The Gaussian distribution
The default probability distribution
2016-06-27 — 2024-06-06

Many facts about the useful, boring, ubiquitous Gaussian. Djalil Chafaï lists Three reasons for Gaussians, emphasising more abstract, not-necessarily generative reasons.
- Gaussians as isotropic distributions — a Gaussian is the only distribution that can be both marginally independent and isotropic.
- Entropy maximising (the Gaussian has the highest entropy out of any distribution with fixed variance and finite entropy)
- The only stable distribution with finite variance.
Many other things give rise to Gaussians; sampling distributions for test statistics, bootstrap samples, low dimensional projections, anything with the right Stein-type symmetries, central limit theorems… There are many post hoc rationalisations that use the Gaussian in the hope that it is close enough to the real distribution: such as when we assume something is a Gaussian process because they are tractable, or seek a noise distribution that will justify quadratic loss, when we use Brownian motions in stochastic calculus because it comes out neatly, and so on.
1 Density, CDF
1.1 Moments form
The standard (univariate) Gaussian pdf is \[ \psi:x\mapsto \frac{1}{\sqrt{2\pi}}\text{exp}\left(-\frac{x^2}{2}\right). \] Typically we allow a scale-location parameterised version \[ \phi(x; \mu,\sigma ^{2})={\frac {1}{\sqrt {2\pi \sigma ^{2}}}}e^{-{\frac {(x-\mu )^{2}}{2\sigma ^{2}}}} \] We call the CDF \[ \Psi:x\mapsto \int_{-\infty}^x\psi(t) dt. \] In the multivariate case, where the covariance \(\Sigma\) is strictly positive definite, we can write a density of the general normal distribution over \(\mathbb{R}^k\) as \[ \psi({x}; \mu, \Sigma) = (2\pi )^{-{\frac {k}{2}}}\det(\Sigma)^{-\frac{1}{2}}\,\exp ({-\frac{1}{2}( x-\mu)^{\top}\Sigma^{-1}( x-\mu)}) \] If a random variable \(Y\) has a Gaussian distribution with parameters \(\mu, \Sigma\), we write \[Y \sim \mathcal{N}(\mu, \Sigma)\]
1.2 Canonical form
Hereafter we assume that we are talking about multivariate Gaussians, or this is not very interesting. Davison and Ortiz (2019) recommends the “information parameterization” of Eustice, Singh, and Leonard (2006), which looks like the canonical form to me. \[ p\left(\mathbf{x}\right)\propto e^{\left[-\frac{1}{2} \mathbf{x}^{\top} \Lambda \mathbf{x}+\boldsymbol{\eta}^{\top} \mathbf{x}\right]} \] The parameters of the canonical form \(\boldsymbol{\eta}, \Lambda\) relate to the moments via \[\begin{aligned} \boldsymbol{\eta}&=\Lambda \boldsymbol{\mu}\\ \Lambda&=\Sigma^{-1} \end{aligned}\] The information form is convenient as multiplication of distributions (when we update) is handled simply by adding the information vectors and precision matrices — see Marginals and conditionals.
1.3 Tempered
Call the \(\tau\)-tempering of a density \(p\) the density \(p^\tau\) for \(\tau\in\mathbb{R}\). As with all exponential families, it comes out simple if we use canonical form. For a multivariate Gaussian distribution in canonical (information) form, the density is expressed as
\[ p(x) \propto \exp\left( -\tfrac{1}{2} x^\top \Lambda x + x^\top \eta \right), \]
where
- \(\Lambda\) is the precision matrix (the inverse of the covariance matrix \(\Sigma\), i.e., \(\Lambda = \Sigma^{-1}\)),
- \(\eta = \Lambda \mu\) is the information vector,
- \(\mu\) is the mean vector.
When we temper this density by \(\tau\), we get
\[ p_\tau(x) \propto \left[ \exp\left( -\tfrac{1}{2} x^\top \Lambda x + x^\top \eta \right) \right]^\tau = \exp\left( -\tfrac{1}{2} \tau x^\top \Lambda x + \tau x^\top \eta \right). \]
This expression is still in the form of a Gaussian distribution but with scaled parameters. Specifically, both the precision matrix and the information vector are scaled by \(\tau\):
- New Precision Matrix: \(\Lambda' = \tau \Lambda\),
- New Information Vector: \(\eta' = \tau \eta\).
