Isotropic random vectors
2011-08-10 — 2021-05-24
Wherein Isotropic Random Vectors Are Considered, Multivariate Gaussian Samples Are Normalized to Produce Uniformly Distributed Unit Vectors, and Axial Marginals Are Deduced to Have Variance 1/D.
wow! This notebook entry is now 10 years old. I have cared about this for ages.
Random variables with radial symmetry; It would be appropriate to define these circularly, so I will, which is to say, (centred) isotropic random vectors are those whose distribution is unchanged under fixed rotations, or random rotations. Generating such variables. Distributions thereof.
In particular, I consider fun tricks with isotropic Gaussians, RVs uniform on the \(d\)-sphere or on the \(d\)-ball, i.e. things where their distribution is isotropic with respect to the Cartesian inner product and thus the \(\ell_2\) norm ends up being important. Much of this generalises to general spherically-contoured distributions (as opposed to just distributions on the sphere, which is a terminological wrinkle I should expand upon).

To begin, consider \(\mathbb{R}^d\) with the \(L_2\) norm, i.e. \(d\)-dimensional Euclidean space.
1 Simulating isotropic vectors
Let’s say you wish to simulate a random variable, \(X\) whose realisations are isotropically distributed unit-vectors (say, to represent isotropic rotations, or for a null-distribution against which to check for isotropy.)
The simplest way I know of generating such vectors is to take \[ X \sim \mathcal{N}(\mathbf{0}_d, \mathbf{I}_d) \]
That is, \(X\) distributed by a multivariate Gaussian distribution with each component independent and of standard deviation 1, so if \(X_i\) are i.i.d. with \(X_i \sim \mathcal{N}(0,1)\), then \[ X = \left[\begin{array}{c} X_1 \\ X_2 \\ \vdots \\ X_d \end{array} \right] \]
By the rotational invariance of multivariate Gaussian distributions, we know that this must be isotropic.
Update: Martin Roberts collects a bumper list, How to generate uniformly random points on n-spheres and in n-balls. There are some surprising ones.
1.1 On the \(d\)-sphere
Now, to get unit vectors we can simply normalize
\[ U \equiv \frac{X}{\left\| X \right\|} \]
(And if you use the “hit-and-run” Monte Carlo sampler, this is your daily bread.)
1.2 On the \(d\)-ball
David K observes the obvious way to generate Lebesgue-uniform vectors on the \(d\) ball is to generate spherical vectors then choose a random length \(L\) such that they are uniform on the ball. This implied length CDF should be \[ F_{L}(x)=\mathbb{P}(L \leq x)=\left\{\begin{array}{ll} 0 & x<0 \\ x^{n} & 0 \leq x \leq 1 \\ 1 & x>1 \end{array}\right. \] implying a pdf \[ f_{L}(x)=\left\{\begin{array}{ll} n x^{n-1} & 0 \leq x \leq 1, \\ 0 & \text { otherwise. } \end{array}\right. \] But in fact if \(U\sim\operatorname{Unif}([0,1])\) then \(L\simeq U^{1/d}\).
Bonus time: In fact, we can do more than just \(\ell_2\) spheres - we can also get \(\ell_p\) balls. See Barthe et al. (2005) (HT Mark Meckes). We simulate \([X_{1}, \ldots, X_{d}\) independently with density \(f_X(x)\propto\exp \left(-|x|^{p}\right)\), and \(Y\sim\operatorname{Exp}(1)\) independent. Then the random vector \[ \frac{ [X_{1}, \ldots, X_{d}] }{ Y+\|[X_{1}, \ldots, X_{d}]\|_p } \] is uniformly distributed in the unit ball of \(\ell_{p}^{d}\). When \(p=2\), this resembles the Gaussian RV trick, although they are not trivially the same. For \(p\neq 2\) these are not isotropic in the rotationally-invariant sense, though.
