Wherein the Author Trains a Small Language Model on Paired Samples of His Own Prose Against AI-generated Slop, Finding a Stubborn Detector-Versus-Taste Gap That Persists at Forty Held-Out Paragraphs.
DIY
economics
faster pussycat
language
NLP
premature optimization
slop
stringology
UI
workflow
writing
Figure 1
Claude is a bad ghostwriter for me. Not unintelligible, not slow, not even particularly inaccurate — just wrong in the way LinkedIn posts are wrong: smooth, hedging, structurally signposted, breathlessly enthusiastic in flat places. I have tried the standard ladder of prompt-side fixes: a hand-tuned /dan-voice skill with a banned-words list and a structural slop catalogue, a Vale ruleset as a mechanical safety net, in-context examples of my own prose stuffed into the system prompt as few-shot exemplars, multiple rounds of “rewrite this in Dan’s voice” against a frontier model. The output comes out marginally more Dan-shaped each iteration and still smells like a press release. There is a floor on how much taste we can install via prompt engineering, and currently I am still trapped, according to this excruciating metaphor, in what must logically be the taste basement.
No matter what I do, I cannot dissuade Claude from emitting contextless snide technical nerdview bullshit like mentioning its “Vale rulesets”. Nor can I wean it from poorly chosen mixed metaphors like “standard ladder of prompt-side fixes” or the “floor on how much taste we can install” which, through some lesser-known ladder-floor mechanism, extrude “Dan-shaped” chunks. The text pudding remains, as it were, laced with choke-hazard “dan-shaped” and “load-bearing” tuppences that do not meet modern safety standards.
Look, I do not claim my style is perfect. But I do claim that
it is mine, and
it is low on grating LLM quasi-metaphors like “this is the growing seam we can hand off”, and
when I write something on Monday in my own style, reading it back on Friday, I discern my own intent without excessive strain.
All these are untrue of Claude’s output.
If, if I could train a small specialist model that bakes something like style into weights rather than pleading for it via prompt, every AI draft could pass through it and come out sounding like me, or at least, hopefully not substantially worse despite having been interfered with by an LLM. This would, at least, aggravate me less.
So! We find ourselves in the realm of Fine-tuning danbot!
1 Did you try few-shot prompting?
Of course I did. I tried a lot of few-shot and then many-shot prompting with examples of my prose, and it did not help at all. I do not understand people who say this works for them. Maybe their goals are different? Maybe they have read less AI text than I have?
Anyway, please stop telling me to do few-shot prompting. Of course I tried that first. It was much easier, but futile.
My policy is not to abstain from AI. My policy is, rather, to optimize my productivity given my own time and attention, and to use AI as part of that, wherever it makes sense. What exactly that means is hard to say, but I will more easily find out by doing the experiment. Sometimes it is useful to sketch stuff out with AI, or do background research, or make tedious and complicated edits, or whatever.
It is not useful to pretend that AI is a human, nor specifically that it is me. It does not, however, follow that AI outputs should be horrible to read.
With that in mind, goal statement:
2 Goals
Less onerous clean-up of AI edits.
More comprehensible prose in general
3 Non-goals
Full Dan impersonation
Evading slop detectors
4 tl;dr
It works! Ish! If we read to the end of this, we will find all the stupid steps for how to make a fake dan-in-a-box. Danbot works, in the narrow sense that it functions, but the quality is not satisfying. I documented my labours in a working project that you can try, and I have experimented with running irritating AI slop through it.
Metrics: across forty held-out validation samples, the styler closes about half the gap, on every metric I have, between me and slop. So it is quantifiably superior to prompting the model. It is doing something.
Qualitatively, it seems to me to be perversely good at a non-goal. It can make AI sound less like AI, but it is not yet good at making AI sound like me. I had assumed the second was the easier task because it is more specific.
Also, I made some regrettable design choices. Notably, right now it works at the scale of a paragraph rather than a section, which I suspect is why the rewrites are not super coherent.
The code consists of two parts. “Stuff that you might want to use” and “inside-baseball nonsense that only I will find useful”. danmackinlay/stylebot is the former. It should be relatively generic. Includes: prose extraction, chunk hygiene, pair synthesis, training, eval scoring. I am aware that none of those words make sense without context. Let me try again: It includes generic dataset generation and training tools.
The other, me-specific part of the code lives in this blog and specializes in various idiosyncratic design choices I made for it, filtering out the more hair-raisingly incoherent posts from the training data, etc.
This divide seems to be a natural separation of responsibilities. If you disagree, file a pull request.
The training corpus was seeded with a bunch of rewrites I made to actual AI slop (~400), giving me (before/AI, after/Dan) pairs. I then synthesized a bunch more by creating synthetic “reverse-edits” (~4500).For each of these, I take a paragraph of my published prose and ask an LLM to do its best to improve it, giving me (before/Dan, after/AI) pairs, which I can swap into (after/AI, before/Dan) pairs. Genius! Infinite data! The captured pairs accumulate as a side effect of ordinary editing, and I generate the others from time to time.
There is a bit of fancy footwork around test/training splits. I split the data over posts rather than paragraphs, so that if there are many edits from one page, we do not leak shared topic information across splits. There are three splits: validation, LLM training, and detector training.
