Improving peer review
Incentives for truth seeking at the micro scale and how they might be improved
2020-05-16 — 2026-03-09
Wherein Review Credits Are Required for Submission, Assignments Are Randomized to Deter Collusion, and Disputes Are Subjected to Bounded AI Arbitration Amid Journal and Conference Contrasts.
On designing peer review systems for validating scientific output.
Reputation systems, collective decision-making, managing groupthink, Bayesian elicitation, and other mechanism considerations for trustworthy evaluation of science, a.k.a. our collective knowledge of reality itself.
1 Understanding the Review Process
If we come from “classic” journals and wander into ML conferences, the ground rules really are different. If we come from outside research, the whole thing may seem bizarre. Let’s unpack the two main variants of peer review that show up in my corner of the world; I’m not claiming this is representative of every scientific field, and it probably has little to do with the humanities.
1.1 Classic journals
Most journals run rolling submissions with editor triage (desk rejections), assignment to volunteer referees (often 2–3), and potentially multiple rounds over months to a year. Blinding varies by field (single- vs double-blind). A growing trend is transparent peer review, where reviewer reports (and sometimes author replies and editorial decisions) are published alongside the article—now standard at Nature for accepted papers, building on earlier opt-in pilots.
1.2 ML conferences

For example, NeurIPS and ICLR. The benchmark-heavy world of machine learning has a slightly different implied scientific method than most empirical science fields, so the details of peer review can differ (Hardt 2026).
The review process is different too. Big ML conferences run in batches, on deadline-driven cycles with thousands of submissions. After a call for papers, there’s bidding/assignment, double-blind review (3–6 reviewers), an author response window, and a discussion moderated by an area chair who apparently does not sleep for the duration of the discussion period. Final decisions are aggregated (read: declared) by senior chairs. Timelines are measured in weeks, not months. In ICLR, the whole thing plays out in public on OpenReview (public comments + author revisions during the discussion period), while NeurIPS runs standard double-blind review with AC-led discussions and rebuttals. See also current venue pages for concrete expectations—for example, NeurIPS reviewer responsibilities for a flavour.
TIL OpenReview.net started as a workshop paper proposal: Soergel, Saunders, and McCallum (2013):
Across a wide range of scientific communities, there is growing interest in accelerating and improving the progress of scholarship by making the peer review process more open. Multiple new publication venues and services are arising, especially in the life sciences, but each represents a single point in the multi-dimensional landscape of paper and review access for authors, reviewers and readers. In this paper, we introduce a vocabulary for describing the landscape of choices regarding open access, formal peer review, and public commentary. We argue that the opportunities and pitfalls of open peer review warrant experimentation in these dimensions, and discuss desiderata of a flexible system. We close by describing OpenReview.net, our web-based system in which a small set of flexible primitives support a wide variety of peer review choices, and which provided the reviewing infrastructure for the 2013 International Conference on Learning Representations. We intend this software to enable trials of different policies, in order to help scientific communities explore open scholarship while addressing legitimate concerns regarding confidentiality, attribution, and bias.
2 Hybrids and experiments
2.1 TMLR
TMLR (Transactions on Machine Learning Research). Rolling submissions with journal-style reviewing aimed at shorter, conference-shaped ML papers: fast turnaround, double-blind, and public reviews on OpenReview once accepted. In practice, it sits between a conference and a traditional journal in cadence and openness. (Related: [Journal of Machine Learning Research][https://jmlr.org])
2.2 eLife’s “Reviewed Preprint”
eLife’s “Reviewed Preprint” (since 2023). eLife reviews preprints and publishes public reviews and an editorial assessment; it doesn’t issue accept/reject decisions in the classic sense. This explicitly separates evaluation from gatekeeping.
2.3 F1000
F1000Research (and F1000). Publishes first, then reviews; peer review is fully open (reviewer names and reports), and versions can be updated in response. It’s the clearest example of post-publication, transparent review at scale.
