Pytorch
The best-supported neural network framework
2018-05-04 — 2024-09-10
Wherein PyTorch Is Presented as the Heir to Lua Torch, Its Eager Dynamic Graph Model and Clear Documentation Are Noted, and an Extensive Ecosystem Including Functorch and Lightning Is Described.
Successor to Lua’s torch. Evil twin to Google’s Tensorflow. Intermittently ascendant over Tensorflow amongst researchers, if not in industrial uses.

They claim certain fancy applications are easier in PyTorch’s dynamic graph construction style, which resembles (in user experience if not implementation details) the dynamic styles of most julia autodiffs, and Tensorflow in “eager” mode.
PyTorch has a unique [sic] way of building neural networks: using and replaying a tape recorder.
Most frameworks such as TensorFlow, Theano, Caffe and CNTK have a static view of the world. One has to build a neural network, and reuse the same structure again and again. Changing the way the network behaves means that one has to start from scratch. [… PyTorch] allows you to change the way your network behaves arbitrarily with zero lag or overhead.
Of course, the overhead is only zero in the sense that a creative accountant can make a profitable business’s tax liability zero; rather, they have shifted the user overhead around a little so that it doesn’t count. However, it is less annoying to change stuff compared to the version of Tensorflow that was current at the time they wrote that. Discounting the hyperbole, PyTorch still provides relatively convenient, reasonably efficient autodiff and miscellaneous numerical computing, and in particular, a massive community.
One surcharge we pay to access this is that they have chosen arbitrarily different names and calling conventions for all the mathematical functions I use than either Tensorflow or numpy, who already chose different names than one another, so there is pointless friction in swapping between these frameworks. Presumably that is a tactic to engineer a captive audience? Or maybe just bad coordination. idk.
1 Getting started
An incredible feature of PyTorch is its documentation, which is clear and consistent and somewhat comprehensive. That is hopefully no longer a massive advantage over Tensorflow, whose documentation was garbled nonsense when I was using it, but I have not checked.
- main website
- source
- sundry hot tips at the incredible pytorch
- Using PyTorch while off-grid? Offline docs available at unknownue/PyTorch.docs.
2 Pro tips
- pylint does not play nicely with torch per default. In vs code there are some helpful settings.
3 Functorch
jax for PyTorch. Includes many useful things.
4 Gotchas and tips
4.1 PyTorch can’t actually do big linear algebra calcs
Received an error like this while trying to do svd or eigh on a big matrix?
Me too. We are screwed. Pytorch can’t actually do big linear algebra calcs. Possibly an experimental custom build might help? See #51720 · pytorch/pytorch.
4.2 Mutation
To mutate the content of a tensor, use the (to my mind non-obvious) copy_ method.
4.3 Complex numbers
Complex numbers work but complex parameters are still fragile.
4.4 do not use torch.diag
torch.diag ambiguously returns a diagonal matrix from a vector or extracts a diagonal from a matrix. You’d think there is never confusion between these? But in the sloppily-typed world of PyTorch tensors, there can be much ambiguity. This ambiguity just cost me 2 days of my life. There are two alternatives that do what I want, without introducing ambiguity:
torch.diagonal() always returns the vector of the diagonal elements of the input.
torch.diagflat() always constructs a tensor with diagonal elements specified by the input.
5 Going faster
Andrej Karpathy summarises Szymon Migacz’s PyTorch Performance Tuning Guide a “good quick tutorial on optimising your PyTorch code ⏲️”:
- DataLoader has bad default settings, tune
num_workers > 0and default topin_memory = True- use
torch.backends.cudnn.benchmark = Trueto autotune cudnn kernel choice- max out the batch size for each GPU to amortize compute
- do not forget
bias=Falsein weight layers beforeBatchNorms, it’s a noop that bloats model- use
for p in model. parameters (): p.grad = Noneinstead ofmodel.zero_grad()- careful to disable debug APIs in prod (detect
_anomaly/profiler/emit_nvt%/gradched.)- use
DistributedDataParallelnotDataParallel, even if not running distributed- careful to load balance compute on all GPUs if variably-sized inputs or GPUs will idle
- use an apex fused optimizer (default PyTorch optim for loop iterates individual params, yikes)
- use checkpointing to recompute memory-intensive compute-efficient ops in bwd pass (e.g. activations, upsampling,…)
- use
@torch.jit.script, e.g. esp to fuse long sequences of pointwise ops like in GELU
These days, try torch.compile, which for example, is faster than APEX fused optimizers. Maybe even ONNX Script?
