Jax
Julia for python
2020-09-15 — 2024-12-05
Wherein JAX is presented as a numerical library, whose NumPy programs are compiled via XLA to run on GPUs and TPUs, and whose composable, pure-function transformations are offered as grad, jit and vmap.

jax is a successor to classic Python+NumPy autograd. It includes various code optimisations, JIT-compilations, differentiating, and vectorising.
So, a numerical library with certain high-performance machine-learning affordances. Note, it is not a deep learning framework per se, but rather the producer species at a low trophic level of a deep learning ecosystem. For information on frameworks built upon it (or I suppose, in this metaphor predator species) read on to later sections.
The official pitch:
JAX can automatically differentiate native Python and NumPy functions. It can differentiate through loops, branches, recursion, and closures, and it can take derivatives of derivatives of derivatives. It supports reverse-mode differentiation (a.k.a. backpropagation) via grad as well as forward-mode differentiation, and the two can be composed arbitrarily to any order.
What’s new is that JAX uses XLA to compile and run your NumPy programs on GPUs and TPUs. Compilation happens under the hood by default, with library calls getting just-in-time compiled and executed. But JAX also lets you just-in-time compile your own Python functions into XLA-optimized kernels using a one-function API,
jit. Compilation and automatic differentiation can be composed arbitrarily, so you can express sophisticated algorithms and get maximal performance without leaving Python.Dig a little deeper, and you’ll see that JAX is really an extensible system for composable function transformations. Both
gradandjitare instances of such transformations. Another isvmapfor automatic vectorisation, with more to come.This is a research project, not an official Google product. Expect bugs and sharp edges. Please help by trying it out, reporting bugs, and letting us know what you think!
AFAICT the conda installation command is
1 Intros, tutorials
- You don’t know jax is a popular intro.
- n2cholas/awesome-jax
2 Neat examples
- Shailesh Kumar, Wavelet Transforms in Python with Google JAX
- CR.Sparse — A JAX/XLA based library of accelerated models and algorithms for inverse problems in sparse representation and compressive sensing.
2.1 Fun with gradients
