Psychometrics
Dimensionality reduction for souls
2017-10-30 — 2025-08-23
Wherein Measures of Minds Are Surveyed, Causal Claims and Confounding Are Examined, and the Tension Between Univariate G‑factor Claims and Multidimensional Intelligence and Personality Models Is Delineated.
On measuring people’s minds and possibly even discovering something about them in the process. A history that sounds like it might be pushing an agenda is Davidson (2020).

1 Causality and confounding
Some attempts to measure people’s minds end up tautological instead of explanatory. Because of my own intellectual history, I think of that tendency as what Bateson (2002) calls a dormitive principle problem.
A common form of empty explanation is the appeal to what I have called “dormitive principles,” borrowing the word dormitive from Molière. There is a coda in dog Latin to Molière’s Le Malade Imaginaire, and in this coda, we see on the stage a medieval oral doctoral examination. The examiners ask the candidate why opium puts people to sleep. The candidate triumphantly answers, “Because, learned doctors, it contains a dormitive principle.” 1
How are other nebulous univariate influences, like the teamwork factor (Weidmann and Deming 2020), different, if at all?
A more common name for dormitive principles is begging the question. Circularity isn’t always bad; it does complicate things, and it is bad if we pretend we don’t have circularity.
Related, but distinct, is the question about the graphical structure of psychometric models. What causes what? We can indeed do causal modelling. Here’s an attempt: Quintana (2020), with a result like this:
the algorithms identified prior achievement, executive functions (in particular, working memory, cognitive flexibility, and attentional focusing), and motivation as direct causes of academic achievement.
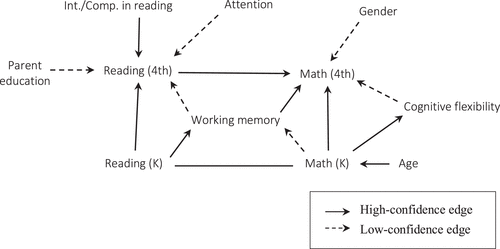
In practice, the situation is fraught because it’s difficult; see various disputes below. Also, that topic is taboo in the field (Grosz, Rohrer, and Thoemmes 2020).
2 Smarts

Various links on the \(g\)-factor debate, which I take to mean the hypothesis that there exists a useful, simple, explanatory, heritable, identifiable, falsifiable, scalar, consistent measure of human cognitive capacity/speed/efficiency. It’s closely coupled with IQ, which is supposed to approximate it.
I know little about this concept. FWIW, I feel intuitively that a minimally more interesting question would be about psychometric nonparametric dimension reduction if we wanted to measure what humans can do, It would also make the task-specific predictive loss function explicit.
For a more lavish viewpoint, consider Georgi (2022):
The conclusion I draw from many years of physicist watching is that if you want to quantify what makes a great physicist, you must use a space with very many dimensions, a different dimension for each of the very many possible ways of thinking that may be important for really interesting problems. I sometimes imagine a spherical cow model of physics talent in N dimensions where N is large and talent in each dimension increases from 0 at the origin to 1 at the boundary, the N-dimensional version of the positive octant of a sphere. This, I learned from Wikipedia, is called an “orthant”. Each point in my N-dimensional orthant is a possible set of talents for physics. Great physicists are out near the boundary, far away from the origin. If we assume that the talents are uniformly distributed, you can see that in my spherical cow model, the fraction of possible physics talents within ε of the boundary grows like N times ε for small ε. If N is very large, as I think it is, that means that there is a lot of space near the boundary! What this suggests to me is that there are a huge number of ways of being a great physicist and that in turn suggests there are many ways of being a great physicist that we haven’t seen yet.
Okay, that might be a little too lavish for my tastes, but yeah.
In this model, we are allowing that cognitive diversity might be intrinsically important because that captures useful mavericks.
