Zotero
The adequate citation tool
2019-12-01 — 2026-05-27
Wherein a Browser Plugin Is Employed to Capture Article Metadata and PDFs in a Single Click, BetterBibTeX Citation Keys Are Generated, and Local REST APIs Are Described.
Zotero — my weapon of choice for citation management.

The value proposition of Zotero is best demonstrated with the browser plugin:
- I visit an article in my browser.
- A button appears in the menu bar that imports the article into my literature database.
- I click the button, and the article’s metadata magically appears in my database…
- … with a copy of the PDF if I have access (and another button to search for free copies if I don’t).
After a while, I accumulate a big, interactive, searchable database of references, with a nice user interface and browsing tools. From there, I can do all kinds of useful stuff, like export to various formats such as BibTeX. I can render bibliographies directly in my word processor. We can read the manual for a comprehensive list, or check out the other manual.
Zotero has an API that lets us query, read, and write bibliographic entries in our database, so it’s easy to script automatic updates and such. I don’t feel like I’m locking my data away with an untrusted third party when I rely on it. Of course, we can try to migrate data between tools by importing and exporting to BibTeX or similar, but if there are URLs in the article metadata, or if we work with people who have diacritics in their names, this leads to trouble. The Zotero API doesn’t have those problems. Moreover, some other apps (Mendeley, …) already use the Zotero API, so we know it’s battle-tested.
1 BetterBibTeX
Better BibTeX, aka BBT, smooths out the BibTeX workflow in Zotero, and since BibTeX integrates with Markdown via pandoc, that’s a double win.
1.1 Citation keys

The main trick is that BBT creates sensible, user-accessible citation keys for my references. If I use them consistently to refer to my sources, life goes well for me.
The citation keys are generated automatically from a format string. Of course, there’s no guarantee my colleagues will agree on a sensible standard for citation keys; that problem is perennial.
My citation key format strings for BibTeX are in the old syntax (there’s a new syntax; I need to migrate them).
🚧TODO🚧: Check how this handles diacritics.
So, say we’d like to cite the classic
Ingrid Daubechies (1988) Orthonormal bases of compactly supported wavelets. Communications on Pure and Applied Mathematics, 41(7), 909—996. DOI.
Those citation key formulae above mean I can refer to this work as Daubechies1988Orthonormal. I can then cite it in LaTeX as \cite{Daubechies1988Orthonormal}, in markdown as \@Daubechies1988Orthonormal, and presumably in other systems that use different syntax.
1.2 Exporting BibTeX files via BBT
See also URL export of a BibTeX file.
Zotero can also generate the bibliography database for any given folder (e.g. a .bib file), and it can optionally keep that file updated as I add more articles. That’s a pretty nifty feature, but I found it easier to write my own script to do updates on my schedule, rather than rely on magic.
I’m fond of excluding the following BibLaTeX fields from export to keep the output small and dense.
BBT supports HTTP-pull export, which means grabbing an up-to-date .bib file is just an HTTP request. For example, http://127.0.0.1:23119/better-bibtex/collection?/1/citation_management.biblatex pulls all the records in the citation_management collection, and it runs against my local copy of Zotero, so it’s fast and reliable compared to the Zotero cloud server API, which depends on my internet connection. I use this feature all the time, mostly to handle referencing in this very blog. In fact, I automated it with a custom BibTeX export script.
The pull export works better for me if I set the advanced preference fine as it is these days.extensions.zotero.translators.better-bibtex.sorted to true so that the reference sorting is consistent, otherwise it seems to be random each time
Recently I’ve noticed that exporting as yaml rather than bib is more consistent across platforms, so I use that as the canonical storage format. Either format works fine for blogdown, which this blog uses.
BBT even supports scripting via JavaScript now.
CSL is close to being good for use on websites, but has a flaw: They do not support links, in the sense that there is no general way in the standard to tell a CSL renderer where to anchor a hyperlink, how to style it etc.1 There is a hack that may support some use cases, although it is not ideal for mine. This is not to say links are impossible; merely that CSL regards the web as a second-class participant in world of information and affords it merely clunky second-class support. If I want something different than the fairly ugly default, I need to write my own CSL processor with some idiosyncratic, site-specific custom URL handling built in, which presupposes I have access to the source code of whatever tool I use and would like to spend time maintaining a fork of it.
