Synchronising files across machines
Dropbox for Dropbox haters
2015-01-02 — 2022-12-12
Wherein Peer-to-Peer and Host-Based Tools Are Surveyed and a Recommendation of Syncthing for Local Peer Syncing and Rclone Encryption-Backed Bridges to Cloud Storage Is Presented.
Related: backing up data.
Purely cloud-based network drives just aren’t awesome at fast or distributed work. Realising this is why the Dropbox founders are now rich. They invented a thing which keeps the files locally and syncs them with your co-workers online. Well done them.
However, Dropbox’s solution, as groundbreaking as it was, is also unsatisfactory, being hamstrung by technical and legal shortcomings. Same goes for the Google and Microsoft options. These services creepily read my documents in the name of convenience. However well-intentioned it may be, it does not change the fact that this is by nature not secure, and increases the risk that my stuff will be exposed in a breach, or sent to whichever agency would like to read it in whichever jurisdiction has the weakest protection for confidentiality.
Historically the Dropbox client app used to do all manner of suspicious things to further undermine my trust; enough suspicious things that I will never trust them. TBH I am not so excited I can be bothered going in to see if it is still happening or not; there are other alternatives. Suffice it to say, I am not keen to opt in to their nonsense. How can I get something like Dropbox without all the security holes and creepy behaviour?
Peer-to-peer synchronising (i.e. no special server at all) is one robust option and I do a lot of this. I then have no 3rd party helping me, which is a plus and a minus. Plus: I can feel safer. Minus: I do not synchronise if my computers are not simultaneously online.
Taking it further, how about everything be sneakernets?
Or I can use some hacks to make Dropbox less awful, by e.g. encrypting my files to inhibit potential Dropbox data mining, and by using alternative clients that are less suspect and so on.
Pro tip: some of these options can be made easier to set up if one used a VPN from the house, maybe even a cheeky mesh-vpn system like tailscale.
1 Syncthing
Choose this if… You have a collection of various folders that you need shared to various different machines, and you would like many of the different machines to be able to edit them. You don’t need a server and thus you are happy for syncing to happen if and when the peers are online. And you don’t care about iOS. And you don’t mind wasting a few CPU cycles. I use this for synchronising my music production files across my studio machines, studio backup machines and gig machines.
I am all in on Syncthing. I install it on every machine I use regularly. It makes my life much better.
I have a whole notebook of deep tips about it — see syncthing.
2 Opencloudmesh
TBD. Some kind of system to replicate/share across different other sync services. Currently supports Nowtcloud and seafile. I am not sure how it works with host-proof encryption.
3 Seafile
Choose this if… You have a collection of various folders that you need to synchronise between macOS, Windows, Linux, Android and iOS. You don’t mind installing or paying for a central server to coordinate all this.
Seafile is an open-source file sync service with a premium enterprise server with more features available for a fee. It has clients for browsers and desktop and mobile. Semi-host-blind encryption is available but optional and doesn’t work from browsers or encrypt metadata. FWIW it looks simpler than Nextcloud to install manually, (there is even an automatic script) although in either case it’s easiest to run pre-made docker images. You can build your own; this starts to feel like a looot of work. You would use this if you wanted a convenient iOS client, which is otherwise tricky to get. I would happily pay for a hosted version of this if there was one available, but there isn’t. Supports Open Cloud Mesh.
4 Peergos
Peergos is a sort-of file sync based on IPFS. Currently they do not seem to support me using my own storage, but rather I need to pay them money to use their centralised filestore based on a decentralised protocol. I am confused about what the point of that would be; classic decentralised rhetoric struggling to find a business model? I am quite happy to pay them money but also, what if I want to have a terabyte of shared data on a spare hard drive sitting idle? I have not inspected the source-code but this might be something almost like file sync, in that it does not really sync the files but it does cache them and provide a virtual FS onto the wacky cached distributed FS, or something.
5 dat
Choose this if… You have a large data set that you wish to share amongst many strangers, and if there is a single source of truth. I would use this for sharing predictably updated research, although not distributed research.
Dat is similar to syncthing, with a different emphasis — sharing data to strangers rather than friends, with a special focus on datasets. You could also use it for backups or other sharing. See Dat/data versioning.
NB it’s one-writer-many-readers, so don’t get excited about multiple data sources, or inter-lab collaboration. For this price, though, you get data versioning and robust verifiability, which is a bargain.
The flagship dat client is no longer prominent (or visible at all?) on the home page so I am slightly suspicious about the viability of this project right now. Maybe wait for it to settle down first.
6 Mega
Choose this if… You want to share files, chats, data and whatever else, with people who can’t or won’t install their own software and so must use a browser to download stuff, and if you don’t care that the company behind it is dicey. e.g. I used this for some temporary file sharing music collaboration projects, but now that those are over, I’ve deleted the app.