2 Marginal distributions
Question: what is the marginal distribution of the axial component \(U_i\), of \(U\), along axis \(i\), in the non-trivial case with \(d>1\)?
Let us consider, w.l.o.g., \(U_1\). We know that the p.d.f of \(U_1\) is even (i.e. has reflective symmetry) by construction. So it will suffice to find the positive half of the distribution function. Thus it will also be enough to find the p.d.f. of \(U_1^2\).
Define \[ X' \equiv \left[\begin{array}{c} X_2 \\ X_3 \\ \vdots \\ X_d \end{array} \right] \] i.e. \(X'\) is \(X\) with the first component of the vector excised. We have \[ \begin{array}{cccc} & U & = & \frac{X}{\left\| X \right\|} \\ \Rightarrow & U^2 & = & \frac{X^2}{\left\| X \right\|^2} \\ \Rightarrow & U_1^2 & = & \frac{X_1^2}{\left\| X \right\|^2} \\ \Rightarrow & U_1^2 & = & \frac{X_1^2}{\left\| X' \right\|^2 + X_1^2}\\ \Rightarrow & \frac{1}{U_1^2} -1 & = & \frac{\left\| X' \right\|^2}{X_1^2}\\ \Rightarrow & \frac{\frac{1}{U_1^2} -1}{d-1} & = & \frac{\left\| X' \right\|^2 / (d-1)}{X_1^2} \end{array} \]
Now, the R.H.S. has an \(\mathcal{F}(d-1,1)\) distribution, as the ratio of i.i.d \(\chi^2\) variables, and the work there has already been done for us by Snedecor. We call that R.H.S. \(G\), where \(G \sim \mathcal{F}(d-1,1)\). We write \(g\) for the pdf. Then \[ U_1^2 = \frac{1}{g(d-1)+1} \]
Now we can construct the pdf of \(U_1\). In fact, for my purposes I need the quantile/inverse-cdf function, so let’s do that. Call the quantile function of the \(\mathcal{F}(d-1,1)\) distribution, \(H(x)\) and the cdf of \(U_1\), \(F(x)\) (for ‘half’ and ‘full’).
Then we splice two symmetric copies of the function about the axis — \(F(x) = \mathrm{sgn}(2x-1) H(1-|2x-1|)\) - and we’re done.
Here’s a plot of the behaviour of our distribution:
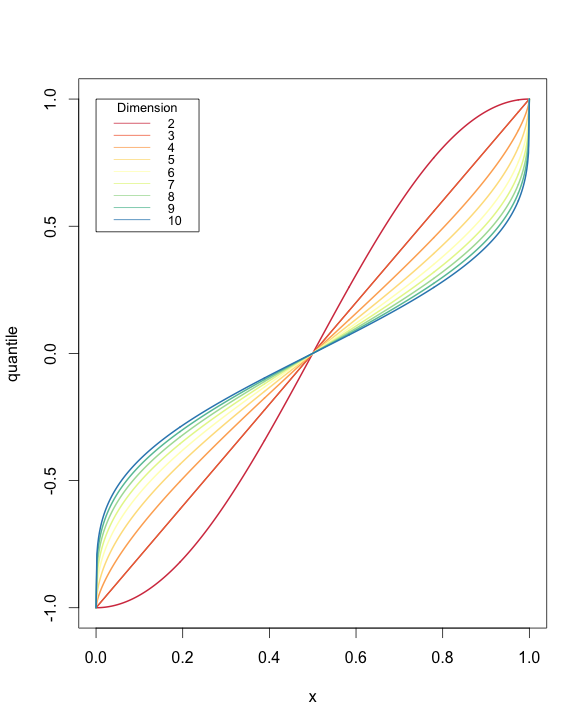
Notice that axial components tend to be long in \(\mathbb{R}^2\), and short in more than 3 dimensions. And uniformly distributed in 3 dimensions. Intuitively, as the number of dimensions increases, the contribution of any one axis to the total length is likely to be smaller on average, because there are simply more of them.
