Advice to pivot into AI Safety is likely miscalibrated
Aligning our advice about aligning AI
2025-09-28 — 2025-11-01
Wherein the AI‑safety Career‑advice Ecosystem Is Described, Its High Failure Tolerance and Its Lack of Mooring to Ground-Truth or Optimality Is Noted.
AI safety
catastrophe
economics
faster pussycat
incentive mechanisms
innovation
institutions
machine learning
networks
wonk
Assumed audience:
Mid career technical researchers considering moving into AI Safety research, career advisors in the EA/AI Safety space, AI Safety employers and grantmakers
Cross-posted to the EA Forum.
I made a serious mathematical error here when generalizing the model to multiple applicants and multiple jobs. Use with caution.

Here’s a napkin model of the AI Safety career-advice economy—or rather, three models of increasing complexity. They show how advice can sincerely recommend gambles that mostly fail, and why—without better data—we can’t tell whether that failure rate is healthy (leading to impact at low cost) or wasteful (potentially destroying happiness and even impact). In other words, it’s hard to know whether our altruism is “effective”.
In AI Safety in particular, there’s an extra credibility risk idiosyncratic to this system. AI Safety is, loosely speaking, about managing the risk of badly aligned mechanisms producing perverse outcomes. As such, it’s particularly incumbent on our field to avoid mechanisms that are badly aligned and produce perverse outcomes; otherwise we aren’t taking our own risk model seriously.
To keep things simple, we ignore as many complexities as possible.
- We evaluate decisions in terms of causal impact, which we assume we can price in donation-equivalent dollars. This is a public good.
- Individual private goods are the candidate’s own gains and losses. We assume the candidate’s job satisfaction and remuneration (i.e. personal utility) can be costed in dollars.
1 Part A—Private career pivot decision
An uncertain career pivot is a gamble, so we model it like other gambles.
NoteMeet Alice
Alice is a senior software engineer in her mid-30s, making her a mid-career professional. She has been donating roughly 10% of her income to effective charities and now wonders whether to switch lanes entirely to achieve impact via technical AI safety work in one of those AI Safety jobs she’s seen advertised She has saved six months of runway funds to explore AI-safety roles — research engineering, governance, or technical coordination. Each month out of work costs her foregone income and reduced career prospects. Her question is simple: Is this pivot worth the costs?
To build the model, Alice needs to estimate four things:
1.1 Modeling the Sabbatical gamble
1.1.1 Upside
Annual Surplus (\(\Delta u\)): This is the key number: the difference in Alice’s total annual utility between the new AI safety role (\(u_1\)) and her current baseline (\(u_0\)). The surplus combines changes in her salary and in her impact—indirectly via donations and directly via her AI safety work.
- \(u = w + \alpha(i+d)\), where \(w\) is her wage, \(i\) is impact, \(d\) is donations, and \(\alpha\) is Alice’s weighting of impact versus consumption.
- \(\Delta u := u_1 - u_0\).
1.1.2 Downside
- Runway (\(\ell\)): The maximum time she’s willing to try, measured in years.
- Burn Rate (\(c\)): This is Alice’s net opportunity cost per year while on sabbatical (e.g., foregone pay, depleted savings), measured in k$/year.
1.1.3 Odds
- Application Rate (\(u_1\)): The number of distinct job opportunities she can apply for per year.
- Success Probability (\(u_0\)): Her average probability of getting an offer from a single application. We assume these probabilities are independent and identically distributed (i.i.d.).
The i.i.d. assumption (each job is independent) is likely optimistic. In reality, applications are correlated: if Alice is a good fit for one role, she’s likely a good fit for others (and vice-versa). We formalise this in the next section with a notion of candidate quality distributions that captures the notion that you don’t know your “ranking” in the field, but most people are not in at the top of it, by definition.
1.1.4 Timing
- Discount Rate (\(\rho\)): A continuous annual rate capturing her time preference. A higher \(\rho\) means she values immediate gains more — for example, if she expects short AGI timelines, \(\rho\) might be high.
1.2 Decision Threshold
With these inputs, we can calculate the total expected value (EV) of her sabbatical gamble. The full derivation is in Appendix A, but here’s the result:
\[ \boxed{ \Delta \mathrm{EV}\_\rho(p) =\frac{1-e^{-(r p+\rho)\ell}}{r p+\rho}\left(\frac{\Delta u r p}{\rho}-c\right). } \]
This formula looks complex, but the logic is simple. The whole decision hinges on the sign of the term in brackets: \[ \left(\frac{\Delta u r p}{\rho}-c\right) \] This directly compares the expected gain rate (the upside \(\Delta u\) multiplied by the success rate \(rp\) and adjusted for discounting \(1/\rho\)) with the burn rate (\(c\)). That prefactor scales this value according to the length of Alice’s runway and her discount rate.
The EV is positive if and only if the gain rate exceeds the burn rate. This means Alice’s decision boils down to a simple question: is her per-application success probability, \(p\), high enough to make the gamble worthwhile?
We can find the exact break-even probability, \(p^*\), by setting the gain rate equal to the burn rate. This gives a much simpler formula for Alice’s decision threshold:
\[ \boxed{\,p^*=\frac{c\,\rho}{r\,\Delta u}\,}. \]
If Alice believes her actual \(p\) is greater than this \(p^*\), the pivot has a positive expected value. If \(p < p^*\), she should not take the sabbatical, at least on these terms.
1.3 What This Model Tells Alice
This simple threshold \(p^*\) gives us a clear way to think about her decision:
The bar gets higher: The threshold \(p^*\) increases with higher costs (\(c\)), shorter timelines, or greater impatience (\(\rho\)). If her sabbatical is expensive or she’s in a hurry, she needs to be more confident of success.
The bar gets lower: The threshold \(p^*\) decreases with more opportunities (\(r\)) or a higher upside (\(\Delta u\)). If the job offers a massive impact gain or she can apply to many roles, she can tolerate a lower chance of success on any single one.
Runway doesn’t change the threshold: Notice that the runway length \(\ell\) isn’t in the \(p^*\) formula. A longer runway gives her more expected value (or loss) if she does take the gamble, but it doesn’t change the break-even probability itself.
The results are fragile to uncertainty: This model is highly sensitive to her estimates. If she overestimates her potential impact (a high \(\Delta u\)) or underestimates her time preference (a low \(\rho\)), she’ll calculate a \(p^*\) that is artificially low, making the pivot look much safer than it is.
🚧TODO🚧 plot the sensitivity later.
The key unknown: Even with a perfectly calculated \(p^*\), Alice still faces the hardest part: estimating her own actual success probability, \(p\).
That \(p\) is, essentially, her chance of getting an offer. It depends not only on the number of jobs available but crucially on the number and quality of the other applicants.
All that said, this is a relatively “optimistic” model. If Alice attaches a high value to getting her hands dirty in AI safety work, she might be willing to accept a remarkably low \(p\). We’ll see that in the worked example. Hold that thought, though, because I’ll argue that this personal decision rule can be pretty bad at maximizing total impact.
If you are using these calculations for real, be aware that our heuristics are likely overestimating Alice’s chances. Job applications are not IID. The effective number of independent shots is lower than the raw application count, reducing effective \(r\) — if your skills don’t match the first job, it is also less likely to match the second, because the jobs might be similar to each other.