Mega Easy to run. Public source, but not open source. (Long story.) Host-blind encryption business from New Zealand.
Anyway it’s relatively easy to use because it works in the browser, so it won’t terrify your non-geek friends. Ok, maybe a little. Much cheaper than Dropbox, as well as being probably less creepy. The UI is occasionally freaky but it’s reasonably functional, especially for its bargain-basement price. A… unique?… tradeoff of respectability, privacy and affordability.
7 Rclone
Choose this if… You want to infrequently clone some files somewhere, collaborate with people who use different sync solutions, or because you want a Swiss army knife fallback solution.
Rclone is a command line program to copy files and directories to and from various cloud sync solutions such as Google Drive, Amazon S3, Memset Memstore, Dropbox etc. For some of these services it is the only Linux client. It is not actually a sync client per se, in that it does per default mirror the files to a local drive in a background process. Instead it does more general stuff, operating on miscellaneous remote storage; it can sync files, but also it can do other things with those files.
I keep rclone around because it lets me plug into pretty much anything into pretty much anything else, e.g. accessing my Microsoft OneDrive from the campus Linux cluster. Also because my colleagues don’t agree on which provider to use, and I don’t have enough money, time, or trust to run them all (Dropbox, Google Drive, Onedrive and Mega…), but rclone lets me sync between them as needed.
Pro-tip: the encryption module turns any unencrypted file storage (Looking at Dropbox) into an encrypted one, even local file storage (!) It is thus a convenient UI for encrypting things.
Pro-tip: It can also mount remote cloud storage on my local machine without downloading contents, which is handy, although it can be ungainly and slow. Apparently one can set up caching but… oh my this is getting complicated now isn’t it?
Features:
- MD5/SHA1 hashes checked at all times for file integrity
- Timestamps preserved on files
- Partial syncs supported on a whole file basis
- Copy mode to just copy new/changed files
- Sync (one way) mode to make a directory identical
- Check mode to check for file hash equality
- Can sync to and from network, e.g. two different cloud accounts
- Optional encryption (Crypt)
- Optional FUSE mount (
rclone mount)
Cons: manual synchronising, the default rclone mode, means that we need to remember to synchronise files, but that means we have another task to remember to stay up to date with updates to the files we care about. OTOH, this is not really a con for some uses. We can script file downloading in our build step, which is what we want for some projects.
I could read the manual, but everything seems to work great for me if I set it up by running
We can do lots of things from that configuration stage. bisync is my current favourite:
My most common use for rclone is synchronising to dropbox from some more salubrious management system such as git.
8 Owncloud/Nextcloud
Choose this if… your campus runs a giant free Owncloud service so you may as well use it. Owncloud and Nextcloud are two forks of the same codebase. Nextcloud seems to be hipper. They both look similar to me. Since I encountered Owncloud first I mention it here; the differences seem philosophical but not especially practical.
For clarity where I am referring to both I will describe the resulting superposition as Nowtcloud.
Nowtcloud is dubiously secure; they have security advisories all the time. Also the server doesn’t store files encrypted, so I get an increased ease of sharing files (no extra password needed) but decreased confidentiality in case the server is compromised. Lawks! That’s barely better than Dropbox!
OTOH, it’s possible to run on my own Nowtcloud server, e.g. using docker, so it’s useful for sharing something public such as open research etc for only the cost of hosting, which is low. However, if I want to do this, Seafile seems to be better software for the file sharing use case and is no harder to set up, so why not try that?
The real reason would be that someone else has gifted me pre-configured Nowtcloud service. Australian academics get a generous serving of storage from AARNET, a terabyte I think, so we may as well.
However, there are various quirks to survive.
For one, native command-line usage is not obvious. How do I access my stored data files from your campus cluster?
First, we can access it as a WebDAV share, which is unwieldy but probably works. WebDAV is effectively making things available on a webserver, which sounds like it should be simple, but in practice we need a special client to do it because there are lots of fiddly details. e.g. we want to browse the folders to find the file, or we want to handle authentication etc. Boring.
Nowtcloud notionally has a command-line client, but the CLI documentation is hidden deeply, possibly because it’s not very good (neither documentation nor the CLI). Tony Maro gives a walk-through. It’s sensitively version dependent. Beware.
There are also version clashes between different versions of Nowtcloud, and when I sync a folder with some other service, occasional silent data loss. I’m not a fan of this whole project.
If I need to get data out of Nowtcloud from the command line I should extract it using rclone’s WebDAV mode and ignore Nowtcloud itself. It’s convenient that someone runs Nowtcloud code on some server somewhere, and I do in fact store a bunch of non-confidential data sets there. But the less of the Nowtcloud code I myself run, the better this has worked for me thus far.
