Validating and reproducing science
The systems that grind the chaos of noise into good results. Peer review, academic incentives, credentials, publishing…
2020-05-16 — 2025-09-30
Wherein the Mechanisms for Validating Scientific Claims Are Catalogued, the Replication Crisis and Publication Bias Are Examined, and Reforms Such as Pre‑registration and Registered Reports Are Outlined.
Empirical knowledge generation for universals, i.e.science, is a complicated, multifaceted socio-technical process. For the sake of tractability, we can model it in three phases: the generation of hypotheses, the dissemination of findings, and the validation of those findings. This post focuses on the validation: How does the scientific community assess, critique, and falsify scientific claims?
That is to ask, how do we, collectively, know what is true? This question has long been the domain of the history and philosophy of science, which examines how scientific knowledge is justified and progresses—whether through steady accumulation, rigorous falsification (Popper), or dramatic paradigm shifts (Kuhn). In practice, the modern scientific enterprise relies on a complex socio-technical machinery to separate signal from noise. This machinery includes peer review, funding bodies, reputation systems, and incentive mechanisms.
There are maaaaaany challenges we need to solve to align people with truth-seeking, which may not come naturally to us. These include reputation systems, collective decision making, groupthink management and other mechanisms for trustworthy science — a.k.a. our collective knowledge of reality itself. Because I’m a kind of meta-nerd, I think about this as a problem of epistemic community design, where we try to structure a community with the norms, conventions and economic incentives that lead to the best possible collective knowledge outcomes.
Ideally, this system should function as a filter, ensuring that only robust, reproducible findings enter, persist, and propagate in the canon of collective knowledge, while falsities are weeded out.
It’s not at all clear how well this works in the world as it is. Science loves studying itself, but it’s not great at overcoming inertia to self-correct its institutional failings. The “Replication Crisis”—the realization that many published findings, particularly in psychology, medicine, and economics, cannot be independently reproduced—has exposed flaws in how science validates itself.
This post sketches the landscape of scientific validation. We examine the institutions designed to ensure trustworthy science, explore why they fail (addressing issues like P-hacking and publication bias), and look at proposed reforms. The goal is to understand the gap between the ideal of truth-seeking and the reality of modern academic incentives.

1 The Stakes are Public Trust
Let’s anchor on the ideal that most scientists seem to have in mind — the Mertonian norms:
The four Mertonian norms (often abbreviated as the CUDO-norms) can be summarised as:
- communism: all scientists should have common ownership of scientific goods (intellectual property), to promote collective collaboration; secrecy is the opposite of this norm.
- universalism: scientific validity is independent of the sociopolitical status/personal attributes of its participants.
- disinterestedness: scientific institutions act for the benefit of a common scientific enterprise, rather than for specific outcomes or the resulting personal gain of individuals within them.
- organized skepticism: scientific claims should be exposed to critical scrutiny before being accepted: both in methodology and institutional codes of conduct.
The integrity of scientific validation is not purely an internal academic concern, furnishing the ivory towers. Science aims to inform critical decisions in public policy, healthcare, and technology, and to inform the public. This role implies a social contract: society provides funding and autonomy in exchange for reliable, vetted knowledge.
However, this trust isn’t automatic or unconditional; it must be continuously earned — or fought for. When the validation machinery fails—when findings are irreproducible, fraud occurs, or the literature is distorted by bias—it undermines the credibility of the entire enterprise. The erosion of trust is often a rational response to observed institutional behaviour, rather than simply public ignorance.
1.1 The Rational Basis for Skepticism
It is essential to acknowledge that public skepticism toward scientific institutions is often well-founded, rooted in historical and ongoing failures.
The influence of corporate interests on research outcomes is a significant, salient concern. As claimed by critics like Goldacre (2012), the pharmaceutical industry often controls the design, execution, and publication of research on its own products. This leads to pervasive publication bias, where negative results are suppressed, distorting the evidence base.
At the moment, people often point to the opioid crisis. Pharmaceutical companies deceptively marketed opioids as non-addictive, citing flawed or misrepresented literature. This demonstrates how industry interests can corrupt the validation process with catastrophic societal consequences. As historians Oreskes and Conway argued in Oreskes and Conway (2022), the strategy of manufacturing uncertainty to delay regulation—first perfected by the tobacco industry—remains a standard playbook for industries facing inconvenient scientific truths.