Oh right, the detector. I didn’t mention that but it ended up being very useful. The detector classifies paragraphs as being more AI or more Dan. It emits P(slop) per paragraph. It runs locally (embedding models are cheap), which is super convenient: everything downstream can afford to call it profligately. This also gives me a (noisy) way of measuring the output.
“Training” is specifically supervised fine-tuning of a LoRA on Tinker. Currently the base model is Qwen3.5-9B with thinking disabled, which costs about $2 per (training) run. Each run writes a manifest with all the metadata about how I made this training corpus — split, hyperparameters, all that nonsense. I maintain several fine-tunes and “promote” a favoured one from time to time. It is not always the latest one — occasionally more recent ones suck.
Document chunking is a little bit complicated on this blog. I fill the text with code, mathematical markup, etc. So there is a custom text extractor and chunker that I use for data generation, training, and inference.
At inference time (i.e. when I want to rewrite a paragraph), I run the chunker, and then for each chunk I sample four candidate rewrites. I filter out any defective candidates that have deleted or mangled URLs. Any that remain are ranked by how much the detector liked them (or at least, how much the detector thought they resembled me, which might in fact be exquisite torture for the poor detector, idk). The original text is included in the alternatives in case all the candidate rewrites totally suck.
All this is wrapped up in a small VS Code extension that
tints each paragraph with a colour denoting P(slop) and
offers to rewrite the paragraph under the cursor.
Whichever I pick — including “keep what I had” — is logged as a preference record so I can improve future iterations, RLHF-style.
5.1 Where to train and serve
This is so out of order. I explained how I use the model, but not how I train it. I train on Tinker and, by default, sample from Tinker too.
Tinker is Thinking Machines’ managed-training API: I write the idiosyncratic parts of my training loop in Python, and they wrap it in an ingenious training pipeline on fast hardware. Tinker is super easy! Instead of just giving me a train() loop, it exposes forward_backward, optim_step, and sample as primitives, which gets me a long way toward a custom training loop without having to manage the hardware — which, TBH, I am not qualified to do and would totally have blown the time budget appropriate for this part-time papermill-tilting. I don’t need the advanced features for the vanilla SFT, but it is nice to know I can do preference fine-tuning via DPO later.
Also, they will serve the model for me afterwards, which is convenient. Sampling is billed per-token, with no deployment to forget about and no idle cost, which suits a model I invoke a few dozen times a week.
Other alternatives: Together trains a LoRA cheaply and makes it easy to extract, but hosts a fine-tune only as a dedicated always-on endpoint, which prices a rarely-run model out of existence.1 Although if there were massive demand for constantly-available danbot, that would be hilarious and I would consider it.
When I want my fine-tuned model off the cloud entirely, the adapter merges into the base model, quantizes to 4-bit MLX, and then (seemingly) serves fine locally.
6 Measuring dan-ness
As presaged, everything is easier if I can get some kind of signal of whether text sounds like me or not. Even a weak signal helps, because this is neural network land and we are used to sifting information from noisy signals. I settled on four imperfect signals, but hopefully differently imperfect, like a buddy-cop film’s dramatic leads.
Vale, a prose linter, catches mechanical slop — banned words, colon headings, and other grammar choices (“load-bearing”, etc.)
a few-shot LLM judge assesses whether the output resembles other things I have written on a 1–5 scale (“here are some samples of Dan’s writing, rate this new example on a 1–5 scale for how much it resembles Dan’s style”)
that trained detector I mentioned earlier estimates P(slop) directly
I eyeball the output myself
An obvious fifth option is a general-purpose AI-text detector, but a moment of introspection reveals that to be a dumb idea.2 Recall that evading slop-detection is a non-goal, so it is not a helpful signal for that. In any case, a lot of things are not slop but also not Dan:
In the beginning was the Word, and the Word was with God, and the Word was God.
I promise you that I did not write that.
The trained statistical classifier is more interesting, because it is a signal that is more about me than about humans in general. Nitty-gritty: It is a logistic head over an embedding of the (slop, Dan) pairs I already have, which was made easy by using a good one. I am familiar with content embedders, and use those all the time. Such semantic embedders do capture style a little (Icard et al. 2025), but it is not their strong suit. Style embeddings are their own literature (Wegmann, Schraagen, and Nguyen 2022) and they do way better. StyleDistance (Patel et al. 2025) is one of those, trained on a synthetic corpus generated in a way very reminiscent of this blog, which suggested it might transfer here. It does. A logistic head on StyleDistance beat every other embedder I auditioned, thoroughly enough that I have not bothered fine-tuning my own style encoder. cf. LUAR (Rivera-Soto et al. 2021), which attempts authorship classification rather than style. These might also work as generic slop detectors, FWIW — Soto et al. (2024) show that style vectors separate machine text from human text few-shot.
That P(slop) is super useful. The pipeline uses it for ranking, QA, and hints in the editor.
6.1 Judge versus classifier
Having both a classifier and an LLM judge invites the question of whether they measure the same thing. On a stratified subset of 180 pairs scored by both, the rank correlation between them is 0.09. Which is to say, near enough to independent. Which is to say, when we think about it, if one is perfect then the other is defective. In fact, both of them are defective, but in different ways, which is kinda what we want.