2.4 The Unjournal
The Unjournal does some post-publication review that I’m super interested in:
The Unjournal is making research better by evaluating what really matters. We aim to make rigorous research more impactful and impactful research more rigorous.
The academic journal system is out of date, discourages innovation, and encourages rent-seeking.
The Unjournal is not a journal. We don’t publish research. Instead, we commission (and pay for) open, rigorous expert evaluation of publicly-hosted research. We make it easier for researchers to get feedback and credible ratings of their work, so they can focus on doing better research rather than journal-shopping.
We currently focus on quantitative work that informs global priorities, especially in economics, policy, and social science. We focus on what’s practically important to researchers, policy-makers, and the world.
Their process is documented online: recommended reading for anyone interested in peer review reform.
3 Theories of Peer Review
These ecosystems imply different incentives and failure modes. Conferences optimize for speed and triage under load (good for timely results; vulnerable to assignment noise, miscalibration, and strategic behaviour). Journals optimize for depth and iteration (good for careful revisions; vulnerable to long delays and opacity, though transparency is improving).
Researchers have long attempted to understand the dynamics of the reviewing process through mathematical models (e.g., Cole, Jr, and Simon (1981); Lindsey (1988); Whitehurst (1984)). These models often explore how chance, bias, and reviewer reliability affect outcomes.
NeurIPS has made a habit of testing its own review process meta-scientifically, and trying to improve it. This empirical turn has shifted the focus towards evidence-based interventions (see Nihar B. Shah et al. 2016; Ragone et al. 2013) and towards analyses of the 2014 NIPS experiment, (see also this). I am focusing on ML research here, but I think a lot of these ideas will carry over.
4 The Parts of Peer Review Mechanisms
A fundamental difficulty in peer review (as in, well every human system) is aligning the incentives of the participants with the goals of the system. Reviewing is often time-consuming and poorly compensated, either financially or professionally. Furthermore, social dynamics and status incentives—such as the potential social cost of rejecting a prominent author’s work—often shape reviewer behaviour more strongly than abstract commitments to quality.
Many attempts to improve peer review focus on process tweaks that fail to address this underlying payoff matrix. However, recent work in mechanism design suggests several structural approaches that might reorient incentives towards more effortful and truthful evaluations. These often involve (A) linking the roles of author and reviewer, (B) introducing randomness to deter manipulation, and (C) using sophisticated methods to elicit and score judgments.
The following sections explore these proposals and others derived from the literature that could be considered for an experimental journal design.
4.2 Strategic Use of Randomness
The process of assigning reviewers to papers is crucial, yet vulnerable. If the assignment process is too predictable, it can be manipulated. Authors might attempt to influence assignments to secure favourable reviewers, and reviewers might engage in “bidding” strategies to review specific papers. Furthermore, deterministic assignment processes can make it difficult to conduct clean experiments on the review process itself and may inadvertently compromise anonymity.
Introducing controlled randomness into reviewer assignment and process design can act as an prophylactic against these issues (Y. E. Xu et al. 2024; Jecmen et al. 2022; Stelmakh, Shah, and Singh 2021).
Specific Approaches:
Modern methods for randomized assignment aim to maintain high match quality (based on expertise) while incorporating randomness to improve robustness against manipulation and facilitate A/B testing of policies. NeurIPS piloted such an approach in 2024, reporting similar assignment quality with added benefits (NeurIPS 2024 postmortem).
In multi-phase review designs, randomly splitting the reviewer pool—saving a random subset for later phases—has been shown to be near-optimal for maintaining assignment similarity and enabling clean experiments (Jecmen et al. 2022).
Beyond randomness, the assignment objective itself can be reconsidered. Instead of maximizing total similarity (which might leave some papers with poor matches), one might aim for max-min review quality (“help the worst-off paper”). Algorithms like PeerReview4All attempt to optimize for fairness while maintaining competitive accuracy (Stelmakh, Shah, and Singh 2021).
