
A grab bag of links I have found pragmatically useful in the topsy-turvy world of ML research. Here, even though we have big data about the world, we still have small data about our own experimental models of the world because they are so computationally expensive.
1 Workflow rules-of-thumb
Martin Zinkervich’s Rules of ML for engineers, and Google’s broad brush workflow overview. Andrej Karpathy’s Recipe for training neural networks.
2 Testing and debugging
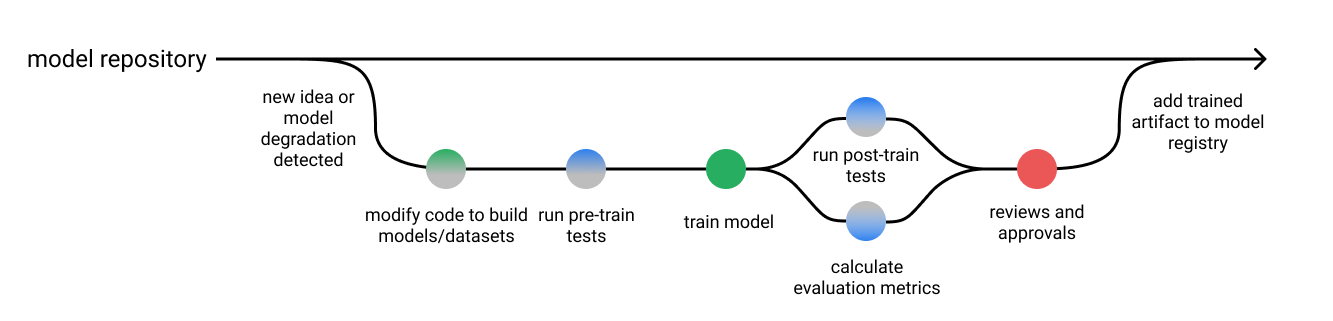
Zayd Enam on why debugging machine learning is hard and Jeremy Jordan on writing tests for ML.
3 Data management
A whole field. See also data versioning.
4 As reproducible research
The Turing Way by the Alan Turing Institute covers many reproducible research/open notebook science ideas, which include some tips applicable to ML research.
5 Trustworthiness and transparency
6 Tools
- Kedro | A Python framework for creating data science code /Kedro Frequently asked questions. Kedro rationale by Joel Schwarzmann: The importance of layered thinking in data engineering
See also configuring ML for some abstractions of use, and experiment tracking in ML.
7 Neural nets in particular
See applied neural nets for a grab bag of links on the topic.
8 Incoming
- Normconf Lightning Talks/Normconf: The Normcore Tech Conference — a conference on the stuff that we actually need to do in ML, as opp. the stuff we would like to pretend is what we do.