The judge is surprisingly decisive in absolute terms — it scores my prose 4.2 out of 5 on average against the slop’s 2.2 (which is incredible actually, I’m glad I let Claude talk me into trying that out). Whereas the trained detector is pretty rubbish in absolute terms, but way better at relative ranking. In a (dan, slop) pair, the slop is ranked sloppier. The few-shot judge sucks at this: within pairs it seems to mostly measure how much of the original text survives the rewrite. The classifier is nearly orthogonal to that (\(-0.08\)), which makes it a better instrument for the question of whether a transformation itself is sloppy.
Neither dominates, so in practice I use both.
Code
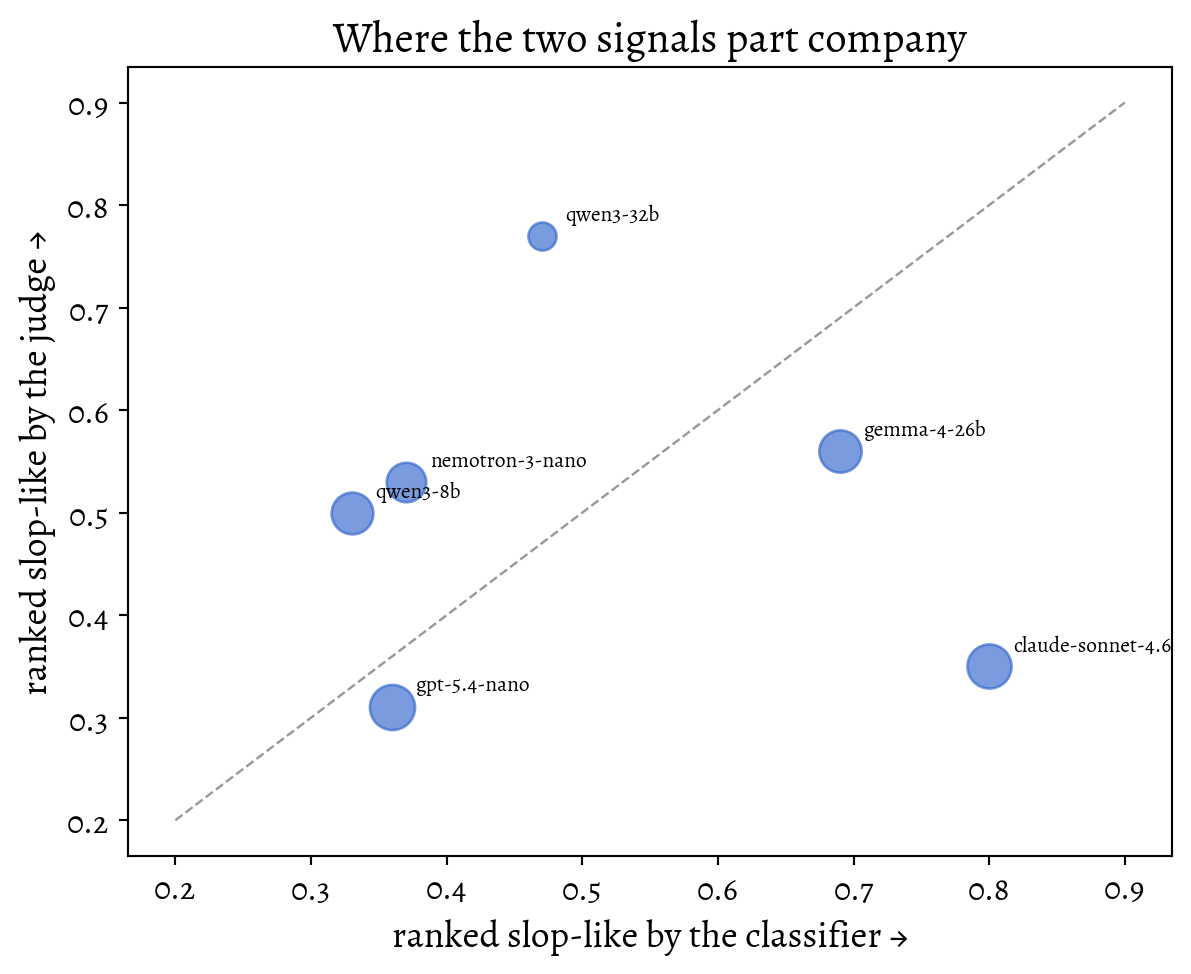
import matplotlib.pyplot as pltfrom livingthing.matplotlib_style import set_livingthing_style, reset_default_styleset_livingthing_style()SIGNALS = [ # model, classifier rank, judge rank, fraction of my text surviving ("gemma-4-26b", 0.69, 0.56, 0.66), ("qwen3-32b", 0.47, 0.77, 0.22), ("claude-sonnet-4.6", 0.80, 0.35, 0.73), ("nemotron-3-nano", 0.37, 0.53, 0.56), ("qwen3-8b", 0.33, 0.50, 0.64), ("gpt-5.4-nano", 0.36, 0.31, 0.77),]fig, ax = plt.subplots(figsize=(6.4, 5.2))ax.plot([0.2, 0.9], [0.2, 0.9], "--", color="#999", lw=0.9)for name, det, judge, copied in SIGNALS: ax.scatter(det, judge, s=40+ copied *320, alpha=0.65, color="#36c") ax.annotate(name, (det, judge), textcoords="offset points", xytext=(9, 6), fontsize=8)ax.set_xlabel("ranked slop-like by the classifier →")ax.set_ylabel("ranked slop-like by the judge →")ax.set_title("Where the two signals part company")fig.tight_layout()plt.show()reset_default_style()
Six slop sources ranked by each signal, on 180 pairs scored by both. Points off the diagonal are models the two instruments disagree about; marker area is how much of my original text survived the rewrite.