Historical abuses have also left scars, particularly among marginalized communities. For example, the infamous “Tuskegee Study of Untreated Syphilis” (1932–1972), where U.S. Public Health Service researchers withheld known treatments from Black men, remains a symbol of institutional betrayal. Research suggests the disclosure of this study contributed to lasting medical mistrust and measurable negative health outcomes (Alsan and Wanamaker 2018). (cf Nazi experiments, Henrietta Lacks, etc.)
These examples highlight that skepticism is often directed not at the scientific method itself, but at the institutions charged with implementing it.
1.2 Failures of Science Communication
The credibility problem is exacerbated by the way science is communicated. The incentives driving academic careers (novelty, impact, funding) often bleed into communication strategies, prioritizing hype over substance.
This is reinforced by the internal dynamics of science itself. A recent study found that papers that failed to replicate are cited significantly more often than those that succeeded (Serra-Garcia and Gneezy 2021). This suggests the system favours “interesting” or surprising results, regardless of their validity.
This tendency toward novelty creates a “hype pipeline” (Caulfield and Condit 2012). Academic pressures lead to exaggerated claims in papers, university press offices amplify those claims to attract media attention, and journalists prioritize sensational findings. Studies have shown that press releases frequently exaggerate the importance of findings while minimizing limitations (Sumner et al. 2014). This constant stream of “breakthroughs” sets the public up for disillusionment.
Furthermore, institutions sometimes prioritize messaging that encourages desired public behaviour over complete transparency. As sociologist Zeynep Tufekci argued, when public health authorities appear opaque or misleading (as seen in debates during the COVID-19 pandemic), it damages institutional credibility. Paternalistic messaging often backfires, as the public recognize inconsistency and interprets it as incompetence or deception.
1.3 Funding pressure
TBD — I really need to write this one up. It’s of general interest; one day I’ll be permitted to mention my personal experiences with industry pressure.
1.4 Do Your Own Research
In this environment of justified skepticism and communication failures, the rise of the “Do Your Own Research” (DYOR) phenomenon is understandable. It reflects a collapse of faith in established mediating institutions.
While the impulse behind DYOR frequently stems from legitimate critiques—the recognition that published research can be biased and that experts can be conflicted—the method doesn’t fix the institutional failures of mainstream science.
DYOR mistakes access to information (e.g., reading preprints or isolated studies) for the rigorous, collective process required to evaluate and synthesize it. An individual cannot solve the problems of P-hacking or publication bias alone; these require institutional reform.
Indeed, someone close to me died needlessly and slowly because they trusted their own research over medical advice. This shit is serious. At the same time, other people close to me have been ignored or shunned for questioning established narratives when they have direct evidence of adverse effects from medical treatments.
As researcher danah boyd argues, we are living through a crisis of epistemology—a disagreement about how we know whether something is true. In the digital age, DYOR often involves navigating an information landscape strategically polluted by media manipulation. Boyd warns that simplistic approaches to critical thinking—teaching people to doubt without providing robust frameworks for understanding—can backfire, making individuals more vulnerable to conspiratorial thinking.
The DYOR movement seems great at surfacing flaws in existing practice. It’s less good at producing calibrated criticism and synthesis, and it doesn’t offer a scalable mechanism for reliable scientific self-correction. It often leads individuals into alternative epistemic communities that lack rigorous validation processes.
The challenge for the scientific community is not to demand blind trust, but to earn it by reforming the internal mechanisms of validation and communication, making the enterprise demonstrably rigorous, transparent, and accountable.
2 The Machinery of Validation
The primary mechanism for validating scientific claims today is peer review, organized by academic journals and funding bodies.
2.1 The Evolution and Limits of Peer Review
It is often assumed that peer review is a timeless feature of the scientific process, but its current dominance is a relatively recent invention.
Baldwin (2018) notes:
Throughout the nineteenth century and into much of the twentieth, external referee reports were considered an optional part of journal editing or grant making. The idea that refereeing is a requirement for scientific legitimacy seems to have arisen first in the Cold War United States. In the 1970s, in the wake of a series of attacks on scientific funding, American scientists faced a dilemma: there was increasing pressure for science to be accountable to those who funded it, but scientists wanted to ensure their continuing influence over funding decisions. Scientists and their supporters cast expert refereeing—or “peer review,” as it was increasingly called—as the crucial process that ensured the credibility of science as a whole.