While randomness might slightly reduce the quality of the single “best match” in some cases, the gains in robustness to collusion and the ability to evaluate the system often outweigh this cost (Nihar B. Shah et al. 2016; Nihar B. Shah 2025).
4.3 Post publication review and open discussion
TBD
4.4 Eliciting Better Judgments through Forecasting and Scoring
Traditional peer review often relies on simple scoring rubrics, which may not capture the nuance of a reviewer’s judgment or incentivize truthful reporting. An alternative approach is to ask reviewers for probabilistic forecasts about observable future outcomes and evaluate these forecasts using proper scoring rules](./calibration.qmd) and the other machinery of Bayesian elicitation.
Proper scoring rules (like the log or Brier score) are designed such that a reviewer maximizes their expected score by reporting their true beliefs (Gneiting and Raftery 2007). For example, reviewers could be asked to forecast the probability that an independent audit will replicate the main claim, or the probability that an arbiter will flag a major error.
Over time, as outcomes are observed, this approach allows the system to calibrate reviewers and identify those who are consistently informative. This can be combined with machine learning techniques to aggregate criteria-to-decision mappings, reducing the impact of idiosyncratic weights (Noothigattu, Shah, and Procaccia 2021).
Another interesting mechanism involves eliciting information from authors themselves. The You are the best reviewer of your own paper mechanism proposes eliciting an author-provided ranking among their own submissions. When combined with reviewer scores, this information seems to improve decision quality (Su 2021) (IMO surprisingly, the incentives seem off).
The primary challenge in implementing these methods is defining outcomes that can be observed within a reasonable timeframe (e.g., an internal audit verdict rather than long-term citations).
4.5 Calibration and aggregation of ratings
A persistent challenge in evaluating reviews is that reviewers use scoring rubrics (i.e. scores from 1 to 10 or whatever) differently. Although reviewers all use the same nominal scale when assessing a paper, their scores are often not well calibrated to one another. Some reviewers may be systematically harsher or more lenient. This is a familiar problem in survey methodology, where respondents’ scores are, at best, internally consistent.
Simply averaging the scores can be problematic, as it “bakes in” this miscalibration. Furthermore, as we know from social choice theory, simple averaging may not be the optimal way to aggregate different perspectives. The literature suggests several approaches that might improve the aggregation process:
- Community-learned aggregation: Instead of assuming a fixed relationship between aspect scores (e.g., novelty, rigour) and the overall recommendation, we can learn a mapping (e.g., L(1,1)-style) that reflects the community’s preferences. This helps reduce the impact of individual reviewers’ idiosyncratic weighting schemes (Noothigattu, Shah, and Procaccia 2021).
- Calibration with confidence: Asking reviewers to provide not just a score but also a confidence level can help in calibration. By analysing confidence across the panel graph, it may be possible to adjust for differences in scale usage and leniency (MacKay et al. 2017).
- Least-squares calibration: This framework offers a flexible approach to correcting for bias and noise beyond simple linear miscalibration (Tan et al. 2021). TODO: revisit this one — it sounds fun.
A simpler approach might involve collecting confidence signals and learning a post-hoc transformation to map each reviewer’s scores to a shared scale.
4.6 Eliciting Truth without Ground Truth
Rewarding high-quality reviews is difficult when there is no objective “ground truth” against which to measure them. Peer-prediction mechanisms, such as the Bayesian Truth Serum (Prelec 2004) and Peer Truth Serum (Radanovic, Faltings, and Jurca 2016), offer a theoretical way to incentivize honest and effortful reports by comparing reviewers’ reports against each other. These mechanisms have inspired concrete designs for peer review, including proposals for auction-funded reviewer payments scored via peer prediction (Srinivasan and Morgenstern 2023).
However, these mechanisms introduce significant conceptual and UX complexity and can be brittle under conditions of collusion or correlated errors. For these reasons, they may be challenging to implement initially. A lighter alternative might be to combine forecast scoring with post-hoc audits to generate observable outcomes.