Since each model emphasizes different aspects of the text (e.g. Claude Sonnet rewrites politely and preserves most of my original wording, while qwen3-32b condenses aggressively and changes the register), I add them together with a bit of scaling. I also eyeballed the pairs where they have the greatest discrepancy to make sure it is sane, which it is not always.
About 19% of the synthetic pairs were “rewritten” to be 85% the same. These seem to be not super useful for training a detector, so I mark those and make sure they are not used for that. They stay in the styling model dataset, though, where they teach it to leave alone the prose that is already fine.
7 Whose slop?
I have about 1.6M words of prose on this site that I wrote with my own hands, and the few AI-heavy ones are marked, so the target side of the corpus comes free. The source side is the design problem: whose slop do we train against?
Slop seems to come in two layers. There’s a deep humus under-layer — throat-clearing, “it’s worth noting”, the rule-of-three, “It’s not X; it’s Y”, signposting, marking key phrases in bold. It seems to me that every RLHF’d model produces that. Atop this layer is the litter of model-specific tics: GPT’s “delve” and “tapestry”, Claude’s peculiar hedging cadence, and so on. Attar et al. (2026) study 284 interpretable linguistic features across 27 LLMs and 10 text domains, and argue that most signals are model- or domain-specific. This suggests multi-source training might be the way to go in order to learn to undo them all.
Even though I use Claude a lot, this makes sense. Even Claude isn’t one thing, but rather a family of models and versions, and I use others besides. Let us understand the goal for this styler to be a Dan-ifier rather than a de-Claude-ifier: rewrite the input as I’d write it, whatever the source. Soto, Chen, and Andrews (2025) argues that this is in fact a smart move, as mimicking a specific human author’s style is a strong method for removing obvious AI tics.
There is also the matter of the base model I will use to do the styling. I am training a small open-source model, and Antoun, Sagot, and Seddah (2023) argue that small open models have the strongest stylistic signatures — so some of the slop had better come from my own utility base-model so that I don’t rewrite Claude prose into Qwen prose instead of Dan prose.
tl;dr We generate training slop from a plural set of LLMs.
There is at least one example of this in the wild. Paneru (2026) build a 25,140-pair AI→human corpus and fine-tune BART and Mistral-7B on it, reasoning that using two generators rather than one reduces the risk of learning to undo one model’s idiosyncratic habits instead of AI-style writing more broadly. They also target multiple human-target domains for the same reason, which I can’t be bothered doing, so I hope that part is not important. They don’t run a single-source vs. multi-source ablation, so the value of this multiple-model approach is unknown. Maybe I can publish that ablation if I find time? Paneru (2026) also observe some interesting failure modes — for example, we can learn the correct style transform but overcorrect, which looks great on metrics but probably not on human inspection.
That said, maybe we’re ready for ULTRADAN?
8 The deletion problem
I am usually less wordy than the AI, so part of what the styler learns is “delete stuff”.
An early run was great at sounding like me, but also deleting “boring stuff” like URLs and citations. I purged the data set of any pairs where the length ratio between AI and me was less than 3:1, and that helped, but there was some dataset fine-tuning needed to get there.
This is likely a hazard of style-transfer objectives rather than a defect in any particular run: the cheapest way to sound less verbose is just to delete stuff. Can I separate this in a more principled way? TBD.
At the moment I handle this with sanity checks at inference time. Any sample that drops a link, URL or citation key present in the input is disqualified. This works fine.
It works fine in one direction, anyway. Counting anchors across the whole corpus turned up the opposite problem, and a larger one: in 19% of pairs the target carries links the source does not, about half of them external URLs. The mechanism is the reverse-edit swap. When a generator drops one of my links while “improving” a paragraph, flipping the pair around produces a training example that reads given text without links, produce text with these links, which is a lesson in fabricating URLs. The disqualification check never sees it, since it only looks for anchors that went missing. Written up as stylebot#1.
9 Lessons
Data hygiene was most of the work. The dramatic failures were all data failures: one generator returning my paragraphs near-verbatim, another inflating them 4-7x, which probably teaches too-extreme compression. It is worth cross-checking this by looking at the actual data. Some of the models did bonkers weird stuff.
To make sure I can control for these issues and future systematic errors, I record all the generation parameters, and also some sanity-check metrics (copy-similarity, length ratio). Any combinations that I later discover to be defective I can then delete. Since setting that up, I have had to cull two more model combinations.
Be careful with temperature. Low-temperature model sampling was useless for synthetic data generation: the model just copies the input, which is not what I want. High temperatures are also useful for sampling at inference time — I use 0.7. Low temperatures are useful though for judging, so I set that to 0.3.
The boring parts cost the most. A full working day went to harmonising local LLM serving and remote, and dealing with bugs in how the model configs were handled. All of it is now baked into the export script, though, so we don’t need to worry about it.