1.4 Worked example
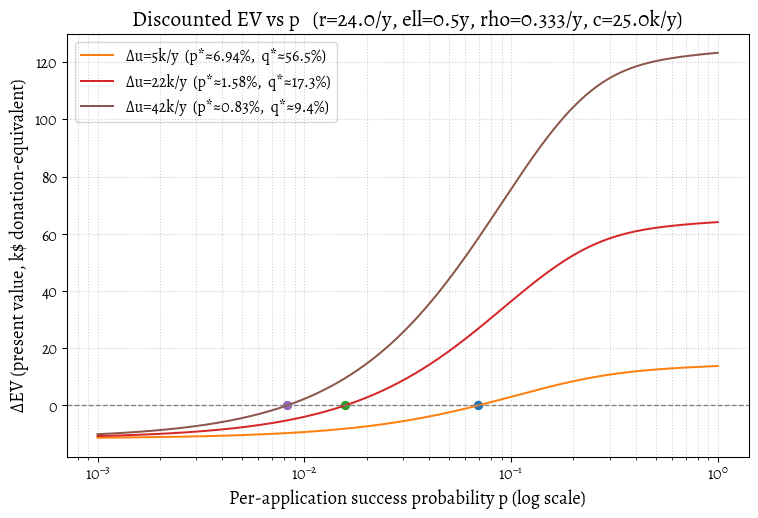
Let’s plug in some plausible numbers for Alice. She’s a successful software engineer who earns \(w_0=180\)k$/year, donates \(d_0=18\)k$/year after tax, and has no on-the-job impact \(\mathcal{I}_0=0\) (i.e. no net harm and no net good). That means Alice earns \(w_0=180\) and donates \(d_0=18\). A target role offers \(w_1=120\), \(d_1=0\), and \(\mathcal{I}_1=100\). Set \(\alpha=1\), a runway of \(\ell=0.5\) years, an application rate of \(r=24\)/year, a discount of \(\rho=1/3\), and a burn of \(c=50\). Then \(\Delta u = (120+0+100)-(180+18+0)=22\) and \[ p^*=\frac{c\rho}{r\Delta u} = \frac{50\cdot\frac{1}{3}}{24\cdot 22} \approx \boxed{3.16\%}. \] Over six months, the chance of at least one success at \(p^*\) is \(q^*=1-e^{-rp^*\ell}\approx \boxed{31.5\%}\). Alice’s expected sabbatical length is \(\mathbb{E}[\tau]=\frac{1-e^{-rp^*\ell}}{rp^*}\approx \mathbf{0.416}\ \text{years (≈5.0 months)}\); conditional on success, it’s \(\mathbb{E}[\tau\mid \text{success}]\approx \mathbf{0.234}\ \text{years (≈2.8 months)}\). Under these assumptions, we expect the sabbatical to break even: the job offers enough upside to compensate for a higher-than-even risk of failure.
We plot a few values to help Alice visualize the trade-offs for different upsides \(\Delta u\).
To play around with the assumptions, try our interactive Pivot EV Calculator (source: danmackinlay/career_pivot_calculator).
2 Part B — Field-level model
So far, this has been Alice’s private perspective. Let’s zoom out to the field level and consider: What if everyone followed Alice’s decision rule? Is the resulting number of applicants healthy for the field? What’s the optimal number of people who should try to pivot?
2.1 From personal gambles to field strategy
Our goal is to move beyond Alice’s private break-even (\(p^*\)) and calculate the field’s welfare-maximizing applicant pool size (\(K^*\)). \(K^*\) is how many “Alices” the field can afford to have rolling the dice before the costs of failures outweigh the value of successes.
To analyse this, we must shift our model in three ways:
Switch to a Public Ledger: From a field-level perspective, private wages and consumption are transfers and drop out of the analysis. What matters is the net production of public goods (i.e., impact).
Distinguish Public vs. Private Costs: The costs are now different.
- Private Cost (Part A): \(c\) included Alice’s full opportunity cost (foregone wages, etc.).
- Public Cost (Part B): We now use \(\gamma\), which captures only the foregone public goods during a sabbatical (e.g., \(\gamma = \mathcal {I}_0 + d_0 + \varepsilon\): baseline impact, baseline donations and externalities).
Move from Dynamic Search to Static Contest: Instead of an individual’s dynamic search, we’ll use a static “snapshot” model of the entire field for one year. We assume there are \(N\) open roles and \(K\) total applicants that year.
NoteReconciling the individual and field-level Models
In Part A, Alice saw jobs arriving one-by-one (a Poisson process with rate \(r\)). In Part B, we are modeling an annual “contest” with \(K\) applicants competing for \(N\) jobs.
We can bridge these two views by setting \(N \approx r\). This treats the entire year’s worth of job opportunities as a single “batch” to be filled from the pool of \(K\) candidates who are “on the market” that year.
This is a standard simplification. It allows us to stop worrying about the timing of individual applications and focus on the quality of the matches, which is determined by the size of the applicant pool (\(K\)). We can then compare the total Present Value (PV) of the benefits (better hires) against the total PV of the costs (failed sabbaticals).
Here’s a paragraph to bridge those two concepts. I’d suggest placing this just before the first plot in Part B, where you start to visualize \(W (K)\).
If \(N\) jobs are available annually (which we’ve already equated to Alice’s application rate \(r\)) and \(K\) total applicants are competing for them, a simple approximation for the per-application success probability is that it’s proportional to the ratio of jobs to applicants.
For the rest of this analysis, we’ll assume a simple mapping: \(p \approx N/K\). This allows us to plot both models on the same chart: as the field becomes more crowded (\(K\) increases), the individual chance of success (\(p\)) for any single application shrinks.
2.2 The Field-Level Model: Assumptions
Here’s the minimally complicated version of our new model:
- There are \(K\) total applicants and \(N\) open roles per year.
- Each applicant \(k\) has a true, fixed potential impact \(J^{(k)}\) drawn i.i.d. from the talent distribution \(F\).
- Employers perfectly observe \(J^{(k)}\) and hire the \(N\) best candidates. (This is a strong, optimistic assumption about hiring efficiency).
- Applicants do not know their own \(J^{(k)}\), only the distribution \(F\).
The intuition is that the field benefits from a larger pool \(K\) because it increases the chance of finding high-impact candidates. But the field also pays a price for every failed applicant.
2.3 Benefits vs. Costs on the Public Ledger
Let’s define the two sides of the field’s welfare equation.
The Marginal Benefit (MV) of a Larger Pool
A larger pool \(K\) helps us find better candidates. We care about the marginal value of adding one more applicant to the pool, which we define as \(\mathrm{MV}_K\). This is the expected annual increase in impact from widening the pool from \(K\) to \(K+1\). (Formally, \(\mathrm{MV}_K := \mathbb{E}[S_{N,K+1}] - \mathbb{E}[S_{N,K}]\), where \(S_{N,K}\) is the total impact of the top \(N\) hires from a pool of \(K\)).
The Marginal Cost (MC) of a Larger Pool
The cost is simpler. When \(K > N\), adding one more applicant results (on average) in one more failed pivot. This failed pivot costs the field the foregone public good during the sabbatical. We define the social burn rate per year as \(\gamma\). To compare this to the annual benefit \(\mathrm{MV}_K\), we need the total present value of this foregone impact. We call this \(L_{\text{fail},\delta}\) (the PV of one failed attempt). (This cost is derived in Appendix B as \(L_{\text{fail},\delta}=\gamma\,\frac{1-e^{-\delta\ell}}{\delta}\)).
We do not model employer congestion from reviewing lots of applicants — the rationale is that it’s empirically small because employers stop looking at candidates when they’re overwhelmed (J. Horton and Vasserman 2021).1
2.4 Field-Level trade-offs
We can now find the optimal pool size \(K^*\). The total public welfare \(W (K)\) peaks when the marginal benefit of one more applicant equals the marginal cost.
As derived in Appendix B, the total welfare \(W(K)\) is maximized when the present value of the annual benefit stream from the marginal applicant (\(\mathrm{MV}_K / \delta\)) equals the total present value of their failure cost (\(L_{\text{fail},\delta}\)). \[ \frac{\mathrm{MV}_K}{\delta} = L_{\text{fail},\delta} \] Substituting the expression for \(L_{\text{fail},\delta}\) and cancelling the discount rate \(\delta\) yields a very clean threshold: \[ \boxed{\,\mathrm{MV}_K = \gamma\,(1-e^{-\delta\ell})\,}. \] This equation underlies the field-level problem. The optimal pool size \(K^*\) is the point where the expected annual marginal benefit (\(\mathrm{MV}_K\)) falls to the level of the total foregone public good from a single failed sabbatical attempt.