5.1 On Apple devices
MPS backend is supported in torch 2.0 onwards. See the worked example by Thai Tran.
6 Diagnostics, debugging
6.1 Hooks
6.2 Pretty printing
6.3 Memory leaks
Apparently we use normal python garbage collector analysis.
A snippet that shows all the currently allocated Tensors:
See also usual python debugging. NB vs code has integrated PyTorch debugging support.
NB also — if any ipython line or jupyter cell returns a giant tensor it hangs around in memory, which is a very popular way to create memory leaks
6.4 Is the GPU working?
6.5 Logging and profiling
Leveraging TensorFlow’s handy diagnostic GUI, tensorboard: Now native, via torch.utils.tensorboard. See also the PyTorch Profiler documentation.
Easier: just use lighting if that fits the workflow.
Also I have seen visdom promoted? This pumps graphs to a visualisation server. Not PyTorch-specific, but seems well-integrated.
Further generic profiling and logging at the NN-in-practice notebook.
6.6 Visualising network graphs
Fiddly. The official way is via ONNX.
Then one can use various graphical model diagrams things.
Also available, pytorchviz and tensorboardX support visualising PyTorch graphs.
7 Structured (multi-)linear algebra
Handy for matrix factorisation tricks etc.
7.1 Einstein convention
Einstein convention is supported by PyTorch as torch.einsum.
Einops (Rogozhnikov 2022) is more general. It is not specific to PyTorch, but the best tutorials are for PyTorch:
Note that there was a hyped project, Tensor Comprehensions in PyTorch (see the launch announcement) which apparently compiled the operations to CUDA kernels. It seems to be discontinued.
7.2 LinearOperator
A linear operator is a generalization of a matrix. It is a linear function that is defined in by its application to a vector. The most common linear operators are (potentially structured) matrices, where the function applying them to a vector are (potentially efficient) matrix-vector multiplication routines.
LinearOperator objects share (mostly) the same API as
torch.Tensorobjects. Under the hood, these objects use__torch_function__to dispatch all efficient linear algebra operations to thetorchandtorch.linalgnamespaces. […]Each of these functions will either return a
torch.Tensor, or a newLinearOperatorobject, depending on the function.
7.3 KeOps
The KeOps library lets you compute reductions of large arrays whose entries are given by a mathematical formula or a neural network. It combines efficient C++ routines with an automatic differentiation engine and can be used with Python (NumPy, PyTorch), Matlab and R.
It is perfectly suited to the computation of kernel matrix-vector products, K-nearest neighbors queries, N-body interactions, point cloud convolutions and the associated gradients. Crucially, it performs well even when the corresponding kernel or distance matrices do not fit into the RAM or GPU memory. Compared with a PyTorch GPU baseline, KeOps provides a x10-x100 speed-up on a wide range of geometric applications, from kernel methods to geometric deep learning.
8 Custom Functions
There is (was?) some bad advice in the manual:
nnexports two kinds of interfaces — modules and their functional versions. You can extend it in both ways, but we recommend using modules for all kinds of layers, that hold any parameters or buffers, and recommend using a functional form parameter-less operations like activation functions, pooling, etc.
Important missing information:
If my desired loss is already just a composition of existing functions, I don’t need to define a Function subclass.
And: The given options are not a binary choice, but two things we need to do in concert. A better summary would be:
- If you need to have a function which is differentiable in a non-trivial way, implement a
Function- If you need to bundle a
Functionwith some state or updatable parameters, additionally wrap it in ann.Module
Some people claim you can also create custom layers using plain python functions. However, these don’t work as layers in an nn.Sequential model at the time of writing, so I’m not sure how to take such advice.