I interpret this to mean that the creators of CSL imagine that we are only using it for writing stuff to be printed out on paper, and that it is not worth introducing any conveniences for the mere passing fad that is internet-based communication. This feels reactionary — I literally have not seen a paper journal for years now — but I guess that really nice paper citations is what these passionate volunteers have identified as the first stop on their journey. I choose jump out and swim the last mile to the beach alone rather than spending any more time lobbying to change the destination of the ship.
1.3 Interactive citation finding
BBT supports a Cite-as-you-write interaction: a GUI pop-up citation finder for generic editors. I don’t use it because I export my citations to a BibLaTeX file on disk via an HTTP pull (below), and the editors I use already support smart citations from that file.
citr provides an interactive citation finder for RStudio that works with BetterBibTeX.
I don’t use it because I don’t like RStudio.
Recent versions of Zotero include a new citation processor, citeproc-rs. Evaluation: TBD.
2 Hacking
I promised that Zotero’s selling point was its hackability. So I should mention how we go about hacking it. One confusing thing is that Zotero has two parts that work together.
- There’s the Zotero service, run on a George Mason University server farm somewhere.
- There’s a client, the Zotero app, that runs on my machine. Confusingly, the client can also run its own local web server.
Both parts have their own APIs; many tasks can be accomplished through either, and some only through one. There are pros and cons to each.
2.1 Server side
The server side of Zotero has an internet-facing Web API. The upsides are that
- I can use my language of choice, not just JavaScript, to do things.
- It’s simple; there’s no messing about with the complicated build chain of JavaScript apps.
However, it is
- slow.
- limited,
- doesn’t have access to the UI, just the server-side data.
Nonetheless, it’s an easy way to get certain stuff done, such as mass-updating tags, fixing spelling, or similar. I use it for data cleaning — e.g., I have a script that walks through the collection, looks for suspect citation IDs, and deletes them.
I’m currently writing a new script to sync tags and collections (i.e. putting an article in a collection called gp_regression will also tag it with gp_regression).My justification is that the UIs are deficient in different ways: e.g. I can’t search for articles by intersection using folders (i.e. being in two folders) but I can with tags. On the other hand, actually assigning tags is gruelling because the UI requires way too much dragging and dropping of tiny widgets. Zotero 7 makes it easier to see which other collections a given article is in, which is half the battle.
2.2 Local API server
Since Zotero 7, the desktop app ships a built-in REST server at http://localhost:23119/api/. It’s a read/write interface to the local Zotero database — not a sync server, not a self-hosted cloud replacement, just the library in the running app exposed over HTTP. The Zotero team’s stated goal is to mirror the Web API as closely as possible, so tools built against api.zotero.org can be pointed at localhost instead.
To enable it: Edit → Preferences → Advanced → Allow other applications on this computer to communicate with Zotero.
Standard CRUD operations on items, collections, tags, and searches work as expected, though I haven’t tried everything. What’s absent: versioning and sync-conflict semantics (no need — it’s local), and some attachment operations differ since there’s no cloud storage backend. The desktop app must be running for any of this to be available, obviously.
pyzotero supports the local API natively since v1.5.27 — just pass local=True when initialising, which allows us to skip API keys and user/library IDs:
For my use case — scripting cleanups and tag management against the local library — this is faster and more reliable than hitting the cloud API. The MCP server and its CLI talk to this same local server under the hood. BetterBibTeX HTTP-pull export also maybe?
2.3 Client side
The client has a JavaScript API, as it’s essentially a JavaScript app. I could use this to develop plugins and such, but I don’t have time — for me this is definitely yak shaving.
Mini-trick: I can execute JavaScript manually for one-off tasks, e.g. batch editing.
I briefly tried using the client API to write a custom exporter for Zotero. I didn’t finish because BetterBibTeX already does what I wanted.
Nonetheless, if I wanted to reinvent the wheel or do something new, here are the overview docs, detail docs, and all the code.
The last time I tried this, I ran into one problem: writing output formats that need a unique citekey for each item in the bibliography. Here is a simple example that tackles the citekey issue (albeit using an outdated citekey system). Here is a soothing walk-through of the whole process. Once again, BBT solves that problem, so I won’t spend any more time on it.