2.5 The Importance of Tail Distributions
How quickly does \(\mathrm{MV}_K\) shrink? Extreme value theory tells us it depends entirely on the tail of the candidate-quality distribution, \(F\). The shape of the tail determines how quickly returns from widening the applicant pool diminish.
We consider two families (the specific formulas are in Appendix B):
Light tails (e.g., Exponential): In this world, candidates vary, but the best isn’t transformatively better than average. Returns diminish quickly: the marginal value \(\mathrm{MV}_K\) shrinks hyperbolically (roughly as \(1/K\)).
Heavy tails (e.g., Fréchet): This captures the “unicorn” intuition. Returns diminish much more slowly. If the tail is heavy enough, \(\mathrm {MV}_K\) decays extremely slowly, justifying a very wide search.
2.6 Implications for Optimal Pool Size
This difference in diminishing returns greatly affects the optimal pool size \(K^*\). The full solutions for \(K^*\) are in Appendix B.
With light tails, there’s a finite pool size beyond which ramping up the hype (increasing \(K\)) reduces net welfare. Every extra applicant burns \(L_{\text{fail},\delta}\) in foregone public impact while adding an \(\mathrm{MV}_K\) that shrinks rapidly.
With heavy tails, it’s different. As the tail gets heavier, \(K^*\) explodes. In very heavy-tailed worlds, very wide funnels can still be net positive. We may decide it’s worth, as a society, spending a lot of resources to find the few unicorns.
We set the expected impact per hire per year to \(\mu_{\text{imp}}=100\) (impact dollars/yr) to match Alice’s hypothetical target role. This is just for exposition.
We can, of course, plot this.
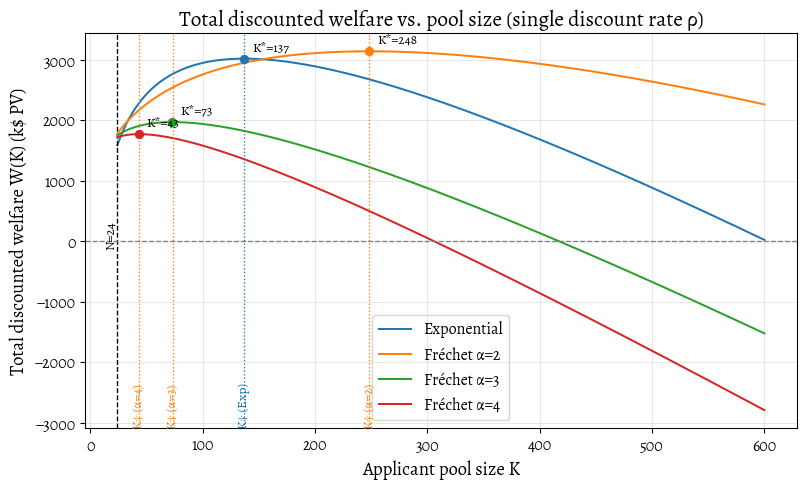
δ=0.333/yr, L_fail=8.29 impact-$ (PV)
Exponential: K*=800 (boundary), W*=25869.7
Fréchet α=1.8: K*=800 (boundary), W*=50300.4
Fréchet α=2.0: K*=800 (boundary), W*=40229.2
Fréchet α=3.0: K*=800 (boundary), W*=19116.8- This plot shows total net welfare \(W (K)\) and marks the maximum \(K^*\) for each family, so we can see where welfare peaks. The dashed line at \(K=N\) shows when failures begin: \((K>N\Rightarrow K-N\) people each impose a public cost of \(L_{\text{fail},\delta})\). The markers show \(K^*=\arg\max W(K)\) — the pool size beyond which widening would reduce total impact.
- Units: \(B(K)\) is in impact dollars per year and is converted to PV by multiplying by \(H_\delta=\frac{1}{\delta}\). The subtraction uses the discounted per-failure cost \(L_{\text{fail},\delta}=\gamma\,\frac{1-e^{-\delta\ell}}{\delta}\).
- Fréchet curves use the large-\(K\) asymptotic \(B(K)\approx s\,K^{1/\alpha}C_N\) (with \(s=\mu_{\text{imp}}/\Gamma(1-1/\alpha)\)). We could compute the exact \(B(K)\) for Fréchet, but the asymptotic is good enough to illustrate the qualitative behaviour.
- We treat future uncertainties about role duration, turnover, or project lifespan as already captured by the overall discount rate \(\delta\).
We can combine these perspectives to visualize the tension between private incentives and public welfare.
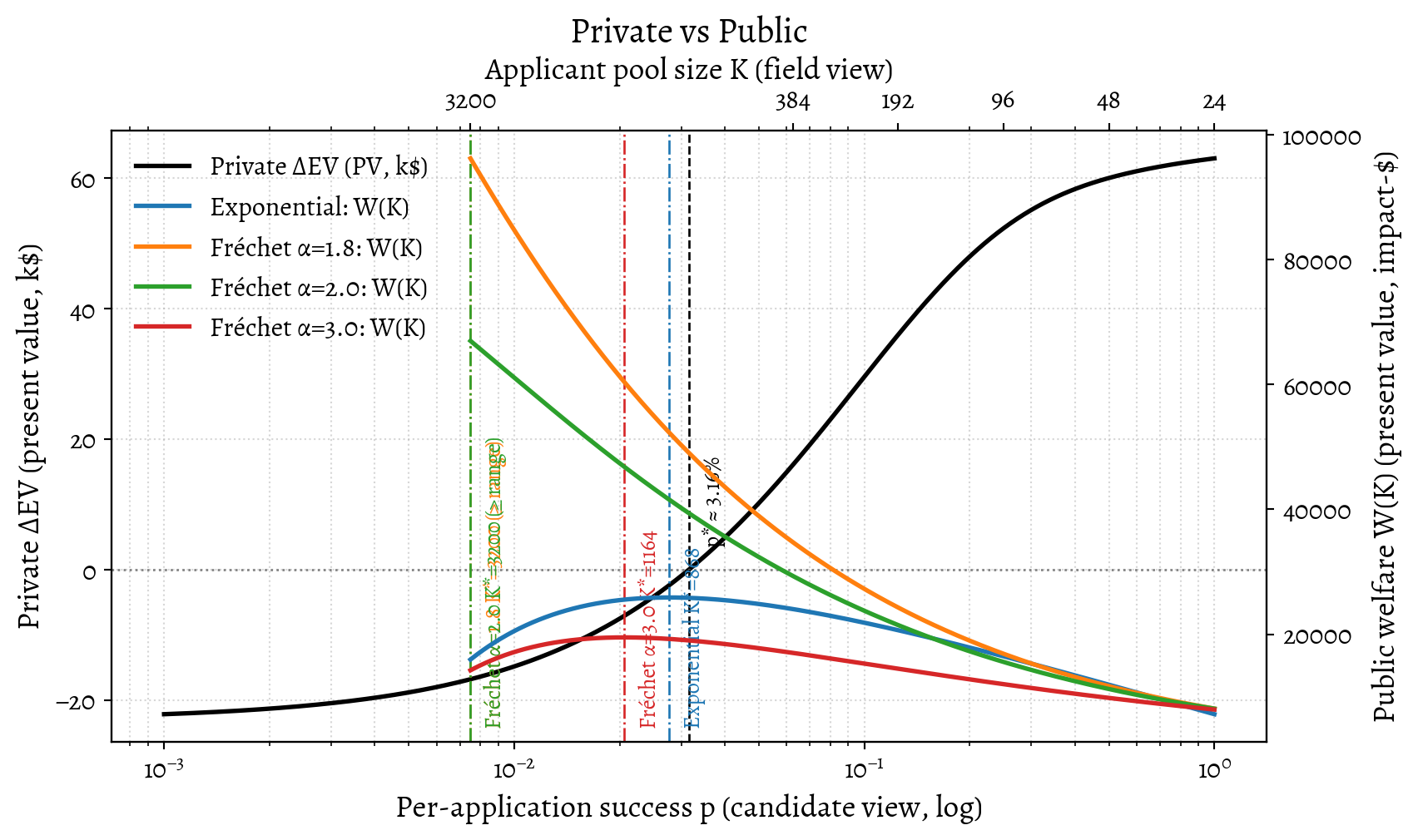
p* (private) = 3.16%
Exponential: K*=868, p(K*)≈2.76%
Fréchet α=1.8: K*=3200 (boundary), p(K*)≈0.75%
Fréchet α=2.0: K*=3200 (boundary), p(K*)≈0.75%
Fréchet α=3.0: K*=1164, p(K*)≈2.06%We combine the private and public views using an illustrative mapping from pool size to success probability: \(p\approx \beta N/K\), where \(\beta\) bundles screening efficiency, and in this figure \(\beta=1\). The black curve (left axis) shows a candidate’s private expected value (EV) as a function of success probability \(p\). The coloured curves (right axis) show the field’s welfare, \(W(K)\). The private break-even point \(p^*\) (black dashed line) can fall far to the left of the field-optimal point \(p(K^*)\) (coloured vertical lines). This gap marks the region where individuals, acting rationally, are incentivized to enter even though, from the candidate’s perspective, the field is already saturated or oversaturated.
