}} \approx e^{-2^n}
\] In reality, the reversible-circuit distribution isn’t exactly uniform over all permutations — structured outliers exist — but for the purposes of bounding the probability of \(P^{(0)}(f)\) they’re probably negligible, so this simple form will do for the moment. So if a randomly chosen circuit has this property, I’d be astonished if \(n\) were bigger than the number of fingers I have.
We’re nearly at the computational no-coincidence conjecture — hang on; we want to use this machinery to capture “structure” in functions that explains outrageous coincidences. We’ll say an outrageous coincidence for a function \(f\) is explained by structure if there exists an advice string, \(\pi(f)\), and a verification algorithm \(V(f, \pi(f))\) that can quickly check \(P(f)\). “Quickly” means polynomial time in the “size” of \(f\), which can be some count of the number of gates.
The computational no-coincidence conjecture is that
For all \(f\) such that \(P(f)\) is true, \(V(f, \pi(f))=\textrm{true}\)
For 99% of \(f\) such that \(P(f)\) is false, there is no \(\pi(f)\) that makes \(V(f,\pi(f))=\textrm{true}\).
The 99% clause prevents us from breaking the computational complexity hierarchy. We can’t allow perfect classifiers here.
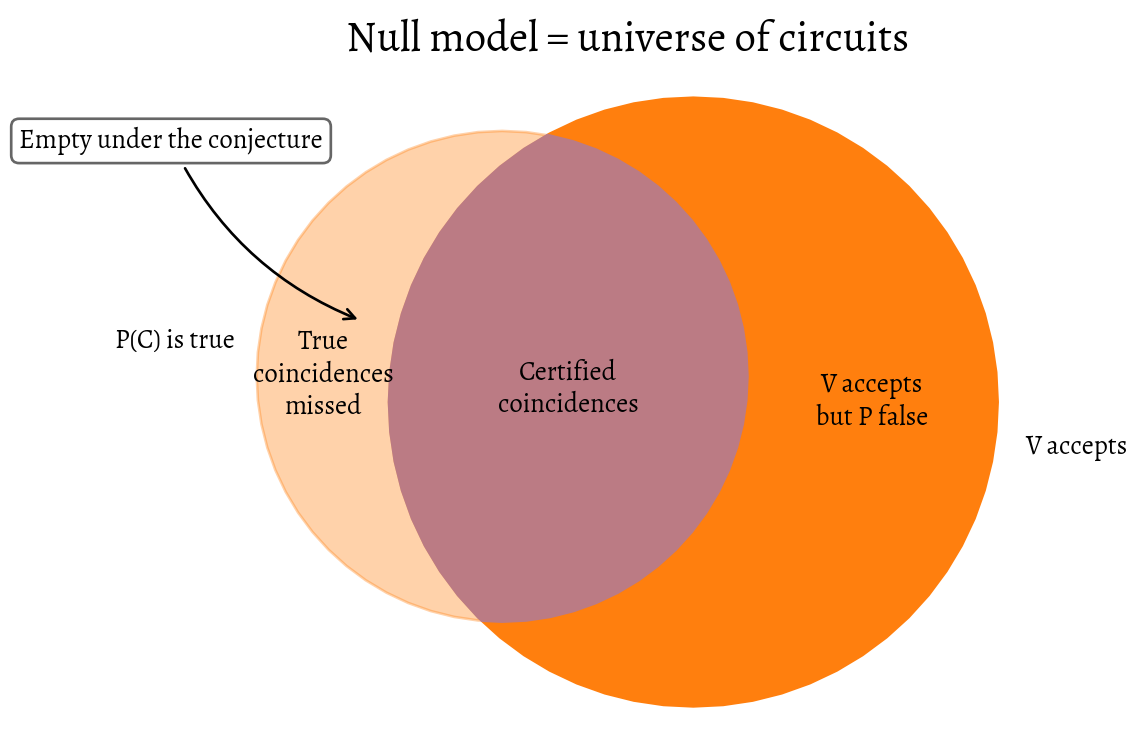
Meanwhile, (a) does the work of “explaining” structure. It says that if we can always find an advice (let’s gloss that as a compact demonstration that the structure is real) for a fixed, outrageously unlikely property \(P\) (and for a fixed \(\Omega\), etc.), then the verifier \(V\), given that advice, has perfect recall (and good specificity) over the set of all random functions. In set diagrams, we claim that the set of functions \(f\) that satisfy \(P(f)\) but for which no proof \(\pi(f)\) will persuade our verifier is empty.