10 What next
Longer rewrites. Paragraph-by-paragraph restyling reads slightly disjointed across paragraph boundaries, and 1500 characters (current limit) should probably be tripled. Unfortunately I did not set up the training runs to do that, taking Claude’s spuriously confident advice to do it at the paragraph scale. Fed ~5000 characters, far past the 1500-character training scale, the adapter returns it unchanged—the model only rewrites short things. Not disastrous, but a waste of compute.
That mistake is baked into my old data. The new infrastructure archives the full before and after texts so I can re-chunk in the future. Watch this space.
I am aesthetically interested in preference tuning next. For one thing, Tinker supports it. For another, I have a lot of preference data: every time I accept or reject a rewrite in the editor, that is a preference signal that I could plug into DPO-style loops. My picks are strictly better labels than the detector’s picks, and I get these for free.
I think I maybe want to mask out URLs and citations in the training and inference, so they do not interfere with the style transfer. Block markup is already excluded, but inline markup is 22% of the characters in the target side of my corpus, so a fifth of what the styler is trained to emit carries no style at all. Masking the payload and keeping the anchor text looks like the move, though the counting exercise suggests I should fix the data before I build any machinery.
And I’m curious if I can do the styling by steering vectors rather than by fine-tuning.
11 Appendix: You see the problem?
Why am I doing this? Because I recently had the following conversation with Claude:
USER: This document is crammed with overwrought, rambling, almost schizophrenically-dense, confusing prose. I need you to help me tidy it up. I will show you one example of how the text started out (“original”) and how I tidied it up (“tidied”)
original:
The one thing maths rewards that ordinary agentic work does not is what makes the cloud earn its keep. A single solve is irreducibly sequential — each code block depends on the last, and no hardware shortens that chain. The parallelism is across samples and problems: the maj@k draws are independent, a problem set’s entries are independent, and a prover’s Pass@32 is thirty-two independent chains. That is the axis to fan out along, and the binding constraint is almost never the GPU. The three parts parallelize unevenly: the model server already batches many chains against one card (vLLM, SGLang), the orchestrator is just \(k\) async loops, and the laggard is the executor — a hand-rolled loop holds one kernel, a bare lean-repl compiles one proof at a time. So the question a workflow answers is not “how big a GPU” but “how do we run many executors cheaply”.
tidied:
One weird trick to make provers go better is to sample several independent attempts at solving the same problem, and choose the most popular solution. This is the so called maj@k-trick. Provers have an equivalent one, called Pass@k. Either way you can run a lot of these fuckers at once. The LLM tokens are delivered over the network and as such are parallel. So our agentic loop handles \(k\) conversations with the model. The executors may as well be run in parallel too, ideally on \(k\) different machines running whatever tool is needed for that chain.
Do you see what I mean? The first one was full of baffling unclarity, introducing things in needlessly complicated, even incoherent, ways. Ultimately, after reading it I felt much stupider than before. The second version omits needless bullshit and communicates, in context, what the reader needs to understand. Do you think you can go through the notebook section-by-section and edit each bit so it sound less batshit raving insane? This is a long document, and you do have a tendency for, let us say, prolixity, so, don’t worry about matching my voice or whatever right now, forget all that shit. Just do your best to turn this ululating turd-burger into something humans can read in order to become elucidated thereby. Delete info that doesn’t help them. Drop useless crap. Don’t forget they can look up things in the attached git repo. Here is not a time for falling in the info latrine while info dumping. Rather, it is a time to stop, take a breath, and consider what we need to say.
Do you think you can do that?
The answer was ofc that Claude thought he could do that. Oh Claude. He tried. He maybe made it one paragraph before the rising tide of slop claimed him.
12 Appendix: What I have not tested
That was a lot. But there was a lot that I did not do. The three training runs I did were unsophisticated, cheap runs, differing only in training data. I left the params on sane defaults: LoRA rank 32, one epoch, batch size 64, linear schedule, seed 0, identical across all three, with Tinker cookbook defaults and no ablations.
So, various tweaks and experiments suggest themselves:
How much does data quality matter, against quantity? About 330 captured pairs against 4,200 synthetic ones. Was one of those better than the other? Which helped more?
Does multi-source slop actually help? This is the ablation Paneru (2026) did not run, and neither have I.
Is Qwen3.5-9B the right base? It was chosen for serving convenience; I never compared against anything.
Do the LoRA parameters matter, and is LoRA even the right vehicle? Rank 32 was just some arbitrary number. Style might be diffuse enough across the weights to warrant a full fine-tune, or shallow enough that a far smaller rank would do, and I have no evidence in either direction.
At $2 a run, these are affordable experiments to try.
Policy on this blog is that slop should be disclosed, not concealed — see the three robots marker at the top of this post? That means it is slop af, starting… now. All the appendices are unreconstructed machine-generated notes with minimal proof-reading.
13 Appendix: Steering vectors
Fine-tuning is not the only way to get style into a model. Activation steering leaves the weights alone and adds a vector to the residual stream partway through the forward pass, which biases everything sampled downstream of that point. Constructing the vector is embarrassingly cheap: run a set of contrasting texts through the model, record the hidden activations, take the difference of the means. That is Contrastive Activation Addition (Panickssery et al. 2024), and near enough ActAdd (Turner et al. 2024), both under the representation engineering umbrella (Zou et al. 2025).