This history suggests peer review evolved as much to maintain professional autonomy as to ensure empirical rigour. Today its effectiveness is hotly debated: critics say it’s slow, biased, and often fails to detect errors. Adam Mastroianni argues in The rise and fall of peer review that the system often fails to deliver on its promises.
For a deeper dive, see peer review.
- Related question: How do we discover research to send for peer review?
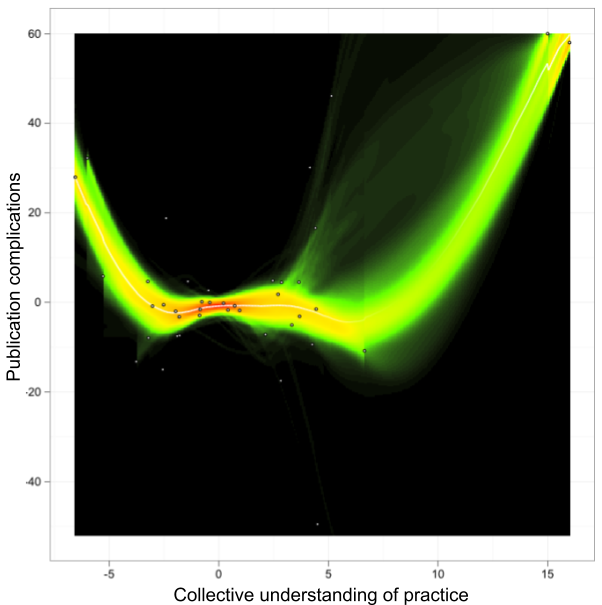
2.2 Gatekeeping and Institutional Culture
The validation process inherently involves gatekeeping. Institutions decide who can participate and which standards must be met. That helps explain why we’re perennially dissatisfied with academic culture.
Thomas Basbøll observes the tension between innovation and tradition:
It is commonplace today to talk about “knowledge production” and the university as a site of innovation. But the institution was never designed to “produce” something nor even to be especially innovative. Its function was to conserve what we know. It just happens to be in the nature of knowledge that it cannot be conserved if it does not grow.
This conservatism can make the validation process hostile to radically new ideas. (See Andrew Marzoni, Academia is a cult).
Friction in the traditional system leads some researchers to bypass that system entirely. Stephen Wolfram’s recent approach provides a telling example, as detailed by Adam Becker (Wolfram’s latest positioning):
So why did Wolfram announce his ideas this way? Why not go the traditional route? “I don’t really believe in anonymous peer review,” he says. “I think it’s corrupt. It’s all a giant story of somewhat corrupt gaming, I would say. I think it’s sort of inevitable that happens with these very large systems. It’s a pity”.
2.3 Grants
How does the funding mechanism shape what gets validated? Does the grant review process prioritize novelty over rigour? 🚧TODO🚧
3 Systemic Failures: The Replication Crisis
The replication crisis is the clearest sign that the validation machinery is broken. If peer review and statistical significance testing were working correctly, we’d expect most published findings to be robust. That hasn’t been the case.

Oliver Traldi reviews Stuart Ritchie’s book, Science Fictions, which outlines the crisis, particularly in social psychology:
Serious though this is, there is also something more specifically pernicious about the replication crisis in psychology. We saw that the bias in psychological research is in favour of publishing exciting results. An exciting result in psychology is one that tells us that something has a large effect on people’s behaviour. […] Think of the studies I mentioned above: a mess makes people more prejudiced; a random assignment of roles makes people sadistic; a list of words makes people walk at a different speed; a strange pose makes people more confident. And so on.
This crisis has structural causes: statistical malpractice and misaligned incentives.
See also: Sanjay Srivastava, Everything is fucked, the syllabus.
3.1 Publication Bias and the File Drawer
Journals prioritize novel, statistically significant findings. This creates a “publication sieve”.
Null results, or studies that fail to find an effect, are often relegated to the “file drawer”—they’re never published.
This leads to a distorted view of reality in the published literature. If 20 researchers each test a hypothesis, and only the one who (by chance) achieves \(P\leq 0.05\) publishes their result, the literature will suggest a strong effect where none exists. This is essentially multiple testing across an entire scientific field.