So! A formalization of the conjecture that all coincidences must be explainable.
Code
import matplotlib.pyplot as pltimport matplotlib as mplfrom matplotlib_set_diagrams import EulerDiagramfrom livingthing.matplotlib_style import set_livingthing_style, reset_default_styleset_livingthing_style()P_true_size =0.13V_accepts_size =0.20intersection_size =0.09subset_sizes = { (1, 0): P_true_size - intersection_size, # A only: "10" (0, 1): V_accepts_size - intersection_size,# B only: "01" (1, 1): intersection_size, # A∩B: "11"}subset_labels = { (1, 0): "True\ncoincidences\nmissed", (0, 1): "V accepts\nbut P false", (1, 1): "Certified\ncoincidences",}fig, ax = plt.subplots(figsize=(6, 5))# Try a cost objective that preserves *relative* sizes nicely.diagram = EulerDiagram( subset_sizes, subset_labels=subset_labels, set_labels=["P(C) is true", "V accepts"], cost_function_objective="relative", # good for preserving ordering verbose=False, ax=ax,)for key, text_artist in diagram.subset_label_artists.items(): text_artist.set_color("black")# Highlight the 10 region directlyartist_10 = diagram.subset_artists[(True, False)]artist_10.set_facecolor("tab:orange")artist_10.set_alpha(0.35)artist_10.set_edgecolor("tab:orange")# Use shapely centroid for a precise calloutgeom_10 = diagram.subset_geometries[(True, False)]x, y = geom_10.centroid.x, geom_10.centroid.yax.annotate("Empty under the conjecture", xy=(x, y+0.03), xycoords="data", xytext=(-15, 65), textcoords="offset points", ha="right", bbox=dict( boxstyle="round,pad=0.3", fc="w", ec="0.4"), arrowprops=dict( arrowstyle="->", connectionstyle="arc3,rad=0.2"),)ax.set_title("Null model = universe of circuits")ax.set_axis_off()plt.tight_layout()plt.show()# print(f"savefig.transparent {mpl.rcParams['savefig.transparent']}")# print(f"figure.facecolor {mpl.rcParams['figure.facecolor']}")# print(f"axes.facecolor {mpl.rcParams['axes.facecolor"]}")# print(f"fig patch {fig.get_facecolor(), fig.get_alpha()}")# print(f"ax patch {ax.get_facecolor(), ax.get_alpha()}")# print(f"fig facecolor {fig.get_facecolor()}") # expect rgba with alpha 0# print(f"ax facecolor {ax.get_facecolor()}") # expect alpha 0# (Optional sanity check)# print("Radii:", diagram.radii) # different radii reflect set totals A vs B
We can now see what a “structural” explanation of \(P^{(0)}(f)\) might look like. For instance, suppose there exists an output bit in position \(i > 2n\) — i.e., one of the final \(n\) bits — such that for every input whose last \(n\) bits are all zero, the circuit flips that bit from 0 to 1 on the first layer and never changes it again. This ensures that any input in the \(p^0_{\text{in}}\) set (last \(n\) bits zero) will produce an output where bit \(i\) is fixed to 1, so the output’s last \(n\) bits can never all be zero. In other words, \(P(f)\) holds for a simple, structural reason.