4.7 AI-Assisted Review
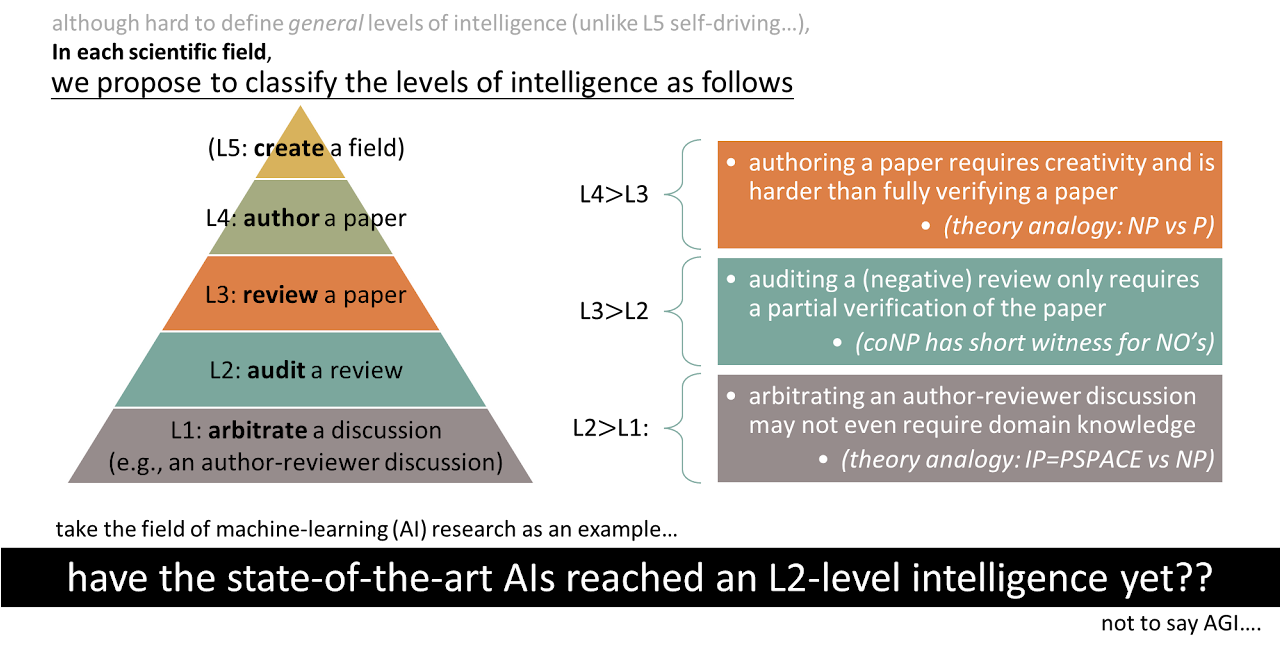
The back-and-forth between authors and reviewers, especially during rebuttals, can be productive and helpful in principle, but it’s inconsistent in practice. Meta-reviewers can struggle to adjudicate complex technical disputes quickly.
A recent proposal suggests adding a bounded-round arbitration step using AI adjudicators (Allen-Zhu and Xu 2025). The idea is that arbitration (analysing an existing dispute) may be cognitively easier than full reviewing (generating a novel critique), and that today’s language models may already be competent enough (L1 or L2 competence) in some domains. See the CF debate protocols and other scalable-oversight-style alignment ideas.
In such a protocol, after authors submit a structured rebuttal to reviewer comments, an AI arbitrator (using a standardized prompt and fixed turns) evaluates specific contested points and issues a finding with a confidence score and citations to the text. Human meta-reviewers then consider this finding alongside the original human reviews. Key design features include bounded rounds of interaction, giving authors the last word (to offset the advantages reviewers get from anonymity), and logging all arbitrator chats for auditability (Allen-Zhu and Xu 2025).