Thus, the tempered Gaussian retains the same structure but with parameters adjusted proportionally to \(\tau\).
In the moments form, tempering a multivariate Gaussian distribution by a scalar \(\tau \in (0,1]\) results in:
- Unchanged Mean: \(\mu' = \mu\)
- Scaled Covariance: \(\Sigma' = \dfrac{1}{\tau} \Sigma\)
This means the tempered Gaussian has the same center but is more spread out, reflecting the reduction in “confidence” due to tempering.
2 Fun density facts
Sometimes we do stunts with a Gaussian density.
2.1 What is Erf again?
This erf, or error function, is a rebranding and reparameterisation of the standard univariate normal cdf. It is popular in computer science, AFAICT because calling something an “error function” provides an amusing ambiguity to pair with the one we are used to with the “normal” distribution. There are scaling factors tacked on.
\[ \operatorname{erf}(x) = \frac{1}{\sqrt{\pi}} \int_{-x}^x e^{-t^2} \, dt \] which is to say \[\begin{aligned} \Phi(x) &={\frac {1}{2}}\left[1+\operatorname{erf} \left({\frac {x}{\sqrt {2}}}\right)\right]\\ \operatorname{erf}(x) &=2\Phi (\sqrt{2}x)-1\\ \end{aligned}\]
2.2 Taylor expansion of \(e^{-x^2/2}\)
\[ e^{-x^2/2} = \sum_{k=0}^{\infty} (2^(-k) (-x^2)^k)/(k!). \]
2.3 Score
\[\begin{aligned} \nabla_{x}\log\psi({x}; \mu, \Sigma) &= \nabla_{x}\left(-\frac{1}{2}( x-\mu)^{\top}\Sigma^{-1}( x-\mu) \right)\\ &= -( x-\mu)^{\top}\Sigma^{-1} \end{aligned}\]
3 Differential representations
First, trivially, \(\phi'(x)=-\frac{e^{-\frac{x^2}{2}} x}{\sqrt{2 \pi }}.\)
3.1 Stein’s lemma
Meckes (2009) explains Stein (1972)’s characterisation:
The normal distribution is the unique probability measure \(\mu\) for which \[ \int\left[f^{\prime}(x)-x f(x)\right] \mu(d x)=0 \] for all \(f\) for which the left-hand side exists and is finite.
This is incredibly useful in probability approximation by Gaussians where it justifies Stein’s method.
3.2 ODE representation for the univariate density
\[\begin{aligned} \sigma ^2 \phi'(x)+\phi(x) (x-\mu )&=0, \text{ i.e.}\\ L(x) &=(\sigma^2 D+x-\mu)\\ \end{aligned}\]
With initial conditions
\[\begin{aligned} \phi(0) &=\frac{e^{-\mu ^2/(2\sigma ^2)}}{\sqrt{2 \sigma^2\pi } }\\ \phi'(0) &=0 \end{aligned}\]
🚧TODO🚧 note where I learned this.
3.3 ODE representation for the univariate icdf
From (Steinbrecher and Shaw 2008) via Wikipedia.
Write \(w:=\Psi^{-1}\) to keep notation clear. It holds that \[ {\frac {d^{2}w}{dp^{2}}} =w\left({\frac {dw}{dp}}\right)^{2}. \] Using initial conditions \[\begin{aligned} w\left(1/2\right)&=0,\\ w'\left(1/2\right)&={\sqrt {2\pi }}. \end{aligned}\] we generate the icdf.
3.4 Density PDE representation as a diffusion equation
Z. I. Botev, Grotowski, and Kroese (2010) notes
\[\begin{aligned} \frac{\partial}{\partial t}\phi(x;t) &=\frac{1}{2}\frac{\partial^2}{\partial x^2}\phi(x;t)\\ \phi(x;0)&=\delta(x-\mu) \end{aligned}\]
Look, it’s the diffusion equation of Wiener process. Surprise! If you think about this for a while you end up discovering Feynman-Kac formulae.