Custom derivative rules for JAX-transformable Python functions, including implicit functions. for google/jaxopt: Hardware accelerated, batchable and differentiable optimisers in JAX..
Differentiate C++ code via EnzymeAD/Enzyme-JAX.
3 Idioms
Jax has idioms that are not obvious. For me, it was not clear how to use batch vectorising and functional-style application of structures:
- Autobatching log-densities example — JAX documentation
- Pytrees
- The Autodiff Cookbook
- alvarobartt/safejax: Serialize JAX, Flax, Haiku, or Objax model params with 🤗`safetensors`
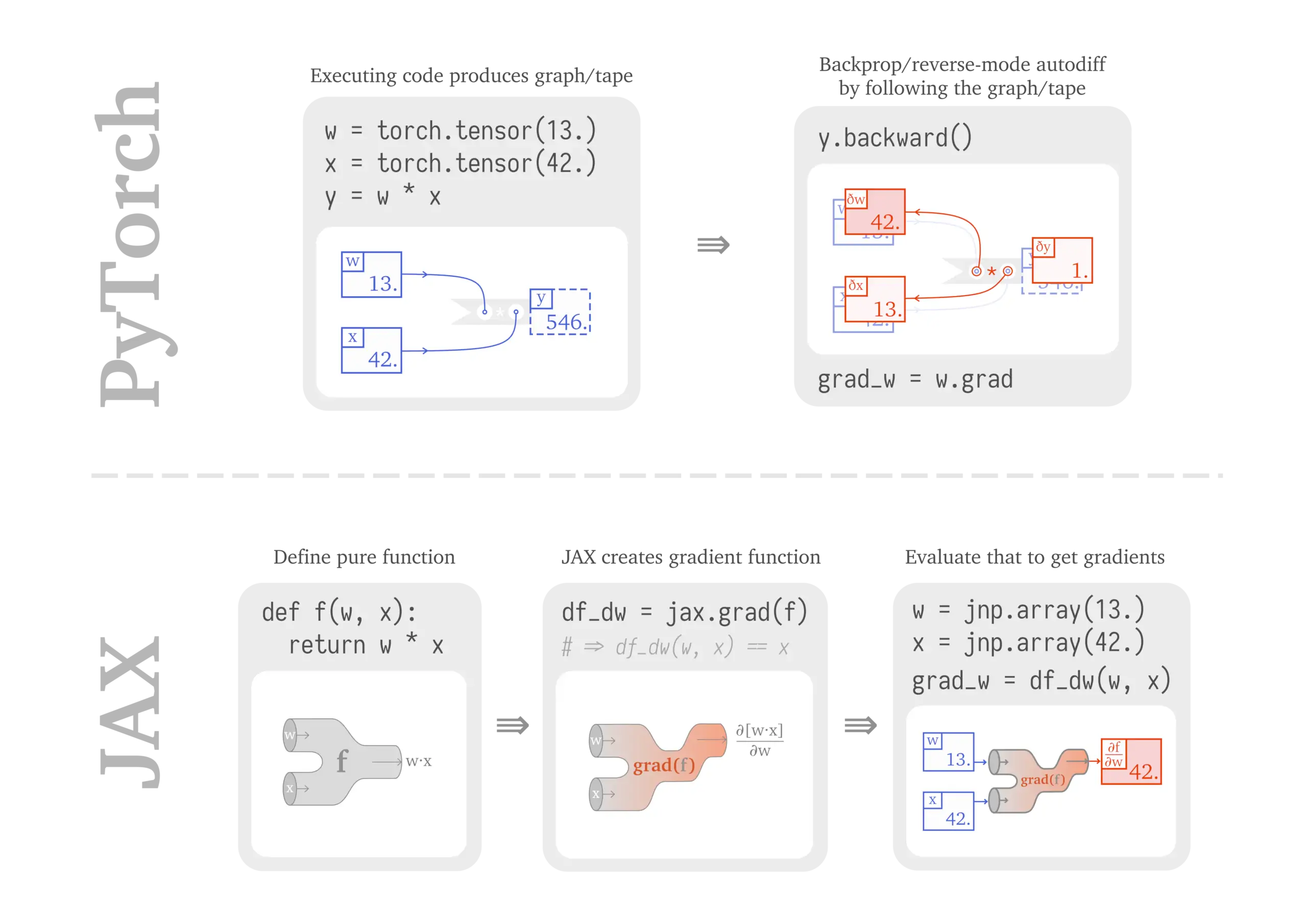
Sabrina J. Mielke, From PyTorch to JAX: towards neural net frameworks that purify stateful code
Maybe you decided to look at libraries like
flax,trax, orhaikuand what you see at least in the ResNet examples looks not too dissimilar from any other framework: define some layers, run some trainers… but what is it that actually happens there? What’s the route from these tiny numpy functions to training big hierarchical neural nets?That’s the niche this post is trying to fill. We will:
- quickly recap a stateful LSTM-LM implementation in a tape-based gradient framework, specifically PyTorch,
- see how PyTorch-style coding relies on mutating state, learn about mutation-free pure functions and build (pure) zappy one-liners in JAX,
- step-by-step go from individual parameters to medium-size modules by registering them as pytree nodes,
- combat growing pains by building fancy scaffolding, and controlling context to extract initialised parameters purify functions and
- realise that we could get that easily in a framework like DeepMind’s
haikuusing itstransformmechanism.
One thing I see often in examples is
Do I need to care about it? tl;dr omnistaging is good and necessary and also switched on by default on recent jax, so that line is simply being careful and likely unneeded.
4 Deep learning frameworks
tl;dr Just take Patrick Kidger’s recommendations:
Always useful Equinox: neural networks and everything not already in core JAX! jaxtyping: type annotations for shape/dtype of arrays.
Deep learning Optax: first-order gradient (SGD, Adam, …) optimisers. Orbax: checkpointing (async/multi-host/multi-device). Levanter: scalable+reliable training of foundation models (e.g. LLMs).
Scientific computing Diffrax: numerical differential equation solvers. Optimistix: root finding, minimisation, fixed points, and least squares. Lineax: linear solvers. BlackJAX: probabilistic+Bayesian sampling.