Potential benefits include increased consistency, immediate logic checks, and a searchable audit trail. A neutral arbitrator may also lower the social costs (“face costs”), making it easier for reviewers and authors to admit errors. However, challenges include model variance, domain gaps (e.g., in mathematics-heavy areas), and the need for careful governance.
See also AI agents in science for more hands-on ideas about AI roles in parts of the research workflow other than review.
There are many variants on the theme of AI-assisted review, including AI-generated initial reviews, AI-summarized discussions, and AI-flagged statistical checks.
See also
SakanaAI/AI-Scientist: The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery 🧑🔬 / The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery (Lu et al. 2024)
They say this is about scientific research generation, but I think it’s also about peer review, because peer review ends up as part of their workflow.
The Black Spatula Project — Steve Newman
A 10 page paper caused a panic because of a math error. I was curious if AI would spot the error by just prompting: “carefully check the math in this paper” especially as the info is not in training data.
o1 gets it in a single shot. Should AI checks be standard in science?
Repository: nick-gibb/black-spatula-project: Verifying scientific papers using LLMs
Also, there are many articles on this(Couto et al. 2024; Kim, Lee, and Lee 2025; Kuznetsov et al. 2024; Liang et al. 2024; R. Liu and Shah 2023; Lu et al. 2024; Ye et al. 2024).
4.8 Collusion and Identity Fraud
The integrity of the peer review process is threatened by various forms of manipulation. Documented issues include collusion rings (where authors agree to review each other’s papers favourably) and targeted assignment gaming (Littman 2021). Identity theft of reviewer accounts has also become a concern; a recent report uncovered 94 fake reviewer profiles on OpenReview (Nihar B. Shah 2025).
Several design features can help mitigate these risks:
- Randomness in assignments significantly reduces the probability that targeted attempts to influence assignments will succeed (Jecmen et al. 2020; Y. E. Xu et al. 2024).
- Cycle-free assignment constraints prohibit simple reciprocal arrangements (e.g., cycles of length ≥2 among author—reviewer pairs) (Boehmer, Bredereck, and Nichterlein 2022).
- Enhanced identity verification for reviewers (e.g., ORCID, verifiable employment, or one-time checks) can help combat fake profiles.
More advanced proposals include pseudonymous persistent reviewer IDs with public reputation scores, linked to admission-control credits, although these are more complex to implement.
4.9 Automated Screening and Checks
Automated tools can supplement the human review process by screening for common issues.
- Statistical auditing: Tools like Statcheck can automatically parse manuscripts and flag basic statistical inconsistencies. A natural experiment suggests that implementing such checks in the workflow can lead to large reductions in reporting errors (Nuijten and Wicherts 2024).
- Reproducibility checks: For computational work, journals can require authors to submit an “auditability pack” (e.g., environment details, code, tests) and run basic execution checks upon submission.
It’s (morally speaking) important to treat the output of these tools as a triage signal for editors and reviewers, rather than a basis for automatic rejection, as false positives are expected. Whether these tools produce fewer false positives than humans is an empirical question.
4.10 Anonymity and Bias
The debate over anonymity in peer review (single-blind vs. double-blind vs. open review) is ongoing, with various trade-offs well-known by now:
- Empirical evidence suggests that double-blind review can reduce prestige bias in some settings (Okike et al. 2016).
- Open review (signed) has mixed evidence regarding its impact on review quality and can reduce reviewer willingness to participate (van Rooyen et al. 1999).
- Concerns about herding in discussions (where early comments overly influence later ones) were not supported by a large randomized controlled trial at ICML, which found no evidence that the first discussant’s stance determined the outcome (Stelmakh, Rastogi, Shah, et al. 2023).
- Observational evidence suggests a potential citation bias, where reviewers may respond more favorably when their own work is cited by the authors (Stelmakh, Rastogi, Liu, et al. 2023).