3.2 P-Hacking and Researcher Degrees of Freedom
For individual researchers, the pressure to publish significant results incentivizes “researcher degrees of freedom”—the many choices researchers make during data analysis that can be exploited (consciously or unconsciously) to push a result below the significance threshold. This is often called P-hacking.
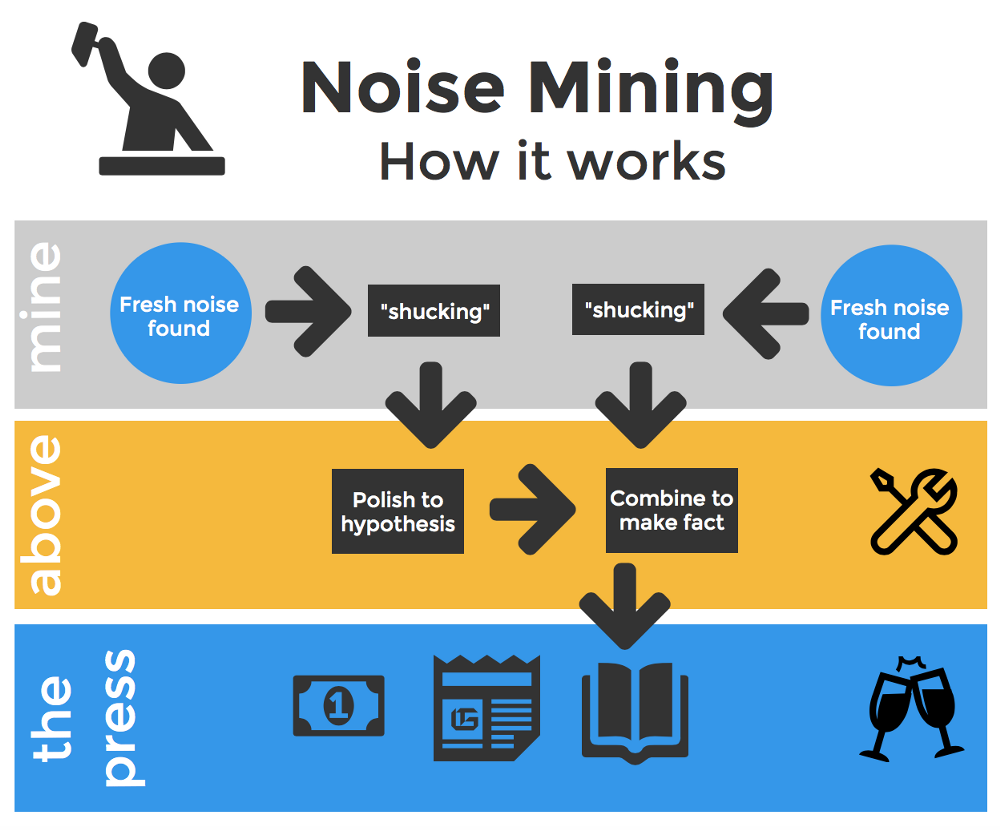
We can detect the signature of systematic p-hacking in the literature. See Uri Simonsohn’s work on the p-curve.
4 The Incentive Landscape

Why do these bad practices persist? Often they’re the rational response to the incentive structure of academic careers. Success (tenure, grants, acclaim) is often judged by the quantity and impact of publications, not by their rigour or reproducibility.
This can be formalised. Heesen and Journal of Philosophy Inc. (2018) argues that the reward structure of modern science pays out for priority — being first to publish a finding — rather than for reproducibility. Given that, every individual scientist is locally rational to rush to publish without checking; nobody is individually rewarded for replicating. The aggregate looks like the pathology we observe. The replication crisis is not a moral failing of individual scientists, it’s what we should expect from the rule set. The implication is that reforms aimed at individual behaviour — exhortations to be more rigorous — cannot do the work unless rigour is rewarded at the margin.
As Ed Hagen argues, academic success is either a crapshoot or a scam. The core problem is that rigorous science is slow and often produces null results, while academic careers push us to produce frequent, high-impact papers.