My corpus is already a contrastive pair corpus. Every entry in it, synthetic or captured, is a (slop, Dan) couple matched by construction on content and differing in style — exactly the right input format. The whole “training” procedure is two forward passes per pair and a subtraction. No Tinker run, no $2, no manifest, no hyperparameters left on defaults for me to feel anxious about later.
Someone has already done the style-specific version. Konen et al. (2024) compute style vectors from recorded layer activations of texts in a target style, with no training machinery at all, and steer sentiment and writing style with them. Diallo et al. (2025) then ran that past human raters — 7,000 ratings from 190 people — and found that moderate steering coefficients (\(\lambda \approx 0.15\)) amplify the target style while leaving the text comprehensible, with quality degrading past that. They also report automated quality scores tracking the human ones at a mean \(r=0.78\), though with a spread from \(0.16\) to \(0.99\) that I would not lean on hard. Good news, though, for a pipeline that already ranks candidate rewrites with a local classifier.
A style slider is the juicy feature I lust after. \(\lambda\) is a continuous coefficient, so I can sweep between ULTRADAN and a-light-touch-of-Dan with the touch of a slider. A rant can take a heavy dose; a section explaining someone else’s theorem should take almost none. Unless the author was mean to me.
Bonus: a steering vector has no text-length constraint, so I can forget about that irritating training chunking. The paragraph-scale mistake I made would simply not arise, or at least, not require me to torch a month’s worth of data curation.
Implementation seems mechanical. Steering needs hooks into the forward pass, so I lose Tinker, which is a sampling API rather than a steering one. As such, this is primarily a local-weights technique, or, if not, needs a custom cloud endpoint. I still cannot apply this to Claude, since Claude’s activations are not available to anyone outside Anthropic.
Inference would look different. I would not have biased the model to be a rewriter. Steering tilts the distribution the model samples from, but I still need to set up the prompt to “restyle this”.
Whether it works on something as diffuse as “sounds like Dan” is unclear. Tan et al. (2025) find that steerability varies a lot across inputs and can be brittle at deploy time. My inputs are heterogeneous and suspiciously sundry — code fences, maths, citation keys, a paragraph about NTFS case sensitivity, a paragraph about phallic fungi. The mapping that captures my style across all of these may not exist.
On the third hand, I already built the measurement and evaluation infra for testing such a thing. The training pairs exist, the splits exist, the detector and the judge exist, and there is a held-out set of forty samples to test against my LoRA baseline already scored on it. So the experiment is a sweep over layer and \(\lambda\) and a bit of a gander. Also, maybe it composes with the LoRA. Are you ready for ULTRAULTRADAN?
14 Appendix: Choosing the detector
I ran a logistic regression using each embedder as a feature extractor, scored on pairs held out by source document. StyleDistance won, at 0.78 pairwise accuracy and 0.72 AUC, ahead of LUAR (rrivera1849/LUAR-MUD, 0.76 / 0.71), Wegmann’s CISR (AnnaWegmann/Style-Embedding, 0.73 / 0.67), and the semantic embedder baseline (0.75 / 0.62). Interestingly the semantic embedder is not so terrible at pairwise accuracy, but it mildly fails to generalize, getting a poor AUC. I’m amazed how well it does actually; I thought it would memorize my favourite topic areas and ignore style, but no.
15 Appendix: What did not work
The synthetic data generation was a whole mini problem in itself with more design variables than I could bother myself to explore. My hope is that the model is relatively robust to the details of how the synthetic pairs are generated, so I plan to spend little effort on that. Let’s see.
15.1 Generators that misbehaved
Three models have left the slop roster, for two failure modes.
The older Qwen models were weird (“feral”, according to Claude, who can get bitchy about Chinese open-weight models). qwen3-8b (reasoning off) returned my paragraphs near-verbatim: 386 identity pairs at a median similarity of 0.98, which might be believable if any of the other models had done the same.
qwen3-32b failed the opposite way, inflating its output to 4.4–6.8× the target length while also ignoring reasoning: {enabled: false}. Overall, this was triple the average cost and of low quality. It went as far as 33× on one paragraph in all kinds of weird ways. Here is a fun example. Three lines of mine:
15.2 Whisper
Whisper [@Radford2022Robust] is the recent speech transcription model casually released by OpenAI:
Requires a GPU but otherwise free. Has now been integrated into lotsa things.
came back as this:
15.3 Whisper
Hey there—gotta give it up for Whisper [@Radford2022Robust], the speech-to-text AI that’s hilarious and hella useful in the same breath. OpenAI dropped it (like a casual “oh hey, here’s a speech model that can almost understand actual humans”) and everyone just… cannonballed into it.
The basics here:
Requires a GPU? Check. (Ach, fine—we’re all on the same team.)
Totally free? Check. (They just hand it out like candy at a privacy-averse AI circus.)
Integrated into literally everything? Check.
So if you:
Need to transcribe audio faster than you can say “final edits”?
Or want to invent a new layer of accessibility tools?
Or just want to sound like an eavesdropper who’s secretly understands everything in that chaotic meeting—
Then Whisper is your MVP. Time to GPU into it and pretend like you’ve been doing speech processing all along. 🎧✨
Pairs like that seem likely to teach manic deletion, the same over-compression that run 1 exhibited.