Longer version:
OK, elegant linear algebra is all well and good, but can I also have some standard neural network libraries with convnets and dropout layers and SGD all that standard machinery? Yes! In fact, I can have a huge menu of very similar libraries, and now all the computation time I saved by using jax must be spent on working out which flavour of jax libraries I actually want. Beware, this is a difficult API design problem; IMO the reason is that there is friction between the pure and beautiful functional style of jax code and the object-oriented, state-mutating style that deep learning people are used to.
4.1 Flax
Flax was I think the de facto standard deep learning library for jax, and may be still.
Flax is a high-performance neural network library for JAX that is designed for flexibility: Try new forms of training by forking an example and by modifying the training loop, not by adding features to a framework.
Flax is being developed in close collaboration with the JAX team and comes with everything you need to start your research, including:
Neural network API (
flax.linen): Dense, Conv, {Batch|Layer|Group} Norm, Attention, Pooling, {LSTM|GRU} Cell, DropoutUtilities and patterns: replicated training, serialisation and checkpointing, metrics, prefetching on device
Educational examples that work out of the box: MNIST, LSTM seq2seq, Graph Neural Networks, Sequence Tagging
Fast, tuned large-scale end-to-end examples: CIFAR10, ResNet on ImageNet, Transformer LM1b
I think the google brain team moved on but this now has enough inertia to remain live? See also the WIP documentation notebooks Those answered some of my questions, but I still have questions left over due to various annoying rough edges and non-obvious gotchas. For example, if you miss a parameter needed for a given model, the error is FilteredStackTrace: AssertionError: Need PRNG for "params". Also, why do some modules assume batching and other not? No hints. It seems it can be more or less can be cargo-culted, and we can ignore the quirks except sometimes.
There are some helpful examples in the repository.
I have the vague feeling that this will be abandoned for a more polished interface soon. Still seems actively developed.
4.2 Penzai
Penzai is a JAX library for writing models as legible, functional pytree data structures, along with tools for visualising, modifying, and analysing them. Penzai focuses on making it easy to do stuff with models after they have been trained, making it a great choice for research involving reverse-engineering or ablating model components, inspecting and probing internal activations, performing model surgery, debugging architectures, and more. (But if you just want to build and train a model, you can do that too!)
- google-deepmind/penzai: A JAX research toolkit for building, editing, and visualising neural networks.
- Penzai — penzai
- How to Think in Penzai — penzai
It seems to incorporate many useful insights from equinox.
4.3 Equinox
Kidger and Garcia (2021):
JAX and PyTorch are two popular Python autodifferentiation frameworks. JAX is based around pure functions and functional programming. PyTorch has popularised the use of an object-oriented (OO) class-based syntax for defining parameterised functions, such as neural networks. That this seems like a fundamental difference means current libraries for building parameterised functions in JAX have either rejected the OO approach entirely (Stax) or have introduced OO-to-functional transformations, multiple new abstractions, and been limited in the extent to which they integrate with JAX (Flax, Haiku, Objax). Either way this OO/ functional difference has been a source of tension. Here, we introduce
Equinox, a small neural network library showing how a PyTorch-like class-based approach may be admitted without sacrificing JAX-like functional programming. We provide two main ideas. One: parameterised functions are themselves represented asPyTrees, which means that the parameterisation of a function is transparent to the JAX framework. Two: we filter a PyTree to isolate just those components that should be treated when transforming (jit,gradorvmap-ing) a higher-order function of a parameterised function – such as a loss function applied to a model. Overall Equinox resolves the above tension without introducing any new programmatic abstractions: only PyTrees and transformations, just as with regular JAX. Equinox is available at https://github.com/patrick-kidger/equinox
Coming from Flax or Haiku? The main difference is that Equinox (a) offers a lot of advanced features not found in these libraries, like PyTree manipulation or runtime errors; (b) has a simpler way of building models: they’re just PyTrees, so they can pass across JIT/grad/etc. boundaries smoothly.