The problem, in a nutshell, is that empirical researchers have placed the fates of their careers in the hands of nature instead of themselves. […]
the minimum acceptable number of pubs per year for a researcher with aspirations for tenure and promotion is about three. This means that, each year, I must discover three important new things about the world. […]
Let’s say I choose to run 3 studies that each has a 50% chance of getting a sexy result. If I run 3 great studies, mother nature will reward me with 3 sexy results only 12.5% of the time. I would have to run 9 studies to have about a 90% chance that at least 3 would be sexy enough to publish in a prestigious journal.
I do not have the time or money to run 9 new studies every year.
This pressure creates a “natural selection of bad science” (Smaldino and McElreath 2016). If we let researchers inherit methods from successful predecessors — more publications means more students, who adopt the mentor’s practices — then low-power, inexpensive methods that produce publishable noise outcompete rigorous ones. Bad science is selected for, at the population level, not despite the system.
This is the same selection logic Julia Rohrer describes in her multi-stage survival procedure for methodological practices (below), but with the selection arrow explicitly drawn.
McElreath and Smaldino (2015) generalise the dynamics to community belief: the rate at which a community converges on truth depends not only on the quality of experiments but on the rate of attempted replication and the selective publication of confirming results. There are parameter regimes where the community is systematically misled — the field becomes more confident of the wrong answer the longer it keeps researching.
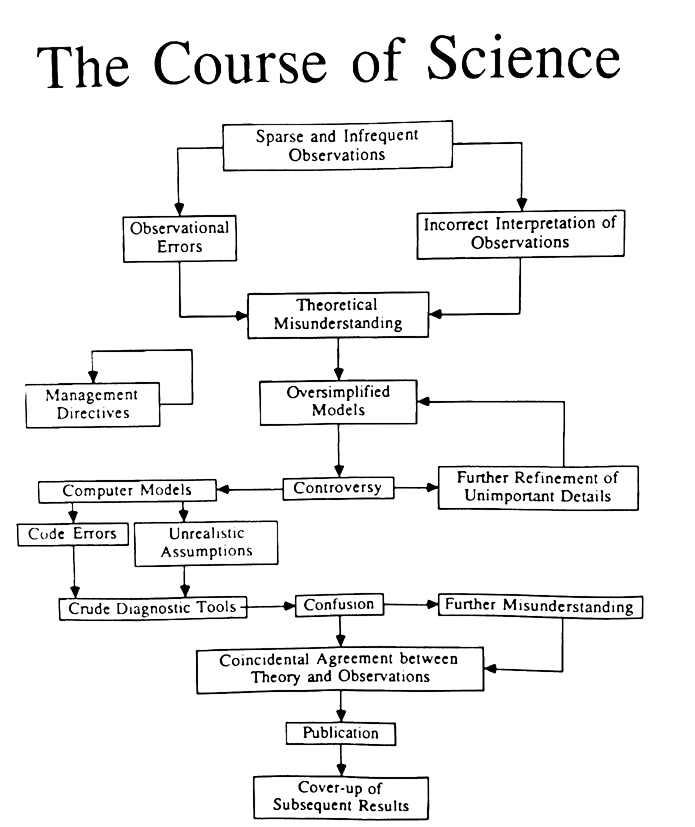
Julia Rohrer elaborates on how practices thrive in today’s ecosystem:
So, when does a certain practice […] “succeed” and start to dominate journals?
It must be capable of surviving a multi-stage selection procedure:
- Implementation must be sufficiently affordable so that researchers can actually give it a shot
- Once the authors have added it to a manuscript, it must be retained until submission
- The resulting manuscript must enter the peer-review process and survive it (without the implementation of the practice getting dropped on the way)
- The resulting publication needs to attract enough attention post-publication so that readers will feel inspired to implement it themselves, fueling the eternally turning wheel of ~~Samsara~~ publication-oriented science
Furthermore, Smaldino and O’Connor (2020) highlights how self-preferential biases can shelter poor methodology within scientific communities, making it hard for better methods to spread.
5 Reforming the System
In response to these systemic failures, we’ve seen various reforms proposed to improve the reliability of science. We can group them into methodological and structural reforms.
5.1 Transparency and Pre-registration
A major push is toward greater transparency to reduce researchers’ degrees of freedom. This includes open notebook science.
A key intervention is pre-registration, in which researchers specify their hypotheses, methods, and analysis plan before collecting data.