3.5 Roughness of the density
Univariate —
\[\begin{aligned} \left\| \frac{d}{dx}\phi_\sigma \right\|_2 &= \frac{1}{4\sqrt{\pi}\sigma^3}\\ \left\| \left(\frac{d}{dx}\right)^n \phi_\sigma \right\|_2 &= \frac{\prod_{i<n}2n-1}{2^{n+1}\sqrt{\pi}\sigma^{2n+1}} \end{aligned}\]
4 Tails
For small \(p\), the quantile function has the asymptotic expansion \[ \Phi^{-1}(p) = -\sqrt{\ln\frac{1}{p^2} - \ln\ln\frac{1}{p^2} - \ln(2\pi)} + \mathcal{o}(1). \]
4.1 Mills ratio
Mills’ ratio is \((1 - \Phi(x))/\phi(x)\) and is a workhorse for tail inequalities for Gaussians. See the review and extensions of classic results in Dümbgen (2010), found via Mike Spivey. Check out his extended justification for the classic identity
\[ \int_x^{\infty} \frac{1}{\sqrt{2\pi}} e^{-t^2/2} dt \leq \int_x^{\infty} \frac{t}{x} \frac{1}{\sqrt{2\pi}} e^{-t^2/2} dt = \frac{e^{-x^2/2}}{x\sqrt{2\pi}}.\]
5 Orthogonal basis
Polynomial basis? You want the Hermite polynomials.
6 Entropy
The normal distribution is the least “surprising” distribution in the sense that out of all distributions with a given mean and variance the Gaussian has the maximum entropy. Or maybe that is the most surprising, depending on your definition.
7 Marginals and conditionals
Linear transforms of multidimensional Gaussians are especially convenient. You could say that this is a definitive property of the Gaussian. Because we have learned to represent so many things by linear algebra, this means the pairing with Gaussians is a natural one. As made famous by Gaussian process regression in Bayesian nonparametrics.
See, e.g. these lectures, or Michael I. Jordan’s Gaussian backgrounder.
In practice I look up my favourite useful Gaussian identities in Petersen and Pedersen (2012) and so does everyone else I know. You can get a good workout in this stuff especially doing Gaussian belief propagation.
Key trick: we can switch between moment and canonical parameterizations of Gaussians to make it more convenient to do one or the other.

We write this sometimes as \(\mathcal{N}^{-1}\), i.e. \[p(\boldsymbol{\alpha}, \boldsymbol{\beta})=\mathcal{N}\left(\left[\begin{array}{c}\boldsymbol{\mu}_\alpha \\ \boldsymbol{\mu}_\beta\end{array}\right],\left[\begin{array}{cc}\Sigma_{\alpha \alpha} & \Sigma_{\alpha \beta} \\ \Sigma_{\beta \alpha} & \Sigma_{\beta \beta}\end{array}\right]\right)=\mathcal{N}^{-1}\left(\left[\begin{array}{l}\boldsymbol{\eta}_\alpha \\ \boldsymbol{\eta}_\beta\end{array}\right],\left[\begin{array}{ll}\Lambda_{\alpha \alpha} & \Lambda_{\alpha \beta} \\ \Lambda_{\beta \alpha} & \Lambda_{\beta \beta}\end{array}\right]\right)\]