Other arguments in the public sphere are far from either of these notions. They tend to claim or refute that human mental capacities are univariate and linear, which is a curiously restricted hypothesis to test in this golden age of machine learning and richly parameterized models. I’m sure there must be a reason for that poverty of modelling. To an outsider like me, without context to explain why this hot topic is so basic, it feels like I’m witnessing a schism in the automotive industry about whether coal-powered cars are better than wood-powered cars. Why this particular modelling choice? What’s the context? Is this about simplicity, generality, portability, reproducibility, explanatory power, cheapness of the resulting test, rhetorical effect, or the ease of getting experiments past the ethics board? Or is it to salvage something from a degenerate research programme? Maybe a little of all of these?
Maybe I’m confused because the most prominent voices arguing this make the least nuanced points. In this version, arguments gain prominence by a toxoplasma of rage annoyance effect, and the debates I notice aren’t between automotive engineers but between automotive industry PR flacks who want to sell me the new season’s model—or between engineers and marketing teams? Maybe if I dug deeper I’d find more of interest here? Am I being confused by a thicket of hobbyists debating issues the professionals have left behind? The problem is that I care about the question, if at all, as something I might need to understand if I’m caught up in a shouting match about it, and that latter eventuality has not lately arisen.

Shalizi’s \(g\), a Statistical Myth, Dalliard’s rejoinder (perhaps best read with their intro to the background which is written with a true fan’s dedication). Zack Davis’ Univariate fallacy is a useful framing for both of the above. See also IQ defined. The philosophical coda to Zack M. Davis’ Book Review: Charles Murray’s Human Diversity: The Biology of Gender, Race, and Class includes an analysis in terms of a co-ordination-on-belief problem, which is another angle on why discourse on \(g\)-factors is vexed. Nassim Taleb is aggressive as usual: IQ is largely a pseudoscientific swindle. Steve Hsu has a different take. I feel like if I had time I might want to take apart those last two articles side by side and see where they talk across each other, because they seem to exemplify a common pattern of cross talk.
FWIW, intelligence research looks to me like it’s unusually fastidious compared to other psychological disciplines in avoiding obviously questionable research practices. See the retraction of Duckworth et al. (2011).
2.1 No, but actually 8 factors
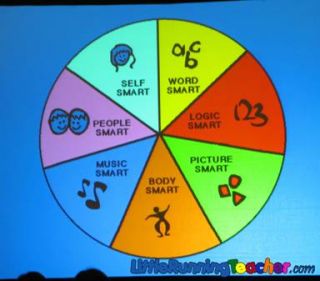
Scott McGreal and Bernard Luskin argue about Gardner’s alternative decomposition of human capabilities into 7 or 8 different intelligences. This discussion doesn’t answer my phenomenological questions about the \(g\) factor, and the supporting research is even less satisfying, so I’ll probably ignore it at my current level of engagement.
3 Personality tests
So many. As far as I can tell, the five-factor (“Big Five” to its friends) model is the archetype, but Depue and Fu (2013) lists several:
Eysenck and Gray’s models (Gray 1994), the Five-Factor model (Costa Jr. and McCrae 2000), Tellegen’s Multidimensional Personality Questionnaire (MPQ) model (Tellegen and Waller 2008), and Zuckerman’s Alternative Five-Factor model (Zuckerman 2002).
There are a lot of popular models for self-assessment. A curious phenomenon is how much we love doing them. The most popular seem to be quadrant models, with four factors that kind of look like a \(2\times 2\) grid. But there’s also the famous Big Five.
Using surveys to understand deep psychological traits sets up a tough problem for us; it’s a very indirect way of measuring something. See survey modelling for a general overview and Biesanz and West (2004) for an example of the kinds of issues that arise in psychometrics in particular.
3.1 DISC
One that is popular amongst my colleagues is DISC. Kate Roskvist classifies these models, I think intentionally, as inheritors of ancient elemental theories: Four Quadrant Models: The History of DISC.