3 Part C — Counterfactual Impact and Equilibrium
Part A modelled Alice’s pivot as a private gamble, where the upside was the absolute impact (\(\mathcal{I}_1\)) of the new role. Part B zoomed out, analysing the field-level optimum (\(K^*\)) and showing how the marginal value (\(\mathrm{MV}_K\)) of adding one more applicant shrinks as the pool (\(K\)) grows.
Now we connect these two views. What if Alice is a sophisticated applicant? She understands the field-level dynamics from Part B and wants to maximise her true counterfactual impact—not just the absolute impact of the role she fills. She must update her private EV calculation from Part A.
This introduces a feedback loop: Alice’s personal incentive to apply now depends on the crowd size (\(K\)) and the talent distribution (\(F\)), and those factors in turn influence how many other people apply.
3.1 The Counterfactual Impact Model
In Part A, Alice’s upside \(\Delta u\) included the absolute impact \(\mathcal{I}_1\). But her true impact is counterfactual: it’s the value she adds compared to the next-best person who would have been hired if she hadn’t applied.
How can she estimate this? She doesn’t know her own quality (\(J^{(k)}\)) relative to the pool. If we assume she is, from the field’s perspective, just one more “draw” from the talent distribution \(F\) (formally: applicants are exchangeable), then her expected counterfactual impact from the decision to apply is exactly the marginal value of adding one more applicant: \(\mathrm{MV}_K\) (from Part B).
This \(\mathrm{MV}_K\) is her ex-ante expected impact before the gamble is resolved. But her EV calculation (from Part A) needs the upside conditional on success.
Let \(\mathcal{I}_{CF}\) be this value: the expected counterfactual impact given she succeeds and gets the job. Let \(q_K\) be her overall probability of success in a pool of size \(K\). (In the static model of Part B, if she joins a pool of \(K\) others, there are \(K+1\) applicants for \(N\) slots, so \(q_K \approx N/(K+1)\)). If her attempt fails (with probability \(1-q_K\)), her counterfactual impact is zero.
Therefore, the ex-ante expected impact \(\mathrm{MV}_K\) is simply the probability of success multiplied by the value of that success:
\[ \mathrm{MV}_K = (q_K \cdot \mathcal{I}_{CF}) + ((1-q_K) \cdot 0) = q_K \cdot \mathcal{I}_{CF}. \]
This gives us the key value Alice needs. Her expected counterfactual impact, conditional on success is:
\[ \boxed{\mathcal{I}_{CF} = \frac{\mathrm{MV}_K}{q_K}.} \]
Alice can now recalibrate her private decision from Part A. She defines a counterfactual private surplus, \(\Delta u_{CF}\), by replacing the naive absolute impact \(\mathcal{I}_1\) with her sophisticated counterfactual estimate \(\mathcal{I}_{CF}\).
This changes the dynamics entirely. In Part A, the value of the upside (\(\Delta u\)) was fixed. Now, the value of the upside (\(\Delta u_{CF}\)) itself depends on the pool size \(K\).
As \(K\) grows, both \(\mathrm{MV}_K\) (the marginal value) and \(q_K\) (the success chance) decrease. How \(\mathcal{I}_{CF}\) behaves depends on which decreases faster—the marginal value or the success chance—a property determined by the tail of the impact distribution \(F\).
3.2 The Dynamics of Counterfactual Impact
The behaviour of \(\mathcal{I}_{CF}\) leads to radically different incentives depending on the tail shape of the talent pool.
3.2.1 Case 1: Light Tails
In a light-tailed world (e.g., an Exponential distribution), talent is relatively clustered. The math shows (see Appendix: see Appendix) that \(\mathrm{MV}_K\) and \(q_K\) shrink at roughly the same rate, so their ratio stays constant.
\[ \mathcal{I}_{CF} = \mu \quad \text{(Light Tail)} \]
(where \(\mu\) is the population’s average impact).
Intuition: As the candidate pool \(K\) grows, the quality of the \(N\)th-best hire—the person we displace—rises nearly as fast as the quality of the average successful hire (us). The gap between us and the person we displace remains small and roughly constant. Our counterfactual impact equals the average impact, \(\mu\).
Implication: If the average impact \(\mu\) is modest, \(\mathcal{I}_{CF}\) may not be enough to offset a large pay cut (like Alice’s). In this world, we’d expect pivots with high private costs to be EV-negative for the average applicant, regardless of how large the pool gets.
3.2.2 Case 2: Heavy Tails
In a heavy-tailed world (e.g., Fréchet), “unicorns” with transformative impact exist. Here, \(\mathrm{MV}_K\) shrinks much more slowly than \(q_K\). As shown in the appendix, for a Fréchet distribution with shape \(\alpha\), the result is:
\[ \mathcal{I}_{CF} \propto K^{1/\alpha} \quad \text{(Heavy Tail)} \]
The expected counterfactual impact conditional on success actually increases as the field gets more crowded.
Intuition: Success in a very large, competitive pool (\(K\)) is a powerful signal. It suggests we aren’t just “good” but potentially a “unicorn.” We aren’t just displacing the \(N\)th-best person; we’re potentially displacing someone much further down the tail.
Implication: In this world, the field value can decay slowly as funnel size increases. The potential upside \(\mathcal{I}_{CF}\) can grow large enough to easily offset significant private costs (like pay cuts and foregone donations). As a corollary, if we believe in unicorns, it can still make sense to risk large private costs for a small chance of success to discover whether we actually are a unicorn.
3.3 Alice Revisited
Alice revisited. With light‑tailed assumptions, \(\mathcal{I}_{CF}\) equals the population mean \(\mu\) and is too small to offset Alice’s pay cut and lost donations — her counterfactual surplus is negative regardless of \(K\). Under heavy‑tailed assumptions, \(\mathcal{I}_{CF}\) rises with \(K\); across a broad range of conditions, the pivot can become attractive despite large pay cuts (i.e. if Alice could truly be a unicorn). The sign and size of this effect hinge on the tail parameter and scale, which we haven’t measured yet.
3.4 Visualizing Private Incentives vs. Public Welfare
We can now visualize the dynamics of private, public, and counterfactual private valuations by assuming an illustrative mapping between pool size and success probability: \(p\approx \beta N/K\). This lets us see how incentives change as the field gets more crowded (moving left on the x-axis).