2.4 Translation server
The Zotero translation server is a Node.js HTTP server that exposes Zotero’s bibliography translators as a local REST API — i.e. without a full Zotero server app, a browser, a GUI, or a Zotero client. The pitch is: POST a DOI, PMID, ISBN, or arXiv ID and get back structured citation metadata — no Zotero app, no browser, no GUI.
The main use case is scripted or batch citation fetching. Say I have a list of 100 DOIs I want to turn into BibTeX; the translation server handles it without any manual clicking.
Setup (requires Node.js and Git):
Quick test:
All four endpoints use POST requests to http://127.0.0.1:1969:
| Endpoint | Input | Use |
|---|---|---|
/search |
DOI, ISBN, PMID, arXiv ID | Fastest; hits metadata APIs directly |
/web |
A URL | Scrapes pages for citation data |
/export |
Zotero JSON | Converts to BibTeX, RIS, etc. |
/import |
BibTeX, RIS, etc. | Converts to Zotero JSON |
/search is the workhorse. /web is slower and more fragile, but it can extract metadata from pages that don’t expose a clean identifier.
Keeping it running — three options, listed below in ascending order of actual pain.
They recommend Docker. I kind of hate Docker though because it feels needy and bloated. OrbStack + Docker is a clean-ish local option. OrbStack is a lightweight macOS container runtime (~200 MB, free for personal use), and then it’s basically just:
No Node.js versioning headaches — it’s fully self-contained and reproducible on a new machine.
AWS Lambda is nominally a pretty zero-maintenance option. The repo ships first-class Lambda support — a deploy script, SAM template, and everything else:
After that, our scripts point to the API Gateway URL instead of localhost:1969. The free tier covers personal scripting volumes easily, and it survives brew upgrade node without any intervention.
Except it doesn’t work for me. The deploy script needs weird global Python dependencies and manual config updates.
pm2 + launchd sounds appealing, but it’s fragile on Homebrew Macs: pm2 startup hardcodes the current Node.js Cellar path (e.g. /opt/homebrew/Cellar/node/25.8.0/bin) into the generated plist, which silently breaks after any brew upgrade node. I do not have the attention span for that.
Batch lookups — add e.g. sleep 1 between requests, or remote services rate-limit us:
The translation server ships thin curl wrappers (translate_search, translate_url, translate_export) that we can symlink into /usr/local/bin for convenience — though they don’t start or stop the server, which needs to already be running.
Take care! This is an open HTTP server with no auth, so make sure that no one can hit it from the network.
2.5 MCP server
54yyyu/zotero-mcp connects a Zotero library to Claude (and other MCP-compatible AI assistants) as a first-class tool. The upshot is that agents (e.g. Claude) can search, read, and write to our Zotero library conversationally — no scripting required. For example: “find papers tagged gp_regression that I’ve annotated” or “add this arXiv URL to my neural networks collection” — just as a natural-language request to Claude.
Installation requires Python 3.10+, Zotero 7, and “allow other applications on this computer to communicate with Zotero” enabled in Preferences → Advanced:
uv tool install zotero-mcp-server # minimal or
uv tool install zotero-mcp-server[all] # with all extras
uv tool install --reinstall "zotero-mcp-server[all] @ git+https://github.com/54yyyu/zotero-mcp.git@main" # reinstall bleeding edge
zotero-mcp setup # auto-configures Claude Desktop, search indicesor just, like,
This command automatically writes the MCP entry into claude_desktop_config.json. For manual configuration:
ZOTERO_LOCAL=true points the tool at the local Zotero app rather than the cloud API — faster and works offline, but doesn’t have write access. The Zotero app must be running for any of this to work. BetterBibTeX is recommended: without it, citation-key lookups won’t function.
The tool suite does keyword and tag search, BibTeX export, full-text retrieval, PDF annotation extraction, adding papers by DOI or URL, batch tag operations, and duplicate detection. The upshot is that I can ask my agent all kinds of questions about my library, such as:
- “Export BibTeX for everything I’ve tagged
kernel_methods” - “Add DOI 10.1038/nature12373 to my “reading list” collection”
- “What have I annotated in the three papers on diffusion models I read recently?”