Tom Stafford’s 2-minute guide to experiment pre-registration explains the options:
- you can use the Open Science Framework to timestamp and archive a pre-registration, so you can prove you made a prediction ahead of time.
- you can visit AsPredicted.org which provides a form to complete…
- “Registered Reports”: more and more journals are committing to published pre-registered studies. They review the method and analysis plan before data collection and agree to publish once the results are in (however they turn out).
Registered reports are particularly useful for decoupling the publication decision from the results, potentially solving the incentive problem. However, they require more upfront work and may slow down the research process, which can clash with existing career incentives.
5.2 Review
5.2.1 Post-Publication Review
Traditional peer review is often slow, opaque, and unreliable. We’re seeing a shift toward post-publication review (PPPR), moving validation from a single gatekeeping event to a continuous process.
Andrew Gelman argues that post-publication review should be much more efficient than the current system. He also notes that the adversarial nature of traditional review trains scientists to be defensive rather than open to critique.
Platforms like PubPeer facilitate this by providing a forum for public commentary and critique of published papers. This system has been implicated in several high-profile retractions, demonstrating the power of decentralized scrutiny. Independent projects like Data Colada also play important roles in post-publication review, often uncovering errors and misconduct that traditional peer review misses. How sustainable is that, though? How much are the people behind these projects rewarded for their work? And how much of their time do they spend fending off lawsuits over their work?
The story behind the “Data falsificada” scandal is super juicy, by the way. See also
5.2.2 Institutional and Funding Reform
If the root cause is the incentive structure, the ultimate solution must involve changing how science is funded and how careers are evaluated. We’re seeing growing interest in structures that explicitly prioritize rigour over high-impact publications.
6 Emerging Tools
Discuss potential roles for AI/ML in validation, e.g., The Black Spatula Project (verifying scientific papers using LLMs). 🚧TODO🚧
7 Incoming

Why Science is Facing a Credibility Crisis — DeSci Foundation
Agent-Based Modeling in the Philosophy of Science (Stanford Encyclopedia of Philosophy)
CS Paper Reviews — a machine to review your paper and increase your odds of acceptance
Saloni Dattani, Real peer review has never been tried
Matt Clancy, What does peer review know?
Adam Mastroianni, The rise and fall of peer review
Étienne Fortier-Dubois, Why Is ‘Nature’ Prestigious?
Science and the Dumpster Fire | Elements of Evolutionary Anthropology
F1000Research | Open Access Publishing Platform | Beyond a Research Journal
F1000Research is an Open Research publishing platform for scientists, scholars and clinicians offering rapid publication of articles and other research outputs without editorial bias. All articles benefit from transparent peer review and editorial guidance on making all source data openly available.
Reviewing is a Contract - Rieck on the social expectations around reviewing and chairing.
Jocelynn Pearl proposes some fun ideas — including blockchain-y ones — in Time for a Change: How Scientific Publishing is Changing For The Better.
What methods work for evaluating the impact of public investments in RD&I
Smaldino and O’Connor (2020):
Why do bad methods persist in some academic disciplines, even when they have been clearly rejected in others? What factors allow good methodological advances to spread across disciplines? In this paper, we investigate some key features determining the success and failure of methodological spread between the sciences. We introduce a formal model that considers factors like methodological competence and reviewer bias towards one’s own methods. We show how self-preferential biases can protect poor methodology within scientific communities, and lack of reviewer competence can contribute to failures to adopt better methods. We then use a second model to further argue that input from outside disciplines, especially in the form of peer review and other credit assignment mechanisms, can help break down barriers to methodological improvement. This work therefore presents an underappreciated benefit of interdisciplinarity.
-
when does a certain practice–e.g., a study design, a way to collect data, a particular statistical approach–”succeed” and start to dominate journals?
It must be capable of surviving a multi-stage selection procedure:
- Implementation must be sufficiently affordable so that researchers can actually give it a shot
- Once the authors have added it to a manuscript, it must be retained until submission
- The resulting manuscript must enter the peer-review process and survive it (without the implementation of the practice getting dropped on the way)
- The resulting publication needs to attract enough attention post-publication so that readers will feel inspired to implement it themselves, fuelling the eternally turning wheel of
Samsarapublication-oriented science
Which Kind of Science Reform | Elements of Evolutionary Anthropology