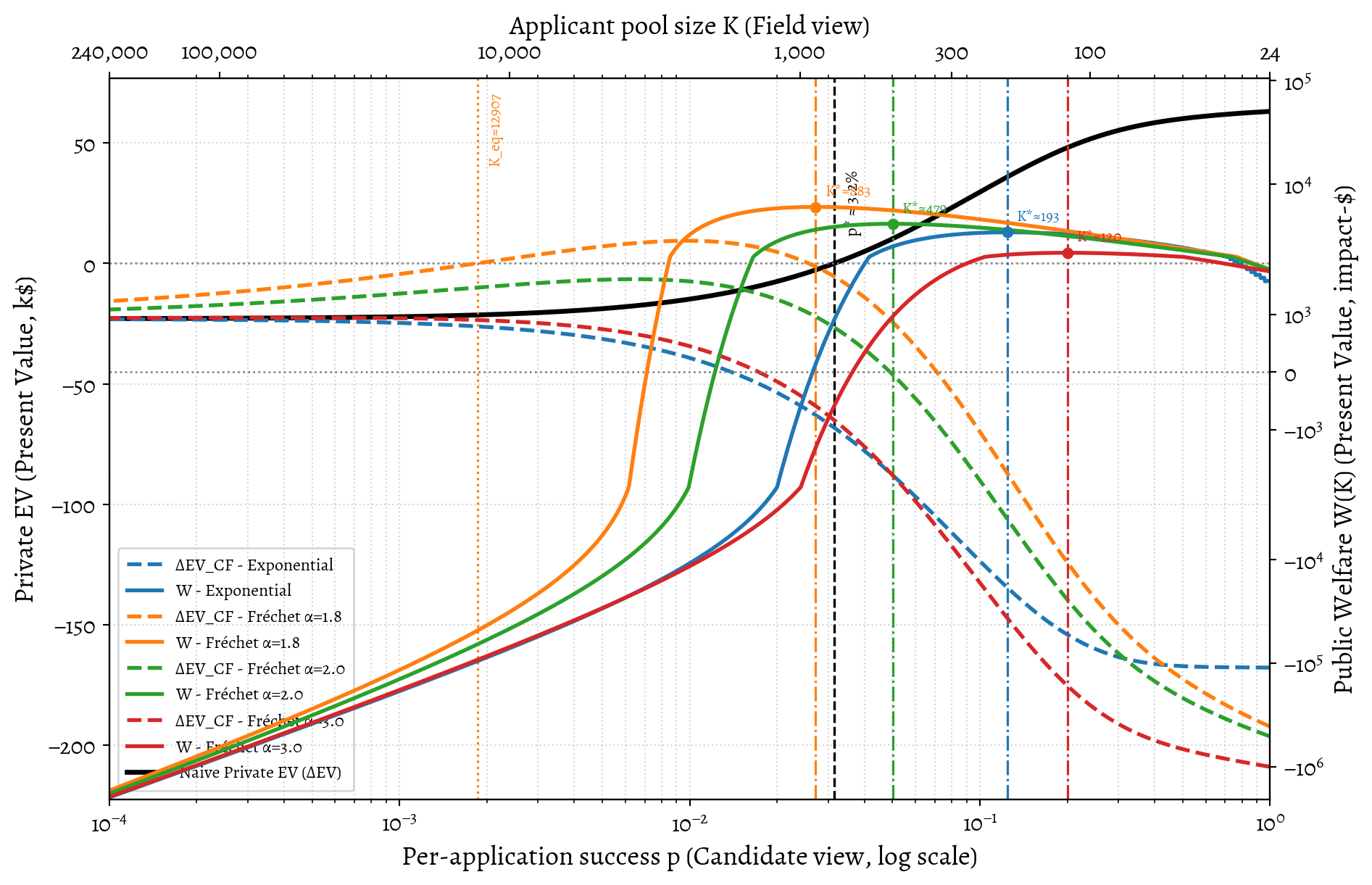
3.5 Visualizing the Misalignment
This visualization brings all three models together, using Alice’s parameters to illustrate the tensions between private incentives and public good. The plot is dense, but it we can read threee key dynamics off it:
- The Information Gap (A vs. C): The “Naive EV” (A, black solid line) is far more optimistic than the “Counterfactual EV” (C, dashed colored lines). An applicant using the simple model from Part A—ignoring their displacement effect—will drastically overestimate the personal EV of pivoting.
- The Impact of Costs (C): In light-tailed worlds (Exponential, purple; Fréchet \(\alpha=3.0\), red), the counterfactual impact is modest. For an applicant like Alice, with her high opportunity costs (a \(\approx 50k\) annual burn rate plus \(18k\) in foregone donations), once there are more applicants than jobs, her impact isn’t large enough to offset her personal financial losses. Her sophisticated EV (dashed line) is therefore negative across the plotted range, implying she should not attempt the pivot in this scenario.
- The Structural Misalignment (B vs. C): This is the core problem. In the heavy-tailed “unicorn” worlds where pivoting is privately rational (green, orange), the socially optimal pool size (\(K^*\), the peak of the solid welfare lines) is far smaller than the private equilibrium (\(K_{eq}\), where the dashed EV lines cross zero). The system incentivizes massive over entry in the field’s own terms.
3.6 Why Does This Happen?
The trite answer is: there are no feedback mechanisms so we should expect alignment to be accidental and transitory when it occurs. A deeper answer is that we might imagine putting in feedback mechanisms but then we will need to decide what to align to. There is a conflict between the private cost of trying and the social cost of failing.
We can find the two different “stop” signals that define the optimum vs. the equilibrium:
- The Social Optimum (\(K^*\)): The field’s total welfare (Part B) peaks when the marginal impact of one more applicant (\(\mathrm {MV}_K\)) drops to equal the social cost of their (likely) failed attempt. For Alice, this cost is the public good she stops producing during her sabbatical—primarily her donations.
- Social Cost of Failure (\(\gamma\)): \(\mathbf{\$18k}\)/year.
- The Private Equilibrium (\(K_{eq}\)): A sophisticated Alice (Part C) stops applying when her private EV becomes zero. This happens when the marginal impact she can expect to have (\(\mathrm {MV}_K\), which she shares with other applicants) drops to equal her effective private cost hurdle per application. As derived in Appendix C, this hurdle is \(\frac{c\rho}{r}\).
- Private Cost Hurdle (\(\frac{c\rho}{r}\)): \(\frac{50k \cdot 1/3}{24} \approx \mathbf{\$0.69k}\) (or \(\$690\)).
The field implicitly “wants” applicants to stop when the marginal impact benefit drops below $18,000. But because the job search is so efficient (high \(r\)), Alice’s private cost for one more “shot at the prize” is only $690.
She is rationally incentivized to keep trying long after her entry is creating a net social loss. This is what drives the massive gap in our heavy-tailed model: the social optimum \(K^*\) might be around 11,600, but the private equilibrium \(K_{eq}\) balloons to over 178,000.
The takeaway for mid-career professionals like Alice is clear. Given her high opportunity cost (including foregone donations), donating is the robustly higher-EV option unless she has specific evidence that both (a) the talent pool is extremely heavy-tailed and (b) she is likely to be one of the “unicorns” in that tail.
4 Implications and Solutions
Our takeaway is that the AI safety career funnel, and likely other high-impact career funnels, is miscalibrated. Not in the sense that we are definitely producing net harm right this minute, but in the sense that the feedback mechanisms needed to prevent net harm don’t exist. It’s hard to know how bad this is, but Alice’s \(18k\) social cost versus the \(690\) private hurdle is worrisome if those numbers are typical.
That is to say, all this work on alignment is misaligned. Organizations influencing the funnel size don’t internalize the costs borne by unsuccessful applicants. This incentivizes maximizing application volume (a visible proxy) rather than welfare-maximizing matches—a classic setup for Goodhart’s Law.
That said, it’s not even clear what we should aim to align to: the equilibria for maximizing personal life satisfaction for applicants may differ from those that maximize total field impact.