9 git-annex
Choose this if… you are a giant nerd with harrowing restrictions on your data transfer and it’s worth your while to leverage this sophisticated and yet confusing bit of software to work around these challenges. E.g. you are integrating sneakernets and various online options. Which I am not.
git-annex supports explicit and customisable folder-tree synchronisation, merging and sneakernets, and as such, I am well disposed toward it. You can choose to have things in various stores, and to copy files to and from servers or disks as they become available. It doesn’t support iOS. Windows support is experimental. Granularity is per-file. It has a weird symlink-based file access protocol which might be inconvenient for many uses. (I’m imagining this is trouble for Microsoft Word or whatever.)
Also, do you want to invoke various disk-online-disk-offline-how-sync-when options from the command line, or do you want stuff to magically replicate itself across some machines without requiring you to remember the correct incantation on a regular basis?
The documentation is nerdy and unclear, but I think my needs are nerdy and unclear by modern standards. However, the combinatorial explosion of options and excessive hands-on-ness is a serious problem which I will not realistically get around to addressing due to my to-do list already being too long.
11 Handrolled rsync
TBD
12 Handrolled unison
13 Dropbox if you must
Choose this if… you don’t mind giving access to your data to dubious strangers with little regard for your security and some of your colleagues are totally hooked on it.
I talk about Dropbox here, but also GDrive and whatever the Windows thing is called do it too.
See dropbox if you must.
14 Upspin
Choose this if… you prize elegance above comprehensibility and intermittently descend from the heights of your research program in abstract category theory to quotidian normalcy in order to share files.
Upspin is hard to explain, specifically because I don’t understand it. It’s not really a sync service (I think) but it fills some of the same niches. Rclone on steroids, with a server process, something like that?
When did you last…
- download a file just to upload to another device?
- download a file from one web service just to upload to another?
- make a file public just to share it with one person?
- accidentally make something visible to the wrong people?
Upspin is an attempt to address problems like these, and many more.
Upspin is in its early days, but the plan is for you to manage all your data—even data you’ve stored in commercial web services—in a safe, secure, and sharable way that makes it easy to discover what you’ve got and who you’ve shared it with.
If you’d like to help us make that vision a reality, we’d love to have you try out Upspin.
Upspin is an open-source project that comprises two main design elements:
- a set of protocols enabling secure, federated sharing using a global naming system; and
- reference implementations of tools and services that demonstrate the capabilities.
Summary: It backloads encrypted, permissioned (?), storage into arbitrary backends including cloud providers. Maybe.
15 Others
SpiderOak was the most popular encrypted service last time I checked. It is based in the USA, which, like Russia and China, is more of a secret service browsing library than a secure document store where you would keep actual private stuff, which creates certain difficulties for their credibility.
sparkleshare is a friendly git front-end for non-specialists:
creates a special folder on your computer. You can add remotely hosted folders (or “projects”) to this folder. These projects will be automatically kept in sync with both the host and all of your peers when someone adds, removes or edits a file.
SparkleShare uses the version control system Git under the hood, so setting up a host yourself is relatively easy.
FWIW this seems to me to be less of a good sync client, and more of a good git GUI.
Academic cred: “Ori is a distributed file system built for offline operation and empowers the user with control over synchronization operations and conflict resolution. We provide history through lightweight snapshots and allow users to verify the history has not been tampered with. Through the use of replication, instances can be resilient and recover damaged data from other nodes.”
Tresorit is a Swiss SpiderOak competitor, which capitalises on stronger Swiss privacy laws, (YMMV) as well as trendy encryption technology. Closed-source though, so there is still a degree of blind faith.
16 Bonus tricks
16.1 Synchronising dotfiles
17 Synchronising databases
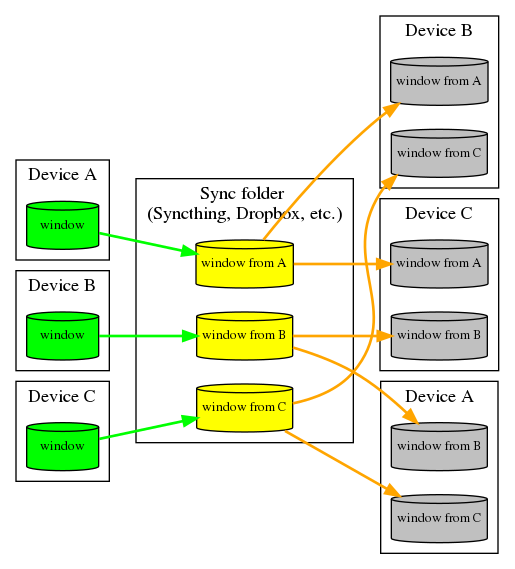
Here is a diagram of how one might do non-trivial syncing of a writeable database via a file-sync: ActivityWatch, i.e. treating a file sync as a real concurrent data-object. AFAIK this is not actually implemented anywhere.