- “Find papers conceptually related to variational inference” (requires the semantic search extra)
For semantic search, install the extra and build the index:
It generates embeddings locally by default (all-MiniLM-L6-v2 via ChromaDB); we can swap in OpenAI or Gemini embedding models via environment variables if we want better quality at a cost (and that only works online).
2.6 CLI
That selfsame MCP package now ships a standalone terminal client, zotero-cli, alongside the MCP server — so if I installed zotero-mcp, I already have it. It exposes the same tools without an AI assistant in the loop, and shares the configuration that zotero-mcp setup writes: the same local API, the same fall back to the web API for writes.
zotero-cli search "machine learning" # keyword
zotero-cli search --mode semantic "attention" # needs the semantic index (above)
zotero-cli search --mode tag "important,reviewed"
zotero-cli get metadata ABC123 --format bibtex # BibTeX for one item
zotero-cli add doi 10.1038/s41586-021-03819-2 # metadata + open-access PDF cascade
zotero-cli add url https://arxiv.org/abs/2301.00001
zotero-cli notes create --item-key ABC123 --text - # note from stdinAlternatively,
Why use a CLI at all, when there’s already an MCP server and a perfectly good local API underneath both?
In fact, the CLI is probably strictly better. MCP tool schemas cost context-window tokens every session, whether or not I end up touching Zotero. A shell command costs nothing until I run it and it pretty simple. Most agents that can invoke the MCP can also invoke the CLI, and probably more efficiently. In addition the zotero-cli is useful even when I’m not using an agent at all — e.g. for quick one-off lookups, or to script batch operations in a shell script etc.
Like pyzotero it is another way of consuming the local API, except I don’t have to write the Python. add doi and add url run the same open-access PDF cascade (Unpaywall, arXiv, Semantic Scholar, PMC) as the MCP tools, which overlaps with the identifier-to-library plumbing I laboriously built for the finicky translation server. Currently investigating whether I can retire any of that infrastructure, which means I need to work out if all the things I need (named collection searches) are supported by the CLI.
3 Installing
3.1 Windows or macOS or iOS
Easy — we can use the standard installers.
3.2 Linux
More tedious. retorquere’s repo of deb installers is a simple option for Debian/Ubuntu.
For non-Ubuntu systems… we can try a packaged version. There’s a snap-app package. The weird paths within snaps mean I’d have to do a lot of configuration to migrate to it if I wasn’t already using a Snap version. It began to feel like yak shaving, so I didn’t finish the migration and can’t report on it. There’s a cross-platform Flatpak Zotero, with the usual caveats about Flatpak.
All of the above options have only been maintained intermittently. For me, it’s been worth manually installing this app because I use it all day and want it to work reliably.
cd ~
wget 'https://www.zotero.org/download/client/dl?channel=release&platform=linux-x86_64'
tar -xjf '/home/dan/Downloads/Zotero-5.0.96_linux-x86_64.tar.bz2'
cd ~/Zotero_linux-x86_64/
./set_launcher_icon
ln -s ~/Zotero_linux-x86_64/zotero ~/bin/
ln -s ~/Zotero_linux-x86_64/zotero.desktop ~/.local/share/applications/3.3 Android
See the mobile app section.
3.4 Use the web app instead
There’s a web app with useful features, so we can skip installing the full Zotero app: ZoteroBib: Fast, free bibliography generator.
ZoteroBib helps you build a bibliography instantly from any computer or device, without creating an account or installing any software. It’s brought to you by the team behind Zotero, the powerful open-source research tool recommended by thousands of universities worldwide, so you can trust it to help you seamlessly add sources and produce perfect bibliographies. If you need to reuse sources across multiple projects or build a shared research library, we recommend using Zotero instead.
4 Tablet/e-reader
We can read on the Zotero.org website. It works, but it’s not ideal. A native app would be better.
On iOS, there’s a native app I like. On Android, the native app wasn’t as good last I checked, but that was when it first came out
The Zotero mobile page tracks the latest updates.
- Official iOS app (check the App Store)
- Zoo
- ZotEZ² claims to support non-standard sync
- zandy
- Papership (third-party iOS) looks neat.