In the CNCP world, this is a kind of case where the “advice” \(\pi(f)\) could be very compact — e.g., “bit \(i\) is constant-1 across the entire \(p^0_{\text{in}}\) domain” — and the verifier \(V\) could check it in polynomial time by evaluating the circuit on just the relevant subset of inputs. The conjecture’s claim, I understand, is that all circuits satisfying \(P\) have some succinct, checkable \(\pi\), not just this toy case.
1.1.1 Actual review abstract
One immediate problem, if we come from the ML world, is that Neyman’s reversible Boolean circuits don’t look like the dominant paradigm for modern learning algorithms. It would be satisfying to have a function space that “looks” like neural networks, but still meets the convenience requirements (1)–(3) that lets us pose formal, probability-based claims about explaining structure. Ideally, we’d have a big bag of random functions that look like NNs — then we could ask computational-no-coincidence-type questions directly in the neural-net domain.
The idea in Dunbar and Aaronson (2025) is simple: a good model for neural networks is neural networks — random ones. There’s a long lineage of work on this, from Neal (1996) to the omnibus Roberts, Yaida, and Hanin (2022). In the standard setup, each weight and bias is drawn independently from a Gaussian with zero mean and suitable variance. This is mathematically tractable and has lots of known limit theorems.
This choice satisfies desideratum (3): the function space maps cleanly onto the objects of interest, because those objects are literally neural nets. It also satisfies desideratum (2) — as width grows, the preactivations approach a Gaussian process, so the underlying measure space is “nice” and the \(\sigma\)-algebra headaches and \(\Omega\)-wrangling are outsourced to the Gaussian-process literature.
The extra work in Dunbar and Aaronson (2025) is aimed at desideratum (1), which is about being able to bound the probability of rare events. Their main theorem identifies conditions under which randomly initialised NNs behave, for the purpose of such probability estimates, like draws from a tractable, product-Gaussian null model. Concretely:
Assume a nonlinear activation \(\sigma\) with zero mean under \(\mathcal N(0,1)\): \(\mathbb{E}_{z\sim\mathcal N(0,1)}[\sigma(z)]=0\).
Use “critical” hyperparameters that keep the per-neuron variance stable layer-to-layer.
Under these conditions, for any fixed layer depth \(\ell\) and width \(m\) large enough, the outputs on different inputs have exponentially decaying covariance in \(\ell\), and the joint law over all neurons and inputs is within \(e^{-\Omega(\ell)}\) total-variation distance of an i.i.d. standard Gaussian. This means the probability of many interesting subsets is easy to compute, because a good approximation to \(\mu\) is easy to work with. This exponential-decay regime is the NN-side analogue of Neyman’s “random permutation” assumption: it gives us a null distribution we can actually compute with.
They then propose a neural-net analogue of \(P(C)\), which they call \(P^{(1)}\), where the input and output predicates are
\(p_{\text{in}}^{(1)}(x)\) is trivial — it holds for all \(x\in D\).
\(p_{\text{out}}^{(1)}(y)\) is “every coordinate of \(y\) is negative.”
In words: every dataset input maps to an all-negative output vector at the chosen layer. Under the product-Gaussian null model, this event is exponentially unlikely in the width. This mirrors Neyman’s “no input with last \(n\) zeros maps to an output with last \(n\) zeros,” which is (doubly) exponentially unlikely under the uniform-permutation heuristic. That rarity, together with the tractable null, makes \(P^{(1)}\) a good candidate for exploring computational-no-coincidence in a neural-network setting.
As with Neyman’s bit-flip example, we can imagine simple structural reasons a network might satisfy \(P^{(1)}\). For instance, suppose there’s a neuron in the chosen output layer whose bias is set to a large negative value, and whose incoming weights are all small enough that its preactivation stays negative for every input in \(\mathcal{D}\). If every output coordinate is built in this way — perhaps via repeated weight/bias motifs in the architecture — then the “all-negative” property holds for a mechanical, easily checkable reason. In CNCP terms, the advice \(\pi\) could specify the index and parameters of these always-negative neurons, and the verifier \(V\) could confirm the property in polynomial time.