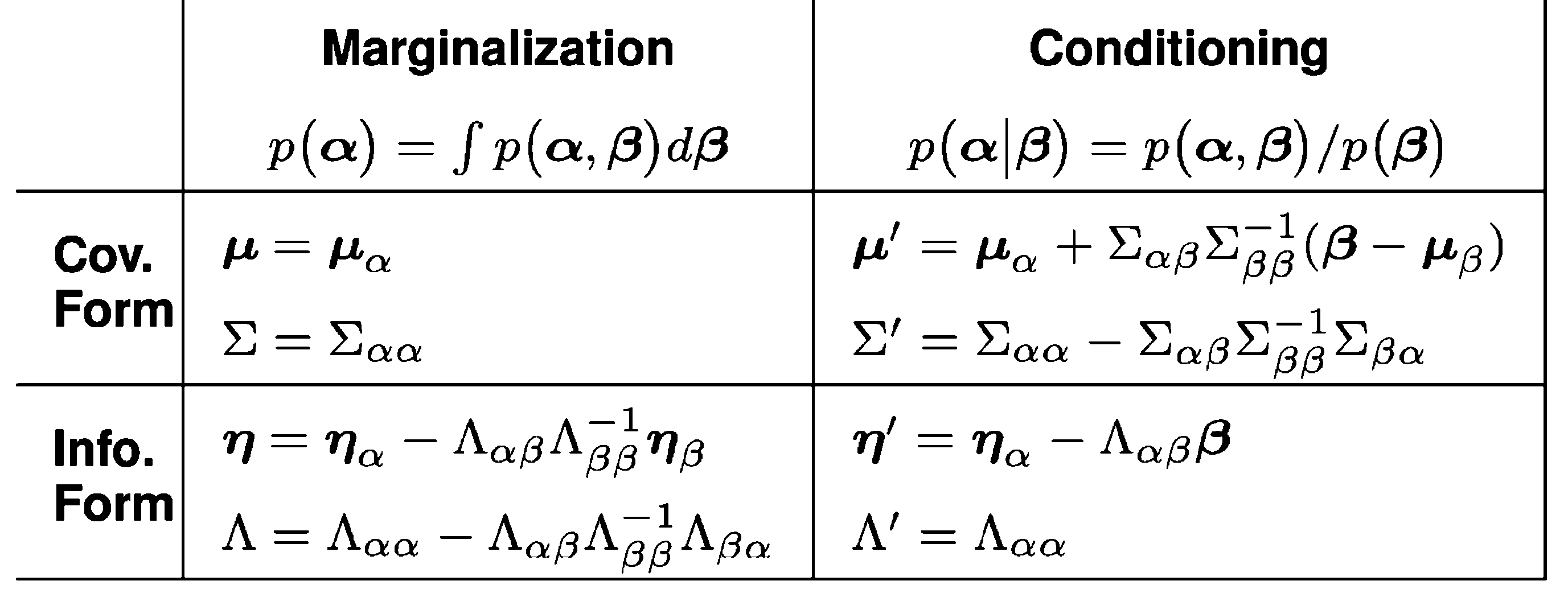
The explicit form for the marginalising and conditioning ops from Eustice, Singh, and Leonard (2006). I tried to make this table into a real HTML table, but that ends up being a typographical nightmare, so this is an image. Sorry.
Looking at the table with the exact formulation of the update for each RV, we see that the marginalisation and conditioning operations are twins to each other, in the sense that they are the same operation, but with the roles of the two variables swapped.
In GBP we want not just conditioning but a generalisation, where we can find general product densities cheaply.
7.1 Product of densities
A workhorse of Bayesian statistics is the product of densities, and it comes out in an occasionally useful form for Gaussians.
Let \(\mathcal{N}_{\mathbf{x}}(\boldsymbol{\mu}, \boldsymbol{\Sigma})\) denote a density of \(\mathbf{x}\), then \[ \mathcal{N}_{\mathbf{x}}\left(\boldsymbol{\mu}_1, \boldsymbol{\Sigma}_1\right) \cdot \mathcal{N}_{\mathbf{x}}\left(\boldsymbol{\mu}_2, \boldsymbol{\Sigma}_2\right)\propto \mathcal{N}_{\mathbf{x}}\left(\boldsymbol{\mu}_c, \boldsymbol{\Sigma}_c\right) \] where \[ \begin{aligned} \boldsymbol{\Sigma}_c&=\left(\boldsymbol{\Sigma}_1^{-1}+\boldsymbol{\Sigma}_2^{-1}\right)^{-1}\\ \boldsymbol{\mu}_c&=\boldsymbol{\Sigma}_c\left(\boldsymbol{\Sigma}_1^{-1} \boldsymbol{\mu}_1+\boldsymbol{\Sigma}_2^{-1} \boldsymbol{\mu}_2\right). \end{aligned} \]
Translating that to canonical form, with \(\mathcal{N}^{-1}_{\mathbf{x}}(\boldsymbol{\eta}, \boldsymbol{\Sigma})\) denoting a canonical-form density of \(\mathbf{x}\), then \[ \mathcal{N}_{\mathbf{x}}^{-1}\left(\boldsymbol{\eta}_1, \boldsymbol{\Lambda}_1\right) \cdot \mathcal{N}_{\mathbf{x}}^{-1}\left(\boldsymbol{\eta}_2, \boldsymbol{\Lambda}_2\right)\propto \mathcal{N}_{\mathbf{x}}^{-1}\left(\boldsymbol{\eta}_c, \boldsymbol{\Lambda}_c\right) \] where \[ \begin{aligned} \boldsymbol{\Lambda}_c&=\boldsymbol{\Lambda}_1+\boldsymbol{\Lambda}_2 \\ \boldsymbol{\eta}_c&=\boldsymbol{\eta}_1+ \boldsymbol{\eta}_2. \end{aligned} \]
7.2 Orthogonality of conditionals
See pathwise GP.