4.1 Syncing files to mobile
We can use no mobile client at all and just read a folder full of PDF files. I’ve used the Zotero plugin Zotfile to synchronise a folder full of attachments to my tablet. It’s not perfect, but it’s simple and robust, and plenty of apps can browse a folder of PDFs. NB: Zotfile is discontinued, so it will eventually stop working. Maybe Zotfile can be replaced by retorquere/zotero-opds, which synchronises via OPDS. Hmm, that project seems to have stalled. Watch this space for updates (e.g. MuiseDestiny/zotero-file, a reimplementation).
Settings note: I use Zotero’s rename feature with the rename string {%av}{%y }{%t}.
5 Blog integration
tl;dr. There are plenty of over-engineered solutions for getting Zotero citations into a blog post. I use blogdown with Better BibTeX export. Read on for other alternatives.
5.1 Via Better BibTeX and blogdown
See Better BibTeX export.
5.2 Zotero-mdnotes
A Zotero plugin to export item metadata and notes as markdown files.
A possible competitor is the more feature-rich windingwind/zotero-better-notes.
5.3 Via CSL
CSL is a citation-rendering mini-language used by modern journals and software to describe their house styles. I can use it too.
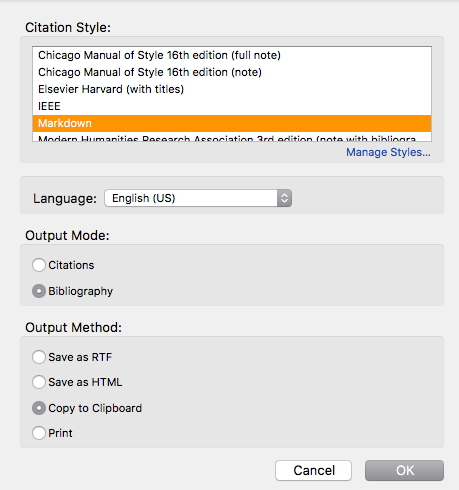
This is a slightly weird way to get plain-text citations: CSL is a system for instructing citation software how to render citations in a rich-text word processor, but we can force it to output plain text or Markdown. It’s robust and simple. There’s a CSL editor online so this is easy-ish. One catch: I wanted my BibTeX citation keys so I could refer to them. But BibTeX keys aren’t exposed to CSL, so this doesn’t work. As far as I can tell, this is built into the CSL spec.
CSL has a citation-label variable, but it doesn’t match the BibTeX keys generated by BBT, which is annoying.
Here’s my docutils/ReST style file,
restructuredtext.csl, which renders citations as plain text with ReST markup, including anchor links.It’s ugly because it has to battle with a grumpy rich-text XML infrastructure to render plain text, but it gets the job done without any coding, and it’s robust against software changes.
Similarly, here’s my Markdown style file,
markdown.csl, which likewise renders citations as plain text with Markdown markup, including anchor links.Emiliano Heyns has a BibTeX key CSL hack, which renders his particular preferred citekey
\{LeDT06}by reimplementing the BibTeX key generation (sadly, it doesn’t quite match mine.)
5.4 Dynamic bibliography generation in situ
Erik Hetzner’s zotxt can avoid the need to create .bib files, rendering bibliographies directly by querying the Zotero app rather than creating an intermediate file. I don’t mind keeping the intermediate file around because it’s shareable, so I haven’t pursued this.