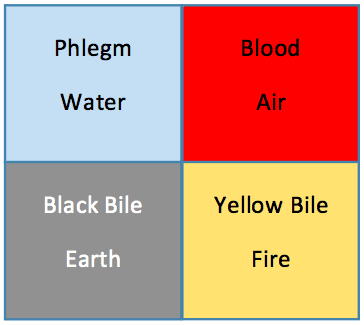
Dan Katz, in Re DISC – How Swedes were fooled by one of the biggest scientific bluffs of our time, really hates the DISC model, and provides an extensive literature review of why it’s suspect, although there are no actual scientific studies of the DISC model per se. So it might have weak evidence but could nonetheless be correct by accident.
3.2 Hogwarts houses
Also popular, and similarly based on the four elements.
For the record, I am Ravenclaw with Slytherin ascending. I didn’t particularly enjoy Harry Potter.
3.3 Big-5 personality traits
How are the Big Five supposed to work? How did researchers choose five? We’d like to know. 🤷♂ As an outsider who knows little about this area, (except that there are between four and six personality traits in discussions around the Big Five) I assume the traits aren’t particularly arbitrary and have arisen naturally from data as identifiable, predictive latent variables.
The acronym OCEAN is used for the traits: Openness to experience (sometimes called “intellect” or “imagination” or “open-mindedness”), Conscientiousness, Extraversion (sometimes called “surgency”), Agreeableness, and Neuroticism (sometimes called “negative emotionality” or “emotional stability” reversed).
a literal banana snarks to the contrary.
Those who are skeptical of the Enneagram are usually Type 6, and those who are skeptical of astrology are usually Tauruses. Similarly, those who criticize the Big Five are typically low on extroversion, high on conscientiousness, low on agreeableness, and high on neuroticism (openness to experience can go either way, I suppose).
We might raid the list of references there to see what’s going on, and also check the comments which go into detail and offer some rebuttals.
The Big Five exist as a special, scientifically validated property of language and survey methods, and that is one basis for their legitimacy. The other basis for the legitimacy of the Five Factor Model is its replicable correlation with consequential life outcomes. We know that the Big Five are not merely phantoms that fall out of a certain analysis of a certain use of language in WEIRD college students, because these traits are reliably correlated with things we care about.
The Replicability Index goes deeper into how these models work—or don’t—by examining the identifiability assumptions in one paper: More Madness than Genius: Meta-Traits of Personality.
The new analyses of the results suggest that the published model is misleading in several ways.
- Plasticity is not a negative predictor of Conformity
- Stability explains 30% of the variance in Conformity not 100%.
- The correlations of Agreeableness, Conscientiousness, and Neuroticism with Conformity are not spurious (i.e., Stability is a third variable). Instead, Agreeableness, Conscientiousness, and Neuroticism mediate the relationship of Stability with Conformity.
- The published model overestimates the amount of shared variance among Big Five factors because it does not control for response biases and made false assumptions about causality.
tldr it’s methodologically complicated, so we should expect that something useful can come out of it.
The ClearerThinking.org team attempts to construct an omnibus personality test: Announcing the Ultimate Personality Test 2.0!.
The results provide a fascinating case study of the idea of learning as compression and the shallowness of classifiers.
3.4 Astrology
12 categories; I’m not sure how many factors are implied by each.
4 Incoming
- No, Conscientiousness Hasn’t Collapsed Among Young People in Recent Years
- IQ discourse is increasingly unhinged – Seeds of Science
- How accurate are popular personality tests at predicting life outcomes?
- Increasing IQ is trivial — by George reports experiments that apparently succeeded in shifting his IQ.
- Revised NEO Personality Inventory is asserted by Gwern to be contentful.
- IQ Cults, Nonlinearity, and Reality: a Bird-watcher’s Parable
- Item response theory is what psychologists call a model with a logistic likelihood and a latent variable mediated by mixed per-question effects.
- The Evaluative Factor in Self-Ratings of Personality Disorder: A Threat to Construct Validity
- Ultimate Personality Test 1.0 Types
- Announcing the Ultimate Personality Test 2.0!
5 References
Footnotes
Aside: he also propounds a solution which looks a bit like a causal graph, “A better answer to the doctors’ question would involve, not the opium alone, but a relationship between the opium and the people.”↩︎