8 Fourier representation
The Fourier transform/Characteristic function of a Gaussian is still Gaussian.
\[\mathbb{E}\exp (i\mathbf{t}\cdot \mathbf {X}) =\exp \left( i\mathbf {t} ^{\top}{\boldsymbol {\mu }}-{\tfrac {1}{2}}\mathbf {t} ^{\top}{\boldsymbol {\Sigma }}\mathbf {t} \right).\]
9 Transformed variates
10 Metrics
Since Gaussian approximations pop up a lot in e.g. variational approximation problems, it is nice to know how to relate them in probability metrics. See distance between two Gaussians.
11 Matrix Gaussian
See matrix gaussian.
12 Useful gradients
Rezende, Mohamed, and Wierstra (2015):
When the distribution \(q\) is a \(K\)-dimensional Gaussian \(\mathcal{N}(\boldsymbol{\xi} \mid \boldsymbol{\mu}, \mathbf{C})\) the required gradients can be computed using the Gaussian gradient identities: \[ \begin{aligned} \nabla_{\mu_i} \mathbb{E}_{\mathcal{N}(\boldsymbol{\mu}, \mathbf{C})}[f(\boldsymbol{\xi})] & =\mathbb{E}_{\mathcal{N}(\boldsymbol{\mu}, \mathbf{C})}\left[\nabla_{\xi_i} f(\boldsymbol{\xi})\right], (7) \\ \nabla_{C_{i j}} \mathbb{E}_{\mathcal{N}(\boldsymbol{\mu}, \mathbf{C})}[f(\boldsymbol{\xi})] & =\frac{1}{2} \mathbb{E}_{\mathcal{N}(\boldsymbol{\mu}, \mathbf{C})}\left[\nabla_{\xi_i, \xi_j}^2 f(\boldsymbol{\xi})\right], (8) \end{aligned} \] which are due to the theorems by Bonnet (1964) and Price (1958), respectively. These equations are true in expectation for any integrable and smooth function \(f(\boldsymbol{\xi})\). Equation (7) is a direct consequence of the location-scale transformation for the Gaussian […]. Equation (8) can be derived by successive application of the product rule for integrals; […]. Equations (7) and (8) are especially interesting since they allow for unbiased gradient estimates by using a small number of samples from \(q\). Assume that both the mean \(\boldsymbol{\mu}\) and covariance matrix \(\mathbf{C}\) depend on a parameter vector \(\boldsymbol{\theta}\). We are now able to write a general rule for Gaussian gradient computation by combining equations (7) and (8) and using the chain rule: \[ \nabla_{\boldsymbol{\theta}} \mathbb{E}_{\mathcal{N}(\boldsymbol{\mu}, \mathbf{C})}[f(\boldsymbol{\xi})]=\mathbb{E}_{\mathcal{N}(\boldsymbol{\mu}, \mathbf{C})}\left[\mathbf{g}^{\top} \frac{\partial \boldsymbol{\mu}}{\partial \boldsymbol{\theta}}+\frac{1}{2} \operatorname{Tr}\left(\mathbf{H} \frac{\partial \mathbf{C}}{\partial \boldsymbol{\theta}}\right)\right] \] where \(\mathbf{g}\) and \(\mathbf{H}\) are the gradient and the Hessian of the function \(f(\boldsymbol{\xi})\), respectively. Equation (9) can be interpreted as a modified backpropagation rule for Gaussian distributions that takes into account the gradients through the mean \(\boldsymbol{\mu}\) and covariance \(\mathbf{C}\). This reduces to the standard backpropagation rule when \(\mathbf{C}\) is constant. Unfortunately this rule requires knowledge of the Hessian matrix of \(f(\boldsymbol{\xi})\), which has an algorithmic complexity \(O\left(K^3\right)\).