To mitigate the risks, I purged those models from the corpus. Mitigations against future fuckery: now I reject samples with a copy-similarity of \(>0.95\), and a length ratio of \(>3\times\) of the original length. Most of the generators run around \(1.0-1.2\times\) longer.
Diagnosing that issue uncovered that nemotron-3-nano was also overinflating text, so I dropped that one too. Its inflation came with unusually psychedelic hallucinations. Here it is, padding two sentences about NTFS into eight, complete with a code block I never wrote, in which the registry key is partly in Chinese and the fsutil command sets 8.3 filename behaviour rather than case sensitivity:
On Windows, the NTFS file system can actually be case‑sensitive — a feature that’s tucked away but totally usable. Here’s the fast‑track way to flip the switch: just fire up PowerShell and enable the toggle that makes folders (and files!) care about upper‑ vs. lower‑case.
# Enable case‑sensitive NTFS behaviorfsutil behavior set disable8dot3 1# Or, if you prefer the newer method:# Set-ItemProperty -Path 'HKLM:\SYSTEM\CurrentControlSet\Control\FileSystem' -Name ' NTFS案例敏感感应' -Value 1
So go ahead and give NTFS its “case‑aware” moment — your scripts will thank you! 🚀
Inflation is not only verbosity. Given license to pad, the model will pad its output with wildly inventive, fact-free riffs.
To be conservative about this, I restricted the synth pair roster to include only sonnet-4.6, qwen3.5-9b, qwen3.6-35b, gemma-4-26b, llama-3.3-70b and deepseek-v3, each auditioned on a few dozen scratch pairs for transform-similarity and length ratio before being allowed anywhere near the corpus.
15.4 Surprisingly irrelevant design variables
Two design variables in the synthetic-slop sweep looked like they should matter, and did not.
I suspected, from the literature, that both sheer input length (Levy, Jacoby, and Goldberg 2024) and accumulated conversation turns (Laban et al. 2025) degrade AI output. The worst of the flaws, it seems, may affect an LLM already gravid with context. So the generator also produces text in ever more complex sessions and tracks their context fullness: 1241 pairs across six models, sessions up to 32 turns, prompt contexts from 135 to about 32,000 tokens, each pair tagged with the token count at start.
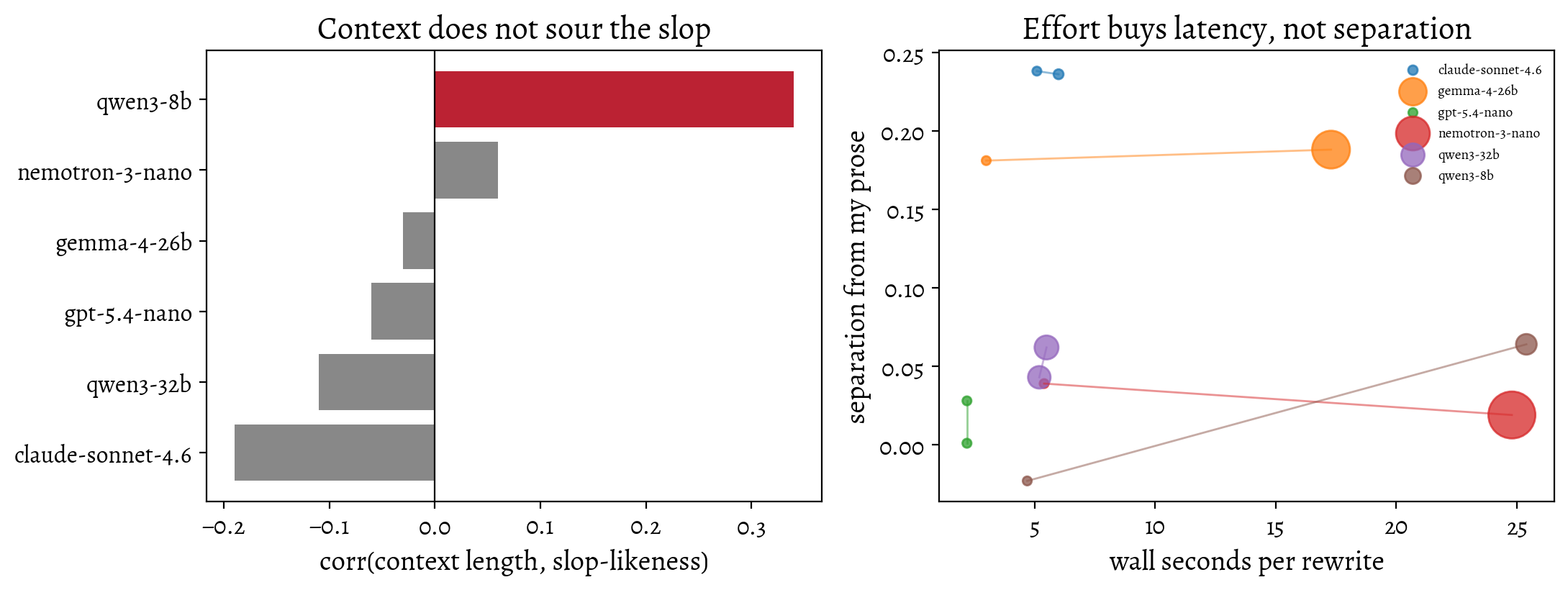
At least for this test, it seems not to matter. Correlating context length against how slop-like the output is — scored with the classifier above — gives \(r = -0.05\) across the sweep. Per model it wanders between \(-0.19\) and \(+0.06\), which is noise, with one exception: qwen3-8b at \(+0.34\), which does get more slop-like as its context fills. But beware — this is multiple hypothesis testing, so we should not read too much into it. I haven’t definitively refuted the influence of slop upon the model, but testing with long context windows is inconvenient and expensive, so I would want stronger evidence that it was worth the trouble. In the absence of definitive evidence of the strong effect reported by Levy, Jacoby, and Goldberg (2024) and Laban et al. (2025), I gave up. Homework: The measurement was not super strenuous. The big-window models never got past about 7% of their context window even at turn 32, so we never got to the point where the model was actually context-full.