Given these findings, a hybrid approach might work. We could maintain double-blind conditions during initial reviews, then reveal identities after initial scores are submitted. This “middle ground” aims to balance reducing bias with the benefits of contextual reading and COI checks (Nihar B. Shah 2025).
5 Designing an Experimental Journal
Thought experiment: what should we do if we launched a hypothetical new green-field journal, assuming time and money were no object?
Translating these theoretical proposals and experimental findings into the design of a new journal requires careful consideration of implementation costs and the specific goals of the journal. A pragmatic approach might involve layering several interventions that are compatible with a small editorial team and limited budget, and running incremental experiments to evaluate their impact.
Based on the literature surveyed, several components appear promising for an initial pilot:
- Incentive Alignment via Admission Control: Implementing a review credit system to link author submissions with review contributions. Using stochastic penalties (e.g., heavier scrutiny for non-compliant authors) rather than hard bans is crucial when effort measurement is noisy.
- Robust and Fair Assignment: Adopting randomized assignment methods with a fairness objective can improve robustness to manipulation and ensure equitable distribution of review quality (Stelmakh, Shah, and Singh 2021; Y. E. Xu et al. 2024). This requires a one-time engineering effort.
- Improved Evaluation Metrics: Moving beyond simple averaging by incorporating calibrated aggregation and forecast questions with proper scoring rules. Collecting aspect scores and confidence levels allows for post-hoc calibration (Noothigattu, Shah, and Procaccia 2021; MacKay et al. 2017). Forecasts can be rewarded with review credits (converted to benefits like fee waivers) rather than cash.
- Hybrid Anonymity: Employing a “middle-ground reveal” —blind through initial reviews, then revealing identities—to balance bias reduction with contextual checks (Nihar B. Shah 2025).
- Supplemental Checks: Integrating automated triage for statistical or reproducibility checks (Nuijten and Wicherts 2024). Potentially introducing a bounded AI arbitration step to assist meta-reviewers in resolving specific disputes (Allen-Zhu and Xu 2025).
- Anti-Collusion Measures: Enforcing cycle-free constraints and randomized assignments (Jecmen et al. 2020; Boehmer, Bredereck, and Nichterlein 2022).
- Cash Payments for Reviews. Direct cash payments or cryptocurrency mechanisms (DOGE 2.0 vision (Allen-Zhu and Xu 2025)) involve complex accounting and policy issues. Starting with a credits-for-benefits system sounds more practical. But cash is immediately understandable and fungible, so it might be worth piloting in a small setting.
- Lotteries for Acceptance. Pure lotteries for acceptance, while used by some funding agencies with mixed results (Feliciani, Luo, and Shankar 2024; M. Liu et al. 2020), may be controversial for journals. Improving incentives and calibration should probably take precedence, although a lottery within a narrow “tie band” might be worthwhile.
6 Incoming

Primary Paper Initiative – IJCAI 2026 (Charge authors for each paper after the first, and require a paper trail of previous rejections)
Matthew Feeney, Markets in fact-checking
Transparent Peer Review: A New Era for Scientific Publishing | The Scientist
CS Paper Reviews — a tool for reviewing submissions and boosting our chances of acceptance
Saloni Dattani, Real peer review has never been tried
Matt Clancy, What does peer review know?
Adam Mastroianni, The rise and fall of peer review
Science and the Dumpster Fire | Elements of Evolutionary Anthropology
F1000Research | Open Access Publishing Platform | Beyond a Research Journal
F1000Research is an Open Research publishing platform for scientists, scholars and clinicians offering rapid publication of articles and other research outputs without editorial bias. All articles benefit from transparent peer review and editorial guidance on making all source data openly available.
Reviewing is a Contract — Rieck on the social expectations around reviewing and chairing.
Jocelynn Pearl shares some fun ideas — including some blockchainy ones — in Time for a Change: How Scientific Publishing is Changing for the Better.