Tying it all up with a bow, if we accept that the Computational No-Coincidence Conjecture is a worthy angle of attack for understanding structural properties of networks, then this seems to give us a more comfy, learning-adjacent model to use in it.
1.2 Review
This paper does a lot of hard work to find criteria and conditions under which wide, deep neural networks give us a tractable null distribution for producing Computational No-Coincidence Conjecture results. It supplies one such example plus many useful auxiliary results that would help us produce more. As far as I understand the conjecture, this paper mostly adapts it to neural-network domains, which seems useful for making progress. It is, IMO, clearly written, with some rough edges that I suspect come from the paper sitting at the edge of two fields with strong opinions about terminology; we may not all agree on how rough those edges are.
I have examined the technical results at a surface level, and they seem credible, but errors could have escaped me.
I have questions.
1.2.1 Handling the finite dataset
Do we need to tweak the conjecture, or the random neural network model, to handle the fixed-size dataset? As written, it seems that if \(P^{(1)}\) quantifies only over a finite dataset \(\mathcal{D}\), a verifier could simply forward-propagate every \(x\in \mathcal{D}\) and check the predicate—cost \(O(|D|\cdot T_{\text{fwd}})\), independent of any “structure.” So this is polynomial in the size of the network. Neyman’s verifier doesn’t have this problem, I think, because the input space grows exponentially with the width of the network, so one can’t brute-force the \(2^{2n}\) inputs.
Call the “size” of the network \(|f|=m\ell\) (\(n\ell\) in the notation of the paper). Then do we need something like the following?
Verifier time: \(\operatorname{poly}(|f|)\) and sublinear in \(|\mathcal{D}|\)
Advice size: \(\operatorname{poly}(|f|)\), independent of \(|\mathcal{D}|\).
1.2.2 Can we handle other activations actually?
We need the \(\mathbb{E}_{z\sim\mathcal N(0,1)}[\sigma(z)]=0\) to get decaying covariance between sites in the readout, which naturally suggests \(\operatorname{tanh}\). We could also translate a ReLU or GeLU so it’s centred. Any reason not to do that? I have a sense there might be, because the paper mentions a connection to the complexity-bias of tanh networks, but I don’t see what it is.
1.2.3 Why not just do \(P^{(0)}\) from the Neyman paper?
We can get a very near analogue to Neyman’s original \(P^{(0)}(C)\) by coarsening the neural network at input and readout with a 0–1 step function, and then it’s just a function from bits to bits again. We could set the neural network widths to \(m=3n\) and talk about getting the last-\(n\)-bits-are-zero conditions from Neyman. It’s not exactly the same: we draw the tail bits with replacement rather than sampling permutations, but the analogy would still be closer. What do we get from the outputs-all-negative \(P^{(1)}\)?
1.2.4 Other architectures?
This isn’t really a question for this paper — we want to do one thing at a time — but I’ll ask it anyway: Let’s suppose we wanted to prove things about some other architecture, such as attention-based transformer architectures. Do we have any hope of a nice null model like the one in this paper in that case?
we might want to restrict the input and output spaces to be subsets of these spaces, but let’s stick with that for now — I don’t think the usual restrictions complicate things.↩︎
I don’t think the spaces need to be the same size; generalization is left as an exercise, though↩︎
It’s not exact — the true circuit distribution gives extra weight to highly structured cases like the identity or bitwise NOT — but the authors argue that uniform-permutation heuristic is likely close enough for estimating the tiny probabilities of “outrageous coincidences”.↩︎
They say nothing about the distribution of inputs, but we can imagine a natural extension to inputs sampled from some distribution, so we could make statements about noisy worlds in expectation. Anyway.↩︎
technical condition: no scalar multiples in the dataset↩︎