If we want to make a credible claim to be impact-driven, it is the latter, the net public good, that needs to be prioritized, because “please donate so that a bunch of monied professionals can self-actualize” is not a great pitch.
4.1 For Individuals: Knowing the Game
For mid-career individuals, the decision is high-stakes. (For early-career individuals, costs \(c\) are lower, making the gamble more favourable, but the need to estimate \(p\) remains.)
Calculate your threshold (\(p^*\)): Use the model in Part A (and the linked calculator). Without strong evidence that \(p > p^*\) is true, a pivot involving significant unpaid time is likely EV-negative.
Seek cheap signals about whether we are in fact a unicorn: Look for personalized evidence of fit—such as applying to a few roles before leaving our current job—before committing significant resources.
Use grants as signals: Organizations like Open Philanthropy offer career transition grants. These serve as information gates. If we receive one, it lowers the private cost (\(c\)). If denied, it is a valuable calibration signal. If a major funder declines to underwrite the transition, we should update \(p\) downwards. (If we don’t get that Open Phil transition grant, don’t quit our current job.)
Change the game by doing something other than applying for a job:
- We can often achieve impact by getting AI safety on the agenda at our current job (if it’s tech-related). Influencing our current employer to take AI safety seriously can have a huge effect, without needing to pivot careers.
- Founding or joining a new organization can create multiple roles, reducing the need to compete for existing ones.
4.2 For Organizations: Transparency and Feedback
Employers and advice organizations control the information flow. Unless they provide evidence-based estimates of success probabilities, their generic encouragement should be treated with scepticism.
- Publish stage-wise acceptance rates (Base Rates). Employers should publish historical data (applicants, interviews, offers) by track and seniority. This is the single most impactful intervention for anchoring \(p\).
- Provide informative feedback and rank. Employers should provide standardized feedback or an indication of relative rank (e.g., “top quartile”). This feedback is costly, but this cost must be weighed against the significant systemic waste currently externalized onto applicants and the long-term credibility of the field.
- Track advice calibration. Advice organizations should track and publish their forecast calibration (e.g., Brier scores) regarding candidate success. If an advice organization doesn’t track outcomes, its advice cannot be calibrated other than by coincidence.
4.3 For the Field: Systemic Calibration
To optimize the funnel size, the field needs to measure costs and impact tails.
- Estimate applicant costs (\(c\ell\)). Advice organizations or funders should survey applicants (successful and unsuccessful) to estimate typical pivot costs.
- Track realized impact proxies. Employers should analyse historical cohorts to determine if widening the funnel is still yielding significantly better hires, or if returns are rapidly diminishing.
- Experiment with mechanism design. In capacity-constrained rounds, implementing soft caps—pausing applications after a certain number—can reduce applicant-side waste without significantly harming match quality (J. J. Horton et al. 2024).
5 Where next?
I’d like feedback from people deeper in the AI safety career ecosystem about what I’ve gotten wrong. Is the model here sophisticated enough to capture the main dynamics? I’d love to chat with people from 80,000 Hours, MATS, FHI, CHAI, Redwood Research, Anthropic, etc., about this. What’s your model of the candidate impact distribution, the tail behaviour, and the costs? What have I got wrong? What have I missed? I’m open to the possibility that this is well understood and being actively managed behind the scenes, but I haven’t seen it laid out this way anywhere.
6 Further reading
Resources that complement the mechanism-design view of the AI safety career ecosystem:
- Christopher Clay, AI Safety’s Talent Pipeline is Over-optimised for Researchers
- AI Safety Field Growth Analysis 2025
- Why experienced professionals fail to land high-impact roles Context deficits and transition traps that explain why even strong senior hires often bounce out of the AI safety funnel.
- Levelling Up in AI Safety Research Engineering. A practical upskilling roadmap; complements the “lower \(c\), raise \(V\), raise \(p\)” levers by reducing risk before a pivot.
- SPAR AI — Safety Policy and Alignment Research program. An example of a program that provides structured training and, implicitly, some “negative previews” of the grind of AI safety work.
- MATS retrospectives — LessWrong. Transparency on acceptance rates, alumni experiences, and obstacles faced in this training program.
- Why not just send people to Bluedot on FieldBuilding Substack. A critique of naive funnel-building and the hidden costs of over-sending candidates to “default” programs.
- How Stuart Russell’s IASEAI conference failed to live up to its potential (FBB #8). A cautionary tale about how even well-intentioned field-building efforts can misfire without mechanism design.
- 80,000 Hours career change guides. Practical content on managing costs, transition grants, and opportunity cost—useful for calibrating \(c\) in the pivot-EV model.
- Forecasting in personal decisions — 80k. Advice on making and updating stage-wise probability forecasts; relevant to candidate calibration.
- AI safety technical research - Career review
- Updates to our research about AI risk and careers - 80,000 Hours
- The case for taking your technical expertise to the field of AI policy - 80,000 Hours
- Center for the Alignment of AI Alignment Centers. A painfully relatable satire that deserves citing here.
- AMA: Ask Career Advisors Anything
7 Appendix A: Private Decision Model Derivations
We model the career pivot attempt as a continuous-time process during a sabbatical of maximum length \(\ell\).
Setup:
- Job opportunities arrive as a Poisson process with rate \(r\).
- The per-application success probability is \(p\) (i.i.d.).
- The success process is a Poisson process with rate \(\lambda = rp\).
- The time to the first success is \(T_1 \sim \mathrm{Exp}(\lambda)\).
- The actual sabbatical duration is the stopping time \(\tau = \min\{T_1, \ell\}\).
- The continuous discount rate is \(\rho>0\).
- The annual utility surplus if the pivot succeeds is \(\Delta u\).
- The burn rate during the sabbatical is \(c\).
7.1 Sabbatical Duration and Success Statistics
The probability of success within the runway is: \[ q = P(T_1 \le \ell) = 1 - e^{-\lambda \ell} = 1 - e^{-r p \ell}. \] We compute the expected duration \(\mathbb{E}[\tau]\) using the survival function \(P(\tau > t)\). For \(t \in [0, \ell]\), \(\tau > t\) holds exactly when no success has occurred by time \(t\), so \(P(\tau > t) = P(T_1 > t) = e^{-\lambda t}\). So we get \(P(\tau>t)=0\) for \(t>\ell\). \[ \mathbb{E}[\tau] = \int_0^\infty P(\tau > t)\,dt = \int_0^\ell e^{-\lambda t}\,dt = \frac{1 - e^{-\lambda \ell}}{\lambda}. \] We model the expected duration \(\mathbb{E}[\tau\mid \text{success}] = \mathbb{E}[T_1 \mid T_1 \le \ell]\) of a successful trial with a truncated exponential distribution. The PDF of \(T_1\) conditional on \(T_1 \le \ell\) is \(f(t\mid T_1\le\ell) = \frac{\lambda e^{-\lambda t}}{1-e^{-\lambda\ell}}\) for \(t\in[0,\ell]\). Integrating by parts, we get: \[ \begin{aligned} \mathbb{E}[\tau\mid \text{success}] &= \frac{1}{1-e^{-\lambda\ell}} \int_0^\ell t \lambda e^{-\lambda t}\,dt \ &= \frac{1}{1-e^{-\lambda\ell}}\left( \left[-t e^{-\lambda t}\right]_0^\ell + \int_0^\ell e^{-\lambda t}\,dt \right) \ &= \frac{1}{1-e^{-\lambda\ell}}\left( -\ell e^{-\lambda\ell} + \frac{1-e^{-\lambda\ell}}{\lambda} \right) \ &= \frac{1}{\lambda} - \frac{\ell e^{-\lambda\ell}}{1-e^{-\lambda\ell}}. \end{aligned} \]
7.2 Derivation of the Expected Present Value (\(\Delta \mathrm{EV}_\rho(p)\))
The expected value of a pivot attempt equals the expected discounted benefit minus the expected discounted cost.