9 Fancy gradients
Hessians, stochastic gradients etc. Some of this is handled in modern times by torch.func
9.1 Stochastic gradients
There is some stochastic gradient infrastructure in pyro, in the sense of differentiation through integrals, both classic score methods, reparameterisations and probably others. See, e.g. Storchastic (van Krieken, Tomczak, and Teije 2021).
9.2 ASD(FGHJK)L
kazukiosawa/asdfghjkl: ASDL: Automatic Second-order Differentiation (for Fisher, Gradient covariance, Hessian, Jacobian, and Kernel) Library (Osawa et al. 2023)
The library is called ASDL, which stands for Automatic Second-order Differentiation (for Fisher, Gradient covariance, Hessian, Jacobian, and Kernel) Library. ASDL is a PyTorch extension for computing 1st/2nd-order metrics and performing 2nd-order optimization of deep neural networks.
Used in Daxberger et al. (2021).
9.3 backpack
backpack.pt/ (Dangel, Kunstner, and Hennig 2019)
Provided quantities include:
- Individual gradients from a mini-batch
- Estimates of the gradient variance or second moment
- Approximate second-order information (diagonal and Kronecker approximations)
Motivation: Computation of most quantities is not necessarily expensive (often just a small modification of the existing backward pass where backpropagated information can be reused). But it is difficult to do in the current software environment.
Documentation mentions the following capabilities: estimate of the Variance, the Gauss-Newton Diagonal, the Gauss-Newton KFAC
Source: f-dangel/backpack.
9.4 PyHessian
amirgholami/PyHessian: PyHessian is a Pytorch library for second-order based analysis and training of Neural Networks (Yao et al. 2020):
PyHessian is a pytorch library for Hessian based analysis of neural network models. The library enables computing the following metrics:
- Top Hessian eigenvalues
- The trace of the Hessian matrix
- The full Hessian Eigenvalues Spectral Density (ESD)
9.5 Regularization gradients
One can hack the backward gradient to impose regularising penalties, but why not just use one of the pre-rolled ones by Szymon Maszke?
10 Advanced optimisation
- Welcome to pytorch-optimizers documentation! — pytorch-optimizers 2.8.0 documentation
- jettify/pytorch-optimizer: torch-optimizer – collection of optimizers for Pytorch
10.1 Parameterizations
Lezcano/geotorch: Constrained optimization toolkit for PyTorch (Lezcano Casado 2019).
10.2 Constrained optimisation
Cooper is a toolkit for Lagrangian-based constrained optimization in Pytorch. This library aims to encourage and facilitate the study of constrained optimization problems in machine learning.
wesselb/varz: “Painless optimization of constrained variables in AutoGrad, TensorFlow, PyTorch, and JAX”.
11 Probabilistic programming
There is a lot to say here; For me at least, probabilistic programming is the killer app of pytorch; Various frameworks do clever probabilistic things, notably pyro.
12 Curve interpolation, quadrature, and ODEs
- torchdiffeq has much ODE stuff, but seems to have been abandoned at python 3.6
- google-research/torchsde: Differentiable SDE solvers with GPU support and efficient sensitivity analysis. has also not been touched recently but supports more pythons
- torchdyn /DiffEqML/torchdyn: A PyTorch library entirely dedicated to neural differential equations, implicit models and related numerical methods
Generic interpolation in xitorch
xitorch (pronounced “sigh-torch”) is a library based on PyTorch that provides differentiable operations and functionals for scientific computing and deep learning. xitorch provides analytic first and higher order derivatives automatically using PyTorch’s autograd engine. It is inspired by SciPy, a popular Python library for scientific computing.
NB, works in only one index dimension.
13 Recurrent nets
It’s just as well it’s easy to roll your own recurrent nets because the default implementations are bad
The default RNN layers are optimised using cuDNN, which is sweet. Probably for that reason we only have a choice of 2 activation functions, and neither of them is “linear”; There is tanH and ReLU.
A DIY approach might fix this, e.g. if we subclassed RNNCell. Recent pytorch includes JITed RNN which might even make this DIY style performant. I have not used it. Everyone uses transformers these days instead, anyway.