See also Opper and Archambeau (2009).
13 Conjugate priors
See Murphy (2007) for some classic forms for conjugate priors for Gaussian likelihoods.
13.1 In canonical form
Weirdly no one seems to write out the canonical form of the conjugate prior for the Gaussian. For reasons of, presumably, tradition, weird ad hoc parameterisations such as mean-precision or mean variance are used. These are not convenient.
The following is an unfinished work in progress.
We start from a Gaussian likelihood with in canonical form. To put the Gaussian likelihood into exponential family form, let’s first consider the precision $ = 1/^2.$ The Gaussian distribution can be parameterised by the natural parameters \(\eta={\scriptstyle\begin{bmatrix}\rho \ \tau\end{bmatrix}}\), where \(\rho= \mu \tau,\) is the mean scaled by the precision, and \(\tau\) is the precision.
Sanity check: Write out moment-form Gaussian and canonicalize. \[ \begin{aligned} p(x \mid \mu, \sigma^2) &=\frac{1}{\sqrt{2\pi\sigma^2}} e^{-\frac{(x - \mu)^2}{2\sigma^2}}\\ &= \sqrt{\frac{\tau}{2\pi}} e^{-\frac{1}{2}\tau(x - \rho/\tau)^2}\\ &= \sqrt{\frac{\tau}{2\pi}} e^{-\frac{1}{2}\tau(x^2 - 2\rho x /\tau + \rho^2/\tau^2)}\\ &= \frac{\sqrt{\tau}}{\sqrt{2\pi}} e^{-\frac{1}{2}\tau x^2 + \rho x -\frac{1}{2} \rho^2/\tau}\\ &= \frac{1}{\sqrt{2\pi}} e^{ -\frac{1}{2}\tau x^2 +\rho x +\frac{1}{2}\log \tau -\frac{1}{2} \rho^2/\tau }\\ &= \frac{1}{\sqrt{2\pi}} \exp\left( \begin{bmatrix} x\\ -\frac{1}{2}x^2 \end{bmatrix}\cdot \begin{bmatrix} \rho\\ \tau \end{bmatrix}\ +\frac{1}{2}\log \tau -\frac{1}{2} \frac{\rho^2}{\tau} \right) \end{aligned} \] The sufficient statistics \(T(x)\) that correspond to these natural parameters are \(T(x) = \begin{bmatrix} x \ -\frac{x^2}{2}\end{bmatrix}.\)
The base measure \(h(x)\) is \[ h(x) = \frac{1}{\sqrt{2\pi}}. \]
The log-partition function \(A(\eta)\) is \[ A(\eta) =\frac{1}{2}\log \tau -\frac{1}{2} \frac{\rho^2}{\tau}. \] Putting all these together, the canonical form of the Gaussian likelihood with respect to the natural parameters and sufficient statistics becomes: \[ p(x \mid \rho, \tau) = \frac{1}{\sqrt{2\pi}}\exp\left(\rho x - \frac{\tau x^2}{2} - \left(\frac{\rho^2 }{ 2 \tau } - \frac{1}{2} \log \tau\right)\right) \]
What is the conjugate prior for this? I am going to punt that making it Normal-Gamma will come out ok, why not? But I suspect we want the Normal term in the Normal-Gamma to be canonical form (?).