And here’s the R code to generate the graph, most of which is plotting logic.
half.quantile <- function(x,d=3) {
g <- qf(x,d-1,1)
return(1/sqrt(g*(d-1)+1))
}
full_quantile <- function (x, d=3) {
x.scaled <- 2*x -1
res <- sign(x.scaled)*half.quantile(1-abs(x.scaled), d)
return(res)
}
pts <- seq(0,1,1/512)
dims <- seq(2,10)
ndims <- length(dims)
vals <- data.frame(outer(pts, dims, full.quantile))
dimnames <- paste(dims)
xrange <- c(0,1)
yrange <- c(-1,1)
library(RColorBrewer)
colors <- brewer.pal(ndims,"Spectral")
# set up the plot
plot(xrange, yrange, type="l", xlab="x",
ylab="quantile")
# add lines
for (i in seq(ndims)) {
dim <- vals[,i]
lines(pts, dim, type="l", lwd=2,
col=colors[i],
lty=1
)
}
# add a legend
legend(xrange[1], yrange[2], dims, cex=0.8, col=colors,
lty=1, title="Dimension")There are many interesting approximate distributions for these quantities, which are explored in the low-d projections notebook.
3 Inner products
There is an exact distribution for inner products of normalized vectors. Suppose that \(L=\tfrac12 +\vv{X}_p^\top\vv{X}_q/2\). Then \(L\sim\operatorname{Beta}((D-1)/2,(D-1)/2).\)
4 Moments
Kimchi lover derives the variance of \(x_i\) chosen uniformly from the hypersphere:
\[\boldsymbol{x}\sim\operatorname{Unif}\mathbb{B}^{d-1}\Rightarrow \operatorname{Var}(X_1)=\frac{1}{d+2}.\]
See also Covariance matrix of uniform spherical distribution wherein a very simple symmetry argument gives \[\boldsymbol{x}\sim\operatorname{Unif}\mathbb{S}^{d-1}\Rightarrow \operatorname{Var}(X_1)=\frac{1}{d}.\] and indeed \[\boldsymbol{x}\sim\operatorname{Unif}\mathbb{S}^{d-1}\Rightarrow \operatorname{Var}(\boldsymbol{x})=\frac{1}{d}\mathrm{I}.\]
5 Archimedes Principles
First mention: The first \((n-2)\) coordinates on a sphere are uniform in a ball
Djalil Chafaï mentions the Archimedes principle which
… states that the projection of the uniform law of the unit sphere of \(\mathbb{R}^{3}\) on a diameter is the uniform law on the diameter. It is the case \(n=3\) of the Funk-Hecke formula…. More generally, if \(\left(X_{1}, \ldots, X_{n}\right)\) is a random vector of \(\mathbb{R}^{n}\) uniformly distributed on the unit sphere \(\mathbb{S}^{n-1}\) then \(\left(X_{1}, \ldots, X_{n-2}\right)\) is uniformly distributed on the unit ball of \(\mathbb{R}^{n-2}\). It does not work if we replace \(n-2\) by \(n-1\).
6 Funk-Hecke
Djalil Chafaï introduces the The Funk-Hecke formula:
In its basic form, the Funk-Hecke formula states that for all bounded measurable \(f:[-1,1] \mapsto \mathbb{R}\) and all \(y \in \mathbb{S}^{n-1}\), \[ \int f(x \cdot y) \sigma_{\mathbb{S}^{n-1}}(\mathrm{~d} x)=\frac{\Gamma\left(\frac{n}{2}\right)}{\sqrt{\pi} \Gamma\left(\frac{n-1}{2}\right)} \int_{-1}^{1} f(t)\left(1-t^{2}\right)^{\frac{n-3}{2}} \mathrm{d} t \] The formula does not depend on \(x\), an invariance due to spherical symmetry.…
If this is an inner product with a sphere RV then we get the density for a univariate random projection.