4.4 Stax
Rob Salomone recommends stax which ships with jax. It has an alarming disclaimer:
You likely do not mean to import this module! Stax is intended as an example library only. There are a number of other much more fully-featured neural network libraries for JAX…
Documentation seems absent. Here are some examples of stax in action
Unique value proposition: stax attempts to stay close to Jax’s functional style, unlike the more object-oriented contenders.
4.5 Haiku
Deepmind-flavoured. Haiku Documentation
Haiku is a simple neural network library for JAX that enables users to use familiar object-oriented programming models while allowing full access to JAX’s pure function transformations. Haiku is designed to make the common things we do such as managing model parameters and other model state simpler and similar in spirit to the Sonnet library that has been widely used across DeepMind. It preserves Sonnet’s module-based programming model for state management while retaining access to JAX’s function transformations. Haiku can be expected to compose with other libraries and work well with the rest of JAX.
4.6 trax
Looks unmaintained.
Trax is an end-to-end library for deep learning that focuses on clear code and speed. It is actively used and maintained in the Google Brain team. This notebook (run it in colab) shows how to use Trax and where you can find more information.
Trax includes basic models (like ResNet, LSTM, Transformer) and RL algorithms (like REINFORCE, A2C, PPO). It is also actively used for research and includes new models like the Reformer and new RL algorithms like AWR. Trax has bindings to a large number of deep learning datasets, including Tensor2Tensor and TensorFlow datasets.
You can use Trax either as a library from your own Python scripts and notebooks or as a binary from the shell, which can be more convenient for training large models. It runs without any changes on CPUs, GPUs and TPUs.
5 Inference boilerplate stuff
5.1 Optax
Optax is a gradient processing and optimisation library for JAX. It is designed to facilitate research by providing building blocks that can be recombined in custom ways to optimise parametric models such as, but not limited to, deep neural networks.
Our goals are to
Provide readable, well-tested, efficient implementations of core components,
Improve researcher productivity by making it possible to combine low-level ingredients into custom optimisers (or other gradient processing components).
Accelerate adoption of new ideas by making it easy for anyone to contribute.
We favour focusing on small composable building blocks that can be effectively combined into custom solutions. Others may build upon these basic components more complicated abstractions. Whenever reasonable, implementations prioritise readability and structuring code to match standard equations, over code reuse.
6 Probabilistic programming frameworks
6.1 Numpyro
Numpyro seems to be the dominant probabilistic programming system. It is a JAX port/implementation/something of the pytorch classic, Pyro.
More fringe but possibly interesting, jax-md does molecular dynamics. ladax “LADAX: Layers of distributions using FLAX/JAX” does some kind of latent RV something.
6.2 Stheno
The creators of Stheno seem to be Invenia, some of whose staff I am connected to in various indirect ways. It targets JAX as one of several backends via a generic backend library, wesselb/lab: A generic interface for linear algebra backends.
Placeholder; details TBD.
7 Graph networks
8 Differential equations and multi-level optimisation
Trying to do inference with differential equations? Can’t use julia? JAX might do instead.
Diffrax is a JAX-based library providing numerical differential equation solvers.
Hardware accelerated, batchable and differentiable optimisers in JAX.
- Hardware accelerated: our implementations run on GPU and TPU, in addition to CPU.
- Batchable: multiple instances of the same optimisation problem can be automatically vectorised using JAX’s vmap.
- Differentiable: optimisation problem solutions can be differentiated with respect to their inputs either implicitly or via autodiff of unrolled algorithm iterations.
- Ceyron/exponax: Efficient Differentiable n-d PDE solvers in JAX.
- Ceyron/trainax: Training methodologies for autoregressive neural operators in JAX.
- PDEquinox
8.1 tf2jax
TF2JAX is an experimental library for converting TensorFlow functions/graphs to JAX functions.
9 Multi-GPU
JAX natively handles multi-GPU, via pmap, but how to use it? The haiku example makes it clearer.
10 Portability
How do we get networks into and out of the JAX ecosystem?
10.1 ONNX
Hacky.
11 Fun with linear algebra
Many useful methods in pnkraemer/matfree: Matrix-free linear algebra in JAX. (Krämer et al. 2024).
12 Incoming
wesselb/varz: “Painless optimization of constrained variables in AutoGrad, TensorFlow, PyTorch, and JAX”.