14 Distributed
The default cluster modes of python behave weirdly for pytorch tensors and especially gradients. They have their own clone of python.multiprocessing. Multiprocessing best practices
15 EZ wrappers
There are libraries built on pytorch which make common tasks easy. I am not a fan of these because they do not seem to help my own tasks.
15.1 Lightning
Lightning is a common training/utility framework for Pytorch.
Lightning is a very lightweight wrapper on PyTorch that decouples the science code from the engineering code. It’s more of a style-guide than a framework. By refactoring your code, we can automate most of the non-research code.
To use Lightning, simply refactor your research code into the LightningModule format (the science) and Lightning will automate the rest (the engineering). Lightning guarantees tested, correct, modern best practices for the automated parts.
- If you are a researcher, Lightning is infinitely flexible, you can modify everything down to the way
.backwardis called or distributed is set up.- If you are a scientist or production team, lightning is very simple to use with best practice defaults.
Why do I want to use lightning?
Every research project starts the same, a model, a training loop, validation loop, etc. As your research advances, you’re likely to need distributed training, 16-bit precision, checkpointing, gradient accumulation, etc.
Lightning sets up all the boilerplate state-of-the-art training for you so you can focus on the research.
These last two paragraphs constitute a good introduction to the strengths and weaknesses of lightning: “Every research project starts the same, a model, a training loop, validation loop” stands in opposition to “Lightning is infinitely flexible”. An alternative description with different emphasis which would IMO be better: “Lighting can handle many ML projects that naturally factor into a single training loop but does not help so much for other projects.”
If my project does have such a factorisation, Lightning is extremely useful and will do all kinds of easy parallelisation, natural code organisation and so forth. But if I am doing something like posterior sampling, or nested iterations, or optimisation at inference time, I find myself spending more time fighting the framework than working with it.
If I want the generic scaling up, I might find myself trying one of the generic solutions like Horovod.
15.1.1 Lightning tips
Like python itself, much messy confusion is involved in making everything seem tidy and obvious.
The Trainer class is hard to understand because it is an object defined across many files and mixins with confusing names.
One useful thing to know is that a Trainer has a model member which contains the actual LightningModule that I am training.
If I subclass ModelCheckpoint then I feel like the on_save_checkpoint method should be called as often as _save_model; but they are not. 🚧TODO🚧: investigate this.
on_train_batch_end does not get access to anything output by the batch AFAICT, only the epoch-end callback gets the output argument filled in. See the code comments.
15.2 Fabric
Fabric differentiates itself from a fully-fledged trainer like Lightning’s Trainer in these key aspects:
Fast to implement There is no need to restructure your code: Just change a few lines in the PyTorch script and you’ll be able to leverage Fabric features.
Maximum Flexibility Write your own training and/or inference logic down to the individual optimizer calls. You aren’t forced to conform to a standardized epoch-based training loop like the one in Lightning Trainer. You can do flexible iteration based training, meta-learning, cross-validation and other types of optimization algorithms without digging into framework internals. This also makes it super easy to adopt Fabric in existing PyTorch projects to speed-up and scale your models without the compromise on large refactors. Just remember: With great power comes a great responsibility.
Maximum Control The Lightning Trainer has many built-in features to make research simpler with less boilerplate, but debugging it requires some familiarity with the framework internals. In Fabric, everything is opt-in. Think of it as a toolbox: You take out the tools (Fabric functions) you need and leave the other ones behind. This makes it easier to develop and debug your PyTorch code as you gradually add more features to it. Fabric provides important tools to remove undesired boilerplate code (distributed, hardware, checkpoints, logging,…), but leaves the design and orchestration fully up to you.
Sebastian Rascka’s blog post motivates this well: Optimising Memory Usage for Training LLMs and Vision Transformers in PyTorch.
15.3 Catalyst
I think Catalyst fills a similar niche to lightning? Not sure, have not used. The Catalyst homepage blurb seems to hit the same notes as lightning with a couple of sweeteners - e.g. it claims to support jax and tensorflow.