Expected Discounted Benefit (\(\mathbb{E}[B]\)): If the pivot succeeds at time \(T_1=t \le \ell\), the benefit is the present value (PV) of the stream \(\Delta u\) that begins at \(t\): \(B(t) = \int_t^\infty \Delta u\,e^{-\rho (s-t)}e^{-\rho t}\,ds = \frac{\Delta u}{\rho}e^{-\rho t}\). We take the expectation over the time of success, \(T_1\), up to the runway limit \(\ell\), with density \(f_{T_1}(t) = \lambda e^{-\lambda t}\): \[ \begin{aligned} \mathbb{E}[B] &= \int_0^\ell B(t) f_{T_1}(t)\,dt = \int_0^\ell \frac{\Delta u}{\rho}e^{-\rho t} \lambda e^{-\lambda t}\,dt \ &= \frac{\Delta u \lambda}{\rho} \int_0^\ell e^{-(\lambda+\rho)t}\,dt \ &= \frac{\Delta u \lambda}{\rho(\lambda+\rho)} (1-e^{-(\lambda+\rho)\ell}). \end{aligned} \]
Expected Discounted Cost (\(\mathbb{E}[C]\)): The cost accrues at rate \(c\) during the sabbatical \([0, \tau]\). We compute \(\mathbb{E}\left[\int_0^\tau c e^{-\rho t} dt\right]\). We interchange expectation and integration by Fubini’s theorem, since the integrand is positive: \[ \mathbb{E}[C] = c \int_0^\infty e^{-\rho t} \mathbb{E}[\mathbb{I}(t < \tau)] dt = c \int_0^\infty e^{-\rho t} P(\tau > t) dt. \] We use the survival function \(P(\tau > t) = e^{-\lambda t}\) for \(t \in [0, \ell]\): \[ \mathbb{E}[C] = c \int_0^\ell e^{-\rho t} e^{-\lambda t} dt = c \int_0^\ell e^{-(\lambda+\rho)t} dt = c \frac{1-e^{-(\lambda+\rho)\ell}}{\lambda+\rho}. \]
Total expected value: \[ \Delta \mathrm{EV}_\rho(p) = \mathbb{E}[B] - \mathbb{E}[C]. \] We factor out the common term \(\frac{1-e^{-(\lambda+\rho)\ell}}{\lambda+\rho}\) (the expected discounted duration) and substitute \(\lambda=rp\) for it: \[ \boxed{ \Delta \mathrm{EV}_\rho(p) = \frac{1-e^{-(rp+\rho)\ell}}{rp+\rho} \left(\frac{\Delta u\,rp}{\rho} - c\right). } \]
7.3 Break-even Probability (\(p^*\))
The EV is zero whenever the term in the brackets is zero, because the prefactor is strictly positive. \[ \frac{\Delta u\,rp_\rho^*}{\rho} - c = 0 \implies \boxed{p_\rho^* = \frac{c\rho}{r\Delta u}}. \]
8 Appendix B: Field-Level Model Derivations
We analyse the field-level optimum using a public ledger in impact dollars.
Setup:
- There are \(K\) applicants and \(N\) seats. Impacts are \(J^{(k)} \sim F\), i.i.d.
- We hire the top \(N\) candidates: \(J_{(K)} \ge J_{(K-1)} \ge \dots\).
- Total annual impact from the top \(N\) is \(S_{N,K}:=J_{(K)}+J_{(K-1)}+\dots+J_{(K-N+1)}\).
- Expected annual benefit: \(B(K) = \mathbb{E}[S_{N,K}]\).
- Marginal value: \(\mathrm{MV}_K = B(K+1) - B(K)\).
- Social discount rate: \(\delta\).
- Social burn rate (foregone public impact): \(\gamma := \mathcal{I}_0 + d_0 + \varepsilon\).
We don’t model congestion costs. Generally, once employers have filled a role, they ignore excess applications; there’s a lot of evidence they do (J. Horton, Kerr, and Stanton 2017; J. Horton and Vasserman 2021; J. J. Horton et al. 2024).
8.1 Welfare Function and Optimality
Present-value horizon: \(H_\delta = \int_0^\infty e^{-\delta t}\,dt = 1/\delta\).
PV of a failed attempt: We assume a failed attempt uses the full runway \(\ell\) (which simplifies calculating the marginal cost of an additional applicant): \[ L_{\text{fail},\delta} = \int_0^\ell \gamma e^{-\delta t}\,dt = \gamma\frac{1-e^{-\delta\ell}}{\delta}. \]
Total Welfare (\(W(K)\)): The total welfare \(W(K)\) is the present value of benefits from the \(N\) hires minus the present value of costs of all \((K-N)\) failures. \[ W(K) = B(K) \cdot H_\delta - \max\{K-N, 0\} \cdot L_{\text{fail},\delta}. \] We define the welfare-maximizing pool size \(K^*\) (for \(K>N\)) as the point where marginal benefit equals marginal cost. When we add a single applicant, the expected number of failures in the pool increases by exactly one, so the marginal cost equals \(L_{\text{fail},\delta}\). \[ \mathrm{MV}_K \cdot H_\delta = L_{\text{fail},\delta}. \] After substituting the expressions and cancelling \(1/\delta\): \[ \boxed{\mathrm{MV}_K = \gamma (1-e^{-\delta\ell}).} \] This is the optimality condition we used in the main text.
8.2 Distribution-Specific Results
We solve for \(K^*\) from the behaviour of \(\mathrm{MV}_K\) under different distributions \(F\).
8.2.1 Exponential Distribution (Light Tail)
Let \(J \sim \mathrm{Exp}(\lambda)\) have mean \(1/\lambda\). The expected sum of the top \(N\) order statistics from \(K\) draws has a closed form, often derived from the Rényi representation of exponential spacings: \[ B(K)=\frac{N}{\lambda}\Bigl(1+H_K-H_N\Bigr), \] Here \(H_K = \sum_{k=1}^K \frac{1}{k}\) denotes the \(K\)th harmonic number.
Marginal Value: \[ \mathrm{MV}_K = B(K+1) - B(K) = \frac{N}{\lambda}(H_{K+1} - H_K) = \frac{N}{\lambda(K+1)}. \] Returns diminish hyperbolically (\(O(1/K)\)).
Optimal Pool Size \(K^*\): We set \(\mathrm{MV}_K\) equal to the marginal social cost \(\gamma (1-e^{-\delta\ell})\): \[ \boxed{K^* = \frac{N}{\lambda\gamma(1-e^{-\delta\ell})} - 1.} \]
8.2.2 Fréchet Distribution (Heavy Tail)
Let \(J \sim \text{Fréchet}(\alpha, s)\) have shape parameter \(\alpha>1\), which is necessary for a finite mean, and scale \(s\). We’ll use asymptotic results from extreme-value theory when \(K\) is large. The expected sum of the largest \(N\) values scales like \(K^{1/\alpha}\): \[ B(K) \approx s\,K^{1/\alpha}\,C_N(\alpha), \] where \(C_N(\alpha)\) is a constant independent of \(K\) and \(s\): \[ C_N(\alpha) := \sum_{k=1}^{N}\frac{\Gamma\bigl(k-\tfrac{1}{\alpha}\bigr)}{\Gamma(k)}. \]
Marginal Value: We obtain the marginal value by differentiating the asymptotic expression: \[ \mathrm{MV}_K \approx \frac{d}{dK} B(K) = s C_N(\alpha) \frac{1}{\alpha} K^{\frac{1}{\alpha}-1}. \] Returns diminish as a power law (\(O(K^{-(1-1/\alpha)})\)), which is slower than exponential decay.