\[ \begin{aligned} p\left(\begin{bmatrix}\rho\\\tau\end{bmatrix}\middle \vert r , t ,\kappa,\gamma\right) &=\operatorname{NormalGamma}(\rho,\tau| r , t, \kappa, \gamma )\\ &=\mathcal{N}(\rho| r , t )\operatorname{Gamma}(\tau|\kappa,\gamma)\\ % &=\sqrt{\frac{1}{2\pi\sigma^2}}e^{-\frac{(\rho-\mu)^2}{2\sigma^2}}\frac{(-\gamma)^{\kappa+1}}{\Gamma(\kappa+1)}\tau^{\kappa}e^{\tau\gamma}\\ &=\sqrt{\frac{ t }{2\pi}} e^{-\frac{ t }{2}(\rho^2-2\rho r / t + r ^2/ t ^2)} \frac{(-\gamma)^{\kappa+1}}{\Gamma(\kappa+1)}\tau^{\kappa} e^{\tau\gamma}\\ &=\sqrt{\frac{ t }{2\pi}} \frac{(-\gamma)^{\kappa+1}}{\Gamma(\kappa+1)} e^{-\frac{1}{2} r ^2/ t } \tau^{\kappa} e^{ -\frac{ t }{2}\rho^2 +\rho r +\tau\gamma}\\ &=\sqrt{\frac{ t }{2\pi}} \frac{(-\gamma)^{\kappa+1}}{\Gamma(\kappa+1)} e^{-\frac{1}{2} r ^2/ t } e^{ \kappa \log \tau -\frac{ t }{2}\rho^2 +\rho r +\tau\gamma}\\ &=\left( \sqrt{\frac{ t }{2\pi}} e^{-\frac{ r ^2}{2 t }} \right) \left( \frac{(-\gamma)^{\kappa+1}}{\Gamma(\kappa+1)} \right) \exp\left( \begin{bmatrix} \gamma\\ \kappa\\ r \\ t \end{bmatrix} \cdot \begin{bmatrix} \tau \\ \log \tau\\ \rho \\ -\frac{\rho^2}{2} \end{bmatrix} \right) \end{aligned} \] NB, \(\gamma=-\beta\) in the classic Gamma rate param and \(\kappa=k-1\). \(\gamma\) is always negative.
Let us directly apply Bayes’ theorem. \[ \begin{aligned} p(\rho,\tau|x) &\propto p(x|\rho,\tau)p(\rho,\tau)\\ &=e^{\rho x - \frac{\tau x^2}{2} - \left(\frac{\rho^2 }{ 2 \tau } - \frac{1}{2} \log \tau\right)} \sqrt{\frac{ t }{2\pi}} \frac{(-\gamma)^{\kappa+1}}{\Gamma(\kappa+1)} e^{-\frac{1}{2} r ^2/ t } e^{ \kappa \log \tau -\frac{ t }{2}\rho^2 +\rho r +\tau\gamma }\\ &\propto \sqrt{\frac{ t }{2\pi}} \frac{(-\gamma)^{\kappa+1}}{\Gamma(\kappa+1)} e^{ \tau\gamma - \frac{\tau x^2}{2} + \frac{1}{2} \log \tau + \kappa \log \tau + \rho x + \rho r - \frac{ t }{2}\rho^2 - \frac{\rho^2 }{ 2 \tau } - \frac{1}{2} r ^2/ t }\\ &\propto e^{ \left((\gamma - \frac{x^2}{2}\right)\tau + \left(\frac{1}{2} + \kappa\right) \log \tau + (x + r) \rho x + (t + \frac{1}{\tau})\left(-\frac{\rho^2}{2}\right) }\\ &= \operatorname{NormalGamma}(\rho, \tau | r + x, t + {\scriptstyle \frac{1}{\tau}}, \kappa + {\scriptstyle \frac{1}{2}}, \gamma - {\scriptstyle \frac{x^2}{2}}) \end{aligned} \]
No wait, that’s wrong, we have \(\tau\) on both sides of the update equation. So in fact, this ain’t conjugate. I wonder what is?
14 Discrete
Canonne, Kamath, and Steinke (2022):
A key tool for building differentially private systems is adding Gaussian noise to the output of a function evaluated on a sensitive dataset. Unfortunately, using a continuous distribution presents several practical challenges. First and foremost, finite computers cannot exactly represent samples from continuous distributions, and previous work has demonstrated that seemingly innocuous numerical errors can entirely destroy privacy. Moreover, when the underlying data is itself discrete (e.g., population counts), adding continuous noise makes the result less interpretable. With these shortcomings in mind, we introduce and analyse the discrete Gaussian in the context of differential privacy. Specifically, we theoretically and experimentally show that adding discrete Gaussian noise provides essentially the same privacy and accuracy guarantees as the addition of continuous Gaussian noise. We also present a simple and efficient algorithm for exact sampling from this distribution. This demonstrates its applicability for privately answering counting queries, or more generally, low-sensitivity integer-valued queries.