6 Better in-Zotero lookup
The default Zotero lookup engine uses Google Scholar with strict date matching and strict author first name matching, which produces many false negatives. I revised the engines.json file to do better searching. On macOS, for me this is
Instead of just using the default search…
[
{
"_name": "Google Scholar",
"_alias": "Google Scholar",
"_description": "Google Scholar Search",
"_icon": "file:///Users/mac581/Zotero/locate/Google%20Scholar%20Search.ico",
"_hidden": false,
"_urlTemplate": "https://scholar.google.com/scholar?as_q=&as_epq={z:title}&as_occt=title&as_sauthors={rft:aufirst?}+{rft:aulast?}&as_ylo={z:year?}&as_yhi={z:year?}&as_sdt=1.&as_sdtp=on&as_sdtf=&as_sdts=22&",
"_urlParams": [],
"_urlNamespaces": {
"rft": "info:ofi/fmt:kev:mtx:journal",
"z": "http://www.zotero.org/namespaces/openSearch#",
"": "http://a9.com/-/spec/opensearch/1.1/"
},
"_iconSourceURI": "https://scholar.google.com/favicon.ico"
}
]I added these bonus entries:
{
"_name": "Relaxed Google Scholar",
"_alias": "Relaxed Google Scholar",
"_description": "Google Scholar Search with sloppy matching",
"_icon": "https://scholar.google.com/favicon.ico",
"_hidden": false,
"_urlTemplate": "https://scholar.google.com/scholar?as_q=&as_epq={z:title?}&as_occt=title&as_sauthors={rft:aulast?}",
"_urlParams": [],
"_urlNamespaces": {
"rft": "info:ofi/fmt:kev:mtx:journal",
"z": "http://www.zotero.org/namespaces/openSearch#"
},
"_iconSourceURI": "https://scholar.google.com/favicon.ico"
},
{
"_name": "Semantic Scholar",
"_alias": "SemanticScholar",
"_description": "Search on Semantic Scholar by title and first author's last name",
"_icon": "https://www.semanticscholar.org/favicon.ico",
"_hidden": false,
"_urlTemplate": "https://www.semanticscholar.org/search?q=\"{z:title?}\"+{rft:aulast?}",
"_urlParams": [],
"_urlNamespaces": {
"rft": "info:ofi/fmt:kev:mtx:journal",
"z": "http://www.zotero.org/namespaces/openSearch#"
},
"_iconSourceURI": "https://www.semanticscholar.org/favicon.ico"
}7 Advanced bibliographies
Zotero’s commitment to CSL for its bibliographies is… meh. Better BibTeX lets us extend Zotero’s bibliography system with custom exporters, so we can squeeze a little more data into the output. For example, the following script shows how to turn Zotero tags into BibTeX keywords and export a bibliography with those tags as “keywords” fields.
8 Promising plugins
Auditioning:
- windingwind/zotero-actions-tags: Action it, tag it, sorted., especially [Share] QuickCopy items
- windingwind/zotero-better-notes: Everything about note management — all in Zotero.
- scitedotai/scite-zotero-plugin: scite Zotero plugin
- PubPeerFoundation/pubpeer_zotero_plugin: Shows if references in Zotero have PubPeer comments
- retorquere/zotero-storage-scanner: A Zotero plugin to remove broken and duplicate attachment links from the bibliography
9 Pro tips and gotchas
9.1 Use an existing folder of PDFs
Want to integrate an existing folder of PDFs? Don’t want to use Zotero’s storage system? Richard Zach points out how to do this.
… you keep your PDF directory synced across computers (e.g., if it lives in your Dropbox), linking the PDFs is just as good. If you add a PDF, Zotero will look up the metadata for you and add a reference to your database.
I did this for a few years. Plus: it’s cheaper than Zotero’s cloud storage. Minus: it won’t sync with Zotero’s web or mobile apps.
See also Ilya Kashnitsky’s post, Zotero hacks: unlimited synced storage and its smooth use with rmarkdown.
9.2 Quick Copy shortcut breaks
Occasionally (for me, frequently), the Quick Copy keyboard shortcut breaks. By default, the shortcut is Ctrl-Shift-C. This is usually fixed by restarting Zotero. We can also enter the following in the developer console:
It doesn’t solve a related problem that comes up on Ubuntu 20.04, where Ctrl-Shift-C is a controversial key combination and triggers weird behaviour that’s never what I’m after. That key combination launches a terminal in VS Code even though I’ve disabled that shortcut. It never does anything in Zotero. It’s annoying but not crippling, so I won’t go down a rabbit hole debugging GNOME keyboard shortcuts. I reassigned the shortcut to Ctrl-Shift-B, and it seems to work better so far.
9.3 Why are my dates in US format?
On macOS, Zotero is sometimes sycophantically eager to use the US date format, despite US English being nowhere in my localisation preferences. This makes me look like I think there are 31 months in a year when I use it in Australia. The following settings I found on the user forum seem to help:
9.4 URL export
Zotero exposes URLs for public groups, which we can include in Overleaf documents.
The zotero url trick was proposed by one christian_moedrup_legaard on this page
I learned this from Laurence Davies.
Footnotes
More generally, it has has chosen not to support various metadata beyond a conservative set; so bibtex keys and topic tags are also off the list.↩︎