Optimal pool size \(K^*\): We set \(\mathrm{MV}_K\) equal to the marginal social cost, \(\gamma (1-e^{-\delta\ell})\), and solve for \(K\): \[ \frac{s C_N(\alpha)}{\alpha} (K^*)^{\frac{1}{\alpha}-1} = \gamma (1-e^{-\delta\ell}). \] \[ \boxed{K^* = \left(\frac{s\,C_N(\alpha)}{\alpha\,\gamma\,(1-e^{-\delta\ell})}\right)^{\frac{\alpha}{\alpha-1}}.} \] As \(\alpha \downarrow 1\) (heavier tails) increases, the exponent \(\frac{\alpha}{\alpha-1} \to \infty\) causes \(K^*\) to explode.
8.3 Plotting Parameters (for \(W(K)\) curves)
To plot the total welfare curves \(W(K)\), we need the total benefit \(B(K)\) and must normalize the distributions so they share the same mean impact, \(\mu_{\text{imp}}\), for a fair comparison. We set \(\mu_{\text{imp}}=100\) impact-dollars/yr in the main text.
- Exponential:
- Mean: \(1/\lambda=\mu_{\text{imp}}\Rightarrow \lambda=1/\mu_{\text{imp}}\).
- Total Benefit (exact): \(B(K)=\mu_{\text{imp}}\,N\,\Big(1+H_K-H_N\Big)\).
- Fréchet (\(\alpha>1\)):
- Mean: \(\mathbb{E}[J]=s\,\Gamma(1-1/\alpha)=\mu_{\text{imp}}\Rightarrow s=\mu_{\text{imp}}/\Gamma(1-1/\alpha)\).
- Total Benefit (asymptotic): \(B(K)\approx s\,C_N(\alpha)\,K^{1/\alpha}\).
- (Where \(C_N(\alpha)\) is defined above).
We analyse the field-level optimum using a public ledger denominated in impact dollars.
9 Appendix C: Counterfactual Impact and Equilibrium Derivations
9.1 Derivation of \(\mathcal{I}_{CF}\)
We relate the marginal value of entry (\(\mathrm{MV}_K\)) to the expected counterfactual impact, conditional on success (\(\mathcal{I}_{CF}\)).
\(\mathrm{MV}_K\) is the expected increase in total field impact when an applicant joins the pool (i.e., when applicants increase from \(K\) to \(K+1\)). Let \(S\) be the event of success (being hired). \(q_K\) is the probability of success, \(P(S)\). We assume applicants are exchangeable.
By the law of total expectation: \[ \mathrm{MV}_K = \mathbb{E}[\text{Impact of Entry} \mid S] P(S) + \mathbb{E}[\text{Impact of Entry} \mid \neg S] P(\neg S). \] If an applicant enters and fails (\(\neg S\)), the applicant’s counterfactual impact is zero. The expected impact, conditional on success, is \(\mathcal{I}_{CF}\).
Therefore: \[ \mathrm{MV}_K = \mathcal{I}_{CF} \cdot q_K. \] We assume exchangeable applicants compete for \(N\) slots in a pool consisting of \(K+1\) and \(q_K = N/(K+1)\). \[ \mathcal{I}_{CF} = \frac{\mathrm{MV}_K}{q_K} = \mathrm{MV}_K \cdot \frac{K+1}{N}. \]
9.2 \(\mathcal{I}_{CF}\) for distributions
Exponential (light-tailed): The mean impact is \(\mu\). See Appendix B for \(\mathrm{MV}_K = N\mu/(K+1)\). \[ \mathcal{I}_{CF} = \frac{N\mu/(K+1)}{N/(K+1)} = \mu. \] We find that the expected counterfactual impact—conditional on success—is constant.
Fréchet (heavy tail):
Appendix B shows \(\mathrm{MV}_K \propto K^{1/\alpha-1}\), which is valid asymptotically for large K. \(q_K \propto 1/K\). \[ \mathcal{I}_{CF} = \frac{\mathrm{MV}_K}{q_K} \propto \frac{K^{1/\alpha-1}}{1/K} = K^{1/\alpha}. \] We expect the counterfactual impact, conditional on success, to increase with the pool size \(K\).
9.3 Equilibrium Condition and Misalignment
We reach equilibrium \(K_{eq}\) when the private expected value (EV), computed using the counterfactual surplus \(\Delta u_{CF}(K)\), equals zero. This occurs when the bracketed term in the EV formula (Part A) is zero: \[ \frac{\Delta u_{CF}(K)\,r p(K)}{\rho} - c = 0 \implies \Delta u_{CF}(K) \cdot p(K) = \frac{c\rho}{r}. \] The RHS, \(\frac{c\rho}{r}\), is the effective private cost hurdle per application attempt.
We compare it to the social optimality condition \(K^*\), defined in Part B.
For simplicity, we approximate the social cost of failure, \(L_{\text{fail},\delta} \approx \gamma/\delta\), by assuming a large \(\ell\) and setting \(\delta=\rho\).
The optimality condition \(\mathrm{MV}_K \cdot H_\delta = L_{\text{fail},\delta}\) then becomes: \[ \mathrm{MV}_K = \gamma. \]
Analyzing Over/Under Entry:
To illustrate the misalignment, let’s consider a simplified case where private financial losses (pay cuts) are negligible, so \(\Delta u_{CF}(K) \approx \mathcal{I}_{CF}(K)\). Also assume the per-application success rate \(p(K)\) approximates the overall success probability \(q_K\).
In this case, \(\Delta u_{CF}(K) \cdot p(K) \approx \mathcal{I}_{CF}(K) \cdot q_K = \mathrm{MV}_K\).
The private equilibrium condition simplifies to: \(\mathrm{MV}_K = \frac{c\rho}{r}\). The social optimum condition remains: \(\mathrm{MV}_K = \gamma\).
Since \(\mathrm{MV}_K\) is decreasing in \(K\), we get \(K_{eq} > K^*\) (over-entry) when the private threshold is lower than the social threshold: \[ \frac{c\rho}{r} < \gamma. \] This happens when the private cost per attempt is lower than the social cost of failure. As the main text shows, with Alice’s parameters (0.69k vs 18k), this inequality often holds strongly, indicating a structural tendency toward over-entry even when agents use sophisticated counterfactual reasoning.
10 Incoming
11 References
Arulampalam. 2000. “Is Unemployment Really Scarring? Effects of Unemployment Experiences on Wages.”
Caron, Teh, and Murphy. 2014. “Bayesian Nonparametric Plackett–Luce Models for the Analysis of Preferences for College Degree Programmes.” The Annals of Applied Statistics.
Earnest, Allen, and Landis. 2011. “Mechanisms Linking Realistic Job Previews with Turnover: A Meta‐Analytic Path Analysis.” Personnel Psychology.
Hill, Yin, Stein, et al. 2025. “The Pivot Penalty in Research.” Nature.
Horton, John, Kerr, and Stanton. 2017. “Digital Labor Markets and Global Talent Flows.” Working Paper. Working Paper Series.
Horton, John J, Sloan, Vasserman, et al. 2024. “Reducing Congestion in Labor Markets: A Case Study in Simple Market Design.”
Horton, John, and Vasserman. 2021. “Job-Seekers Send Too Many Applications: Experimental Evidence and a Partial Solution.” 021.
Schmidt, Frank L., and Hunter. 1998. “The Validity and Utility of Selection Methods in Personnel Psychology: Practical and Theoretical Implications of 85 Years of Research Findings.” Psychological Bulletin.
Schmidt, F. L., Oh, and Shaffer. 2016. “The Validity and Utility of Selection Methods in Personnel Psychology: Practical and Theoretical Implications of 100 Years of Research.”
Skaperdas. 1996. “Contest Success Functions.” Economic Theory.
Footnotes
I’m making this super clear because when I get LLMs to review this piece they’re inevitably keen to push me to add employer congestion costs, but the literature is pretty clear it’s not a first-order effect in practice. Note, however, that we also assume employers perfectly observe \(J^{(k)}\), which means we’re being optimistic about the field’s ability to sort candidates. Maybe we could model a noisy search process?↩︎