15.4 fast.ai
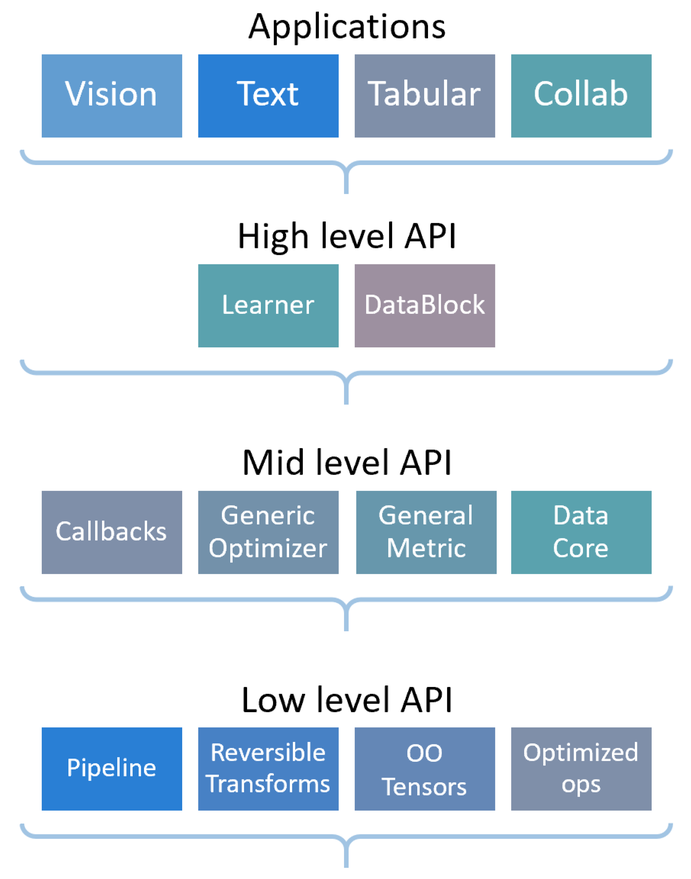
fastai is a deep learning library which provides practitioners with high-level components that can quickly and easily provide state-of-the-art results in standard deep learning domains, and provides researchers with low-level components that can be mixed and matched to build new approaches. It aims to do both things without substantial compromises in ease of use, flexibility, or performance. This is possible thanks to a carefully layered architecture, which expresses common underlying patterns of many deep learning and data processing techniques in terms of decoupled abstractions. These abstractions can be expressed concisely and clearly by leveraging the dynamism of the underlying Python language and the flexibility of the PyTorch library. fastai includes:
- A new type dispatch system for Python along with a semantic type hierarchy for tensors
- A GPU-optimized computer vision library which can be extended in pure Python
- An optimizer which refactors out the common functionality of modern optimizers into two basic pieces, allowing optimization algorithms to be implemented in 4–5 lines of code
- A novel 2-way callback system that can access any part of the data, model, or optimizer and change it at any point during training
- A new data block API
16 Domain libraries
- DSP
-
I am thinking especially of audio. Keunwoo Choi produced some beautiful examples, e.g. Inverse STFT, Harmonic Percussive separation.
Today we have torchaudio. See also, rom Dorrien Herremans’ lab, nnAudio (Source), which is similar but has fewer dependencies.
- NLP
-
Like other deep learning frameworks, there is some basic NLP support in PyTorch; see pytorch.text.
flair is a commercially-backed NLP framework.
I do not do much NLP but if I did, I might use the helpful utility functions in AllenNLP.
allenai/allennlp: An open-source NLP research library, built on PyTorch.
- Computer vision
-
In addition to the natively supported torchvision, there is Kornia, a differentiable computer vision library for PyTorch. It includes such niceties as differentiable image warping via the grid_sample thing.
Geospatial
- torchgeo is one geospatial dataset loader/trainder system. Source at microsoft/torchgeo (Stewart et al. 2022)
- Raster Vision is “An open-source machine learning library for deep learning on satellite and aerial imagery”. Source is azavea/raster-vision / documentation
See more tricks under Spatiotemporal NNs
17 Evolution
Genetic programming in PyTorch? Why not?
PyGAD, “a Python 3 library for building the genetic algorithm and training machine learning algorithms”
evotorch “Advanced evolutionary computation library built directly on top of PyTorch, created at NNAISENSE”