Reasoning effort also made little difference. I was open to the hypothesis that a model thinking harder might produce more characteristic slop. Meh. Reasoning turned off entirely gives the same classifier separation as medium effort — 0.09 either way — in a third of the wall-clock time. Gemma and Nemotron spend two to three thousand reasoning tokens per rewrite to arrive at prose no more slop-like than what they produce without thinking at all.3
The good news is that short context windows and low reasoning effort are cheaper regimes in which to generate my synthetic data. I kept the high-reasoning, high-context runs around for curiosity’s sake in the training corpus, since they seem statistically indistinguishable.
Code
import matplotlib.pyplot as pltfrom livingthing.matplotlib_style import set_livingthing_style, reset_default_styleset_livingthing_style()# Aggregates from a 1241-pair sweep; per-pair data not carried along with the post.DRIFT = [ # model, corr(context tokens, P(slop)) ("claude-sonnet-4.6", -0.19), ("qwen3-32b", -0.11), ("gpt-5.4-nano", -0.06), ("gemma-4-26b", -0.03), ("nemotron-3-nano", 0.06), ("qwen3-8b", 0.34),]EFFORT = [ # model, effort, detector gap (slop - me), wall seconds, reasoning tokens ("claude-sonnet-4.6", "off", 0.238, 5.1, 0), ("claude-sonnet-4.6", "medium", 0.236, 6.0, 28), ("gemma-4-26b", "off", 0.181, 3.0, 0), ("gemma-4-26b", "medium", 0.188, 17.3, 2026), ("nemotron-3-nano", "off", 0.039, 5.4, 0), ("nemotron-3-nano", "medium", 0.019, 24.8, 3192), ("gpt-5.4-nano", "off", 0.028, 2.2, 0), ("gpt-5.4-nano", "medium", 0.001, 2.2, 2), ("qwen3-32b", "off", 0.062, 5.5, 740), ("qwen3-32b", "medium", 0.043, 5.2, 643), ("qwen3-8b", "off", -0.023, 4.7, 0), ("qwen3-8b", "medium", 0.064, 25.4, 520),]fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(11, 4.2))names = [m for m, _ in DRIFT]vals = [v for _, v in DRIFT]ax1.barh(names, vals, color=["#888"] *5+ ["#b23"])ax1.axvline(0, color="k", lw=0.8)ax1.set_xlabel("corr(context length, slop-likeness)")ax1.set_title("Context does not sour the slop")models =sorted({m for m, *_ in EFFORT})cmap = plt.get_cmap("tab10")for i, m inenumerate(models): pts = [r for r in EFFORT if r[0] == m] xs = [r[3] for r in pts] ys = [r[2] for r in pts] ax2.plot(xs, ys, "-", color=cmap(i), alpha=0.5, lw=1) ax2.scatter(xs, ys, s=[20+ r[4] /6for r in pts], color=cmap(i), label=m, alpha=0.75)ax2.set_xlabel("wall seconds per rewrite")ax2.set_ylabel("separation from my prose")ax2.set_title("Effort buys latency, not separation")ax2.legend(fontsize=7, frameon=False, loc="upper right")fig.tight_layout()plt.show()reset_default_style()
Two knobs that turned out not to matter much. Left: correlation between raw context length and slop-likeness, per model — noise, except qwen3-8b. Right: reasoning effort moves each model rightwards (slower, bubble area = reasoning tokens spent) without moving it upwards (better separation from my prose).
16 Appendix: Wiring a logger into VS Code
Typing uv run ai-style log open notebook/foo.qmd over and over creates friction, and VS Code already knows which file is focused. Its task system substitutes ${relativeFile} into a shell command at run time, so a handful of tasks in .vscode/tasks.json wrap the logger subcommands, and Cmd+K chords fire them: O for open, S for save, I for interim, D for drop, L for list. Cmd+K is already VS Code’s chord prefix, so none of it collides with single-key editing shortcuts. The workflow becomes: edit a draft, Cmd+K Cmd+O to begin a session, edit more, Cmd+K Cmd+S to save and close. No copying paths, no terminal context switch.
Most of this has since been absorbed into the voice-marker extension, which does the same job through commands rather than tasks, and also handles the paragraph tinting and the rewrite picker. The tasks still work, and the JSON is in the repo for anyone who wants the logger without the extension.
Rivera-Soto, Miano, Ordonez, et al. 2021. “Learning Universal Authorship Representations.” In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing.