import jax
import jax.numpy as jnp
from jax import random
def cg_solver(b, mv_prod_fn, tol=1e-5, max_iter=100):
"""
Conjugate Gradient method for solving Σv = b.
"""
x = jnp.zeros_like(b)
r = b.copy()
p = r.copy()
rs_old = jnp.dot(r, r)
for i in range(max_iter):
Ap = mv_prod_fn(p)
alpha = rs_old / jnp.dot(p, Ap)
x = x + alpha * p
r = r - alpha * Ap
rs_new = jnp.dot(r, r)
if jnp.sqrt(rs_new) < tol:
break
p = r + (rs_new / rs_old) * p
rs_old = rs_new
return xEfficient Langevin sampling Gaussian distributions
An educationally quixotic exercise
2024-10-30 — 2024-11-30
Gaussian
Hilbert space
kernel tricks
Lévy processes
nonparametric
regression
spatial
stochastic processes
time series
Assumed audience:
ML mavens who want a finger exercise in Langevin diffusions

When dealing with high-dimensional Gaussian distributions, sampling can become computationally expensive, especially when the covariance matrix is large. Traditional methods like the Cholesky decomposition become impractical. However, if we can efficiently compute the product of the covariance matrix with arbitrary vectors, we can leverage Langevin dynamics to sample from the distribution without forming the full covariance matrix.
I have been doing this recently in the setting where \(\Sigma\) is outrageously large, but I can nonetheless calculate \(\Sigma \mathbf{v}\) for arbitrary vectors \(\mathbf{v}\). This arises, for example, when I have a kernel which I can evaluate and I need to use it to generate some samples from my random field, especially where the kernel arises as linear product under some feature map which generates a nearly low rank covariance.
Spoiler alert: While this is an interesting exercise, at the end we discover that it would have been easier to do something even simpler, making this whole essay into an impractical educational exercise.
1 Problem Setting
We aim to sample from a multivariate Gaussian distribution:
\[ \mathbf{x} \sim \mathcal{N}(\boldsymbol{\mu}, \Sigma) \]
where:
- \(\boldsymbol{\mu} \in \mathbb{R}^D\) is the known mean vector.
- \(\Sigma \in \mathbb{R}^{D \times D}\) is the notional known covariance matrix, which might be too large to actually compute, let alone factorise for sampling in the usual way.
2 Langevin Dynamics for Sampling
Langevin dynamics provide a way to sample from a target distribution by simulating a stochastic differential equation (SDE) whose stationary distribution is the desired distribution. For a Gaussian distribution, the SDE simplifies due to the properties of the normal distribution (i.e. Gaussians all the way down).
The continuous-time Langevin equation is
\[ d\mathbf{x}_t = -\nabla U(\mathbf{x}_t) \, dt + \sqrt{2} \, d\mathbf{W}_t \]
where
- \(U(\mathbf{x})\) is the potential function related to the target distribution \(p(\mathbf{x})\) via \(p(\mathbf{x}) \propto e^{-U(\mathbf{x})}\).
- \(d\mathbf{W}_t\) represents the increment of a Wiener process (standard Brownian motion).
For our Gaussian distribution, the potential function is:
\[ U(\mathbf{x}) = \frac{1}{2} (\mathbf{x} - \boldsymbol{\mu})^\top \Sigma^{-1} (\mathbf{x} - \boldsymbol{\mu}) \]
We discretize the Langevin equation using the Euler-Maruyama method with time step \(\epsilon\)
\[ \mathbf{x}_{k+1} = \mathbf{x}_k - \epsilon \nabla U(\mathbf{x}_k) + \sqrt{2\epsilon} \, \boldsymbol{\eta}_k \]
where \(\boldsymbol{\eta}_k \sim \mathcal{N}(\mathbf{0}, \mathbf{I}_D)\). This is not a great approximation, but pretty useful pedagogically, so let us live with it for now before introducing complications. Next, the gradient of the potential function is
\[ \nabla U(\mathbf{x}) = \Sigma^{-1} (\mathbf{x} - \boldsymbol{\mu}) \]
Instead of computing \(\Sigma^{-1}\) directly, we can solve the linear system \(\Sigma \mathbf{v} = \mathbf{x} - \boldsymbol{\mu}\) for \(\mathbf{v}\), which gives \(\mathbf{v} = \Sigma^{-1} (\mathbf{x} - \boldsymbol{\mu})\).
3 How to solve that linear equation
To solve \(\Sigma \mathbf{v} = \mathbf{r}\) efficiently without forming \(\Sigma\), we use the Conjugate Gradient (CG) method. The CG method is suitable for large, sparse, and positive-definite matrices and relies only on matrix-vector products \(\Sigma \mathbf{v}\).
Given \(\Sigma \mathbf{v} = \mathbf{r}\):
- Initialize \(\mathbf{v}_0 = \mathbf{0}\), \(\mathbf{r}_0 = \mathbf{r} - \Sigma \mathbf{v}_0\), \(\mathbf{p}_0 = \mathbf{r}_0\).
- For \(k = 0, 1, \ldots\):
- \(\alpha_k = \frac{\mathbf{r}_k^\top \mathbf{r}_k}{\mathbf{p}_k^\top \Sigma \mathbf{p}_k}\)
- \(\mathbf{v}_{k+1} = \mathbf{v}_k + \alpha_k \mathbf{p}_k\)
- \(\mathbf{r}_{k+1} = \mathbf{r}_k - \alpha_k \Sigma \mathbf{p}_k\)
- If \(\|\mathbf{r}_{k+1}\| < \text{tolerance}\), stop.
- \(\beta_k = \frac{\mathbf{r}_{k+1}^\top \mathbf{r}_{k+1}}{\mathbf{r}_k^\top \mathbf{r}_k}\)
- \(\mathbf{p}_{k+1} = \mathbf{r}_{k+1} + \beta_k \mathbf{p}_k\)
The CG method converges in at most \(D\) iterations for a \(D \times D\) matrix \(\Sigma\), and needs in fact usually a number of iterations proportional to the condition number of \(\Sigma\) (which we can find exactly if the covariance is nearly low rank). I don’t bother with that here.
4 Plug the bits together
We have the following algorithm:
- Start with \(\mathbf{x}_0 = \boldsymbol{\mu}\) or any arbitrary vector.
- For \(k = 0, 1, \ldots, N\):
- Compute \(\mathbf{r}_k = \mathbf{x}_k - \boldsymbol{\mu}\).
- Solve \(\Sigma \mathbf{v}_k = \mathbf{r}_k\) using CG to get \(\mathbf{v}_k = \Sigma^{-1} (\mathbf{x}_k - \boldsymbol{\mu})\).
- Update \(\mathbf{x}_{k+1} = \mathbf{x}_k - \epsilon \mathbf{v}_k + \sqrt{2\epsilon} \, \boldsymbol{\eta}_k\) where \(\boldsymbol{\eta}_k \sim \mathcal{N}(\mathbf{0}, \mathbf{I}_D)\).
5 Python Implementation
Here is an implementation in python that I got an LLM to construct for me from the above algorithm.
5.1 Conjugate Gradient Solver
A teensy CG solver, which looks ok:
5.2 Langevin Dynamics Sampler
def sample_mvn_langevin(mu, num_samples=1000, epsilon=1e-2, burn_in=1000):
"""
Samples from N(mu, Σ) using Langevin dynamics.
Parameters:
- mu: Mean vector (JAX array of shape [D])
- num_samples: Number of samples to collect after burn-in
- epsilon: Time step size
- burn_in: Number of initial iterations to discard
TODO: set num_iter based on condition number of Σ
"""
D = mu.shape[0]
key = random.PRNGKey(0)
# Random initialization
key, subkey = random.split(key)
x = mu + random.normal(subkey, shape=(D,)) * 0.1 # Small perturbation around mu
samples = []
total_steps = num_samples + burn_in
for n in range(total_steps):
# Generate starting v
key, subkey = random.split(key)
noise = random.normal(subkey, shape=(D,))
# Compute gradient: v = Σ^{-1} (x - μ)
r = x - mu
v = cg_solver(r, mv_prod_fn, tol=1e-5, max_iter=100)
# Langevin update
x_new = x - epsilon * v + jnp.sqrt(2 * epsilon) * noise
x = x_new
if n >= burn_in:
samples.append(x.copy())
return jnp.stack(samples) if samples else None5.3 Example
First, we need a function to compute \(\Sigma \mathbf{v}\) efficiently. An obvious case where this is possible is when we have a low-ish rank covariance, which means that matrix products are cheap.
NoteHomework problem
In the low-rank setting, would we actually need a Langevin sampler? or is there something better?
# Basic noisy sinewave
D = 100
mu = jnp.cos(jnp.linspace(0, 2 * jnp.pi, D)) * 5
rank = 10
sig2 = 0.1
def get_matrix_A(D, rank, scale=1.0, mean=None):
"""
Example: generate a random low-rank matrix.
Replace this with the kernel or actual structure of Σ.
"""
key = random.PRNGKey(42)
A = random.normal(key, shape=(D, rank)) * scale
if mean is not None:
A += mean.reshape(-1,1)
return A
A = get_matrix_A(D, rank, mean=mu, scale=2.0)
L = A - A.mean(1).reshape(-1,1)
# centre and normalize A to generate the empirical covariance
L = L / jnp.sqrt(rank)
def mv_prod_fn(v):
"""
Efficient computation of Σv using a known kernel or factorization.
For demonstration, we assume Σ = L L^T + U where L is a low-rank matrix and U=𝞼^2 I is diagonal
"""
return L @ (L.T @ v) + sig2 * vNow we sample from the Gaussian distribution using Langevin dynamics.
6 Validation
After sampling, it’s wise to verify that the samples approximate the target distribution. We can do some basic diagnostics of that by seeing how well we’ve matched the marginal distributions.
import matplotlib.pyplot as plt
import numpy as np
from livingthing.matplotlib_style import set_livingthing_style, reset_default_style
set_livingthing_style()
def plot_validation(
samples,
mu,
sigma_diag,
reference_samples=None,
max_traces=rank,
base_alpha=0.5,
title="",
):
"""
Plot validation for the sampler against the ideal mean and variance,
and optionally include reference samples.
Parameters:
- samples: Samples generated from the sampler (numpy array of shape [num_samples, D]).
- mu: Ideal mean vector (numpy array of shape [D]).
- sigma_diag: Ideal diagonal of the covariance matrix (numpy array of shape [D]).
- reference_samples: Reference samples to plot (numpy array of shape [num_ref_samples, D]).
- max_traces: Maximum number of samples to plot (int).
- base_alpha: Base transparency value (float, for a small number ofs).
"""
D = mu.shape[0]
num_samples = samples.shape[0]
# Randomly select a subset of samples (up to max_traces)
subset_size = min(max_traces, num_samples)
rng = np.random.default_rng()
subset_indices = rng.choice(num_samples, subset_size, replace=False)
sample_subset = samples[subset_indices]
# Adjust alpha to decrease with the square root of the number ofs
trace_alpha = base_alpha / np.sqrt(subset_size)
# Generate x-axis for dimensions
x = np.arange(D)
# Plot the ideal mean and standard deviation bands
# plt.figure(figsize=(12, 7))
plt.plot(x, mu, label="Ideal Mean", color="gray", linestyle="--")
plt.fill_between(
x,
mu - 2 * sigma_diag,
mu + 2 * sigma_diag,
color="gray",
alpha=0.2,
label="Ideal ±2 Std. Dev.",
)
# Plot individual samples with adjusted transparency
for sample in sample_subset:
plt.plot(x, sample, color="red", alpha=trace_alpha)
# If reference samples are provided, plot them
if reference_samples is not None:
ref_subset_size = min(max_traces, reference_samples.shape[0])
ref_subset_indices = rng.choice(
reference_samples.shape[0], ref_subset_size, replace=False
)
ref_sample_subset = reference_samples[ref_subset_indices]
for ref_sample in ref_sample_subset:
plt.plot(x, ref_sample, color="green", alpha=trace_alpha, linestyle="-")
# Create proxy artists for the legend
from matplotlib.lines import Line2D
sample_proxy = Line2D([0], [0], color="red", alpha=1.0, label="Samples")
ref_proxy = Line2D(
[0], [0], color="green", alpha=1.0, linestyle="-", label="Reference Samples"
)
# Add labels and legend
handles = [
plt.Line2D([], [], color="grey", linestyle="--", label="Ideal Mean"),
plt.Line2D([], [], color="grey", alpha=0.2, label="Ideal ±1 Std. Dev."),
sample_proxy,
]
if reference_samples is not None:
handles.append(ref_proxy)
plt.legend(handles=handles)
plt.title(title)
plt.xlabel("Dimension")
plt.ylabel("Value")
plt.grid(True, linestyle="--", alpha=0.5)
plt.tight_layout()
plt.show()
# Example usage:
# Compute the diagonal standard deviation of the ideal covariance matrix
ideal_std_diag = np.sqrt((L * L).sum(1) + sig2)
# Call the plot function
plot_validation(
samples=np.array(samples),
mu=np.array(mu),
sigma_diag=ideal_std_diag,
reference_samples=A.T,
title="Simple Langevin samples",
)
plt.show()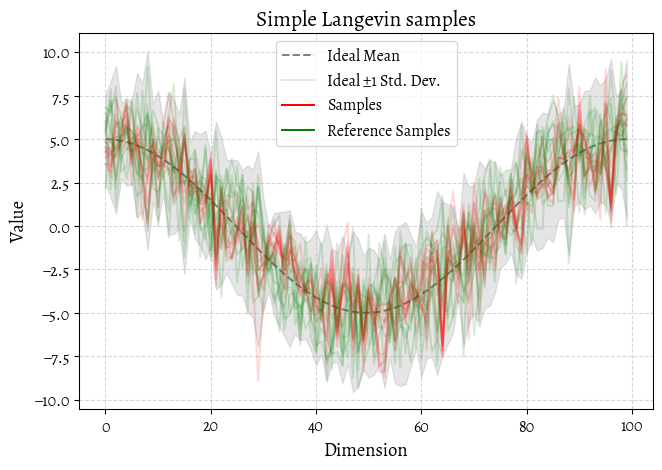
That’s … mediocre. Our sampling is in the right ballpark but not playing the same game as the ideal distribution.
7 Metropolis Adjustment
When using Langevin dynamics for sampling from a probability distribution, discretization errors can lead to sampling from an incorrect distribution. We can fix this in a couple of ways. Since we know that the Gaussian target distribution is actually log-concave, we could use the implicit Langevin trick (Hodgkinson, Salomone, and Roosta 2019).
But let us try a more generic and slightly easier (but not as elegant) trick: a Metropolis-Hastings rejection step, resulting in the Metropolis-Adjusted Langevin Algorithm (MALA). This adjustment ensures that the Markov chain has the desired target distribution as its stationary distribution.
The reason we might need to do this is that when we discretized time using the Euler-Maruyama method, we introduced errors that can accumulate, causing the chain to sample from an incorrect distribution. In MALA, the proposal distribution is based on the discretized Langevin dynamics. The acceptance probability is chosen to ensure detailed balance and correct for the discretization error (thought: are these actually the same thing?).
The proposal \(q(\mathbf{y} \mid \mathbf{x})\) is defined as
\[ q(\mathbf{y} \mid \mathbf{x}) = \mathcal{N}\left( \mathbf{y}; \mathbf{x} - \epsilon \nabla U(\mathbf{x}), \, 2\epsilon \mathbf{I} \right). \]
The acceptance probability \(\alpha(\mathbf{x}, \mathbf{y})\) is given by
\[ \begin{aligned} \alpha(\mathbf{x}, \mathbf{y}) & = \min\left(1, \frac{p(\mathbf{y}) \, q(\mathbf{x} \mid \mathbf{y})}{p(\mathbf{x}) \, q(\mathbf{y} \mid \mathbf{x})} \right)\\ \alpha(\mathbf{x}, \mathbf{y}) &= \min\left(1, \frac{e^{-U(\mathbf{y})} \, \mathcal{N}\left( \mathbf{x}; \mathbf{y} - \epsilon \nabla U(\mathbf{y}), \, 2\epsilon \mathbf{I} \right)}{e^{-U(\mathbf{x})} \, \mathcal{N}\left( \mathbf{y}; \mathbf{x} - \epsilon \nabla U(\mathbf{x}), \, 2\epsilon \mathbf{I} \right)} \right)\\ &= \min\left(1, \exp\left( -U(\mathbf{y}) + U(\mathbf{x}) + \frac{1}{4\epsilon} \left( \|\mathbf{y} - \mathbf{x} + \epsilon \nabla U(\mathbf{x})\|^2 - \|\mathbf{x} - \mathbf{y} + \epsilon \nabla U(\mathbf{y})\|^2 \right) \right) \right) \end{aligned} \]
This ratio adjusts for the asymmetry introduced by the drift term \(-\epsilon \nabla U(\mathbf{x})\) in the proposal distribution.
We might be worried about finding the \(U(\mathbf{y})\) and \(U(\mathbf{x})\) terms. Evaluating \(U(\mathbf{y}) = \frac{1}{2} (\mathbf{y} - \boldsymbol{\mu})^\top \Sigma^{-1} (\mathbf{y} - \boldsymbol{\mu})\) directly could require forming or inverting the covariance matrix \(\Sigma\). However, we got that term for cheap from the CG solver, since we found \(\nabla U(\mathbf{x}) = \Sigma^{-1} (\mathbf{x} - \boldsymbol{\mu})=\Sigma^{-1}(\mathbf{y} - \boldsymbol{\mu})\) already; so this is simply a dot product now, \(U(\mathbf{y}) = \frac{1}{2} (\mathbf{y} - \boldsymbol{\mu})^\top \Sigma^{-1} (\mathbf{y} - \boldsymbol{\mu}) = \frac{1}{2} (\mathbf{y} - \boldsymbol{\mu}) \cdot \nabla U(\mathbf{x}).\)
Code
import jax
import jax.numpy as jnp
from jax import random
def log_q(x_new, x_old, grad_old, epsilon):
"""
Compute the log of the proposal density q(y | x).
Parameters:
- x_new: Proposed state (JAX array).
- x_old: Current state (JAX array).
- grad_old: Gradient of U at x_old (JAX array).
- epsilon: Time step size (float).
Returns:
- log_q: Log of the proposal density (float).
"""
diff = x_new - x_old + epsilon * grad_old
return -0.25 / epsilon * jnp.dot(diff, diff)
def metropolis_adjustment(x, y, U_x, U_y, grad_x, grad_y, epsilon, key):
"""
Perform Metropolis-Hastings acceptance step.
Parameters:
- x: Current state (JAX array).
- y: Proposed state (JAX array).
- U_x: Potential at current state (float).
- U_y: Potential at proposed state (float).
- grad_x: Gradient of U at x (JAX array).
- grad_y: Gradient of U at y (JAX array).
- epsilon: Time step size (float).
- key: JAX PRNGKey.
Returns:
- x_new: Accepted or retained state (JAX array).
"""
log_q_y_given_x = log_q(y, x, grad_x, epsilon)
log_q_x_given_y = log_q(x, y, grad_y, epsilon)
log_alpha = -U_y + U_x + log_q_x_given_y - log_q_y_given_x
log_alpha = jnp.minimum(log_alpha, 0.0) # Ensure log_alpha <= 0
u = random.uniform(key) # u ~ Uniform(0, 1)
accept = u < jnp.exp(log_alpha)
if accept:
return y
else:
return x
def mala_step(x, mu, L, sig2, epsilon, key):
"""
Perform one step of the Metropolis-Adjusted Langevin Algorithm (MALA).
Parameters:
- x: Current state (JAX array).
- mu: Mean vector (JAX array).
- L: Low-rank matrix defining Σ = L L^T + sig2 * I.
- sig2: Variance term in Σ.
- epsilon: Time step size (float).
- key: JAX PRNGKey.
Returns:
- x_new: New state (JAX array).
- key: Updated PRNGKey.
"""
# Split key
key, subkey1, subkey2 = random.split(key, num=3)
# Compute gradient and potential at x
r_x = x - mu
grad_x = cg_solver(r_x, mv_prod_fn, tol=1e-5, max_iter=100)
U_x = 0.5 * jnp.dot(r_x, grad_x)
# Propose new state y
noise = random.normal(subkey1, shape=x.shape)
y = x - epsilon * grad_x + jnp.sqrt(2 * epsilon) * noise
# Compute gradient and potential at y
r_y = y - mu
grad_y = cg_solver(r_y, mv_prod_fn, tol=1e-5, max_iter=100)
U_y = 0.5 * jnp.dot(r_y, grad_y)
# Perform Metropolis adjustment
x_new = metropolis_adjustment(x, y, U_x, U_y, grad_x, grad_y, epsilon, subkey2)
return x_new, key
def sample_mvn_mala(mu, L, sig2, num_samples=1000, epsilon=1e-3, burn_in=100):
"""
Samples from N(mu, Σ) using the Metropolis-Adjusted Langevin Algorithm (MALA).
Parameters:
- mu: Mean vector (JAX array of shape [D]).
- L: Low-rank matrix defining Σ = L L^T + sig2 * I.
- sig2: Variance term in Σ.
- num_samples: Number of samples to collect after burn-in.
- epsilon: Time step size.
- burn_in: Number of initial iterations to discard.
Returns:
- samples: Samples from the target distribution (JAX array of shape [num_samples, D]).
"""
D = mu.shape[0]
key = random.PRNGKey(0)
# Random initialization
key, subkey = random.split(key)
# Small perturbation around mu
x = mu + random.normal(subkey, shape=(D,)) * 0.1
samples = []
total_steps = burn_in + num_samples
for n in range(total_steps):
x, key = mala_step(x, mu, L, sig2, epsilon, key)
# Collect samples after burn-in
if n >= burn_in:
samples.append(x)
return jnp.stack(samples)OK, now let us generate some samples using this shiny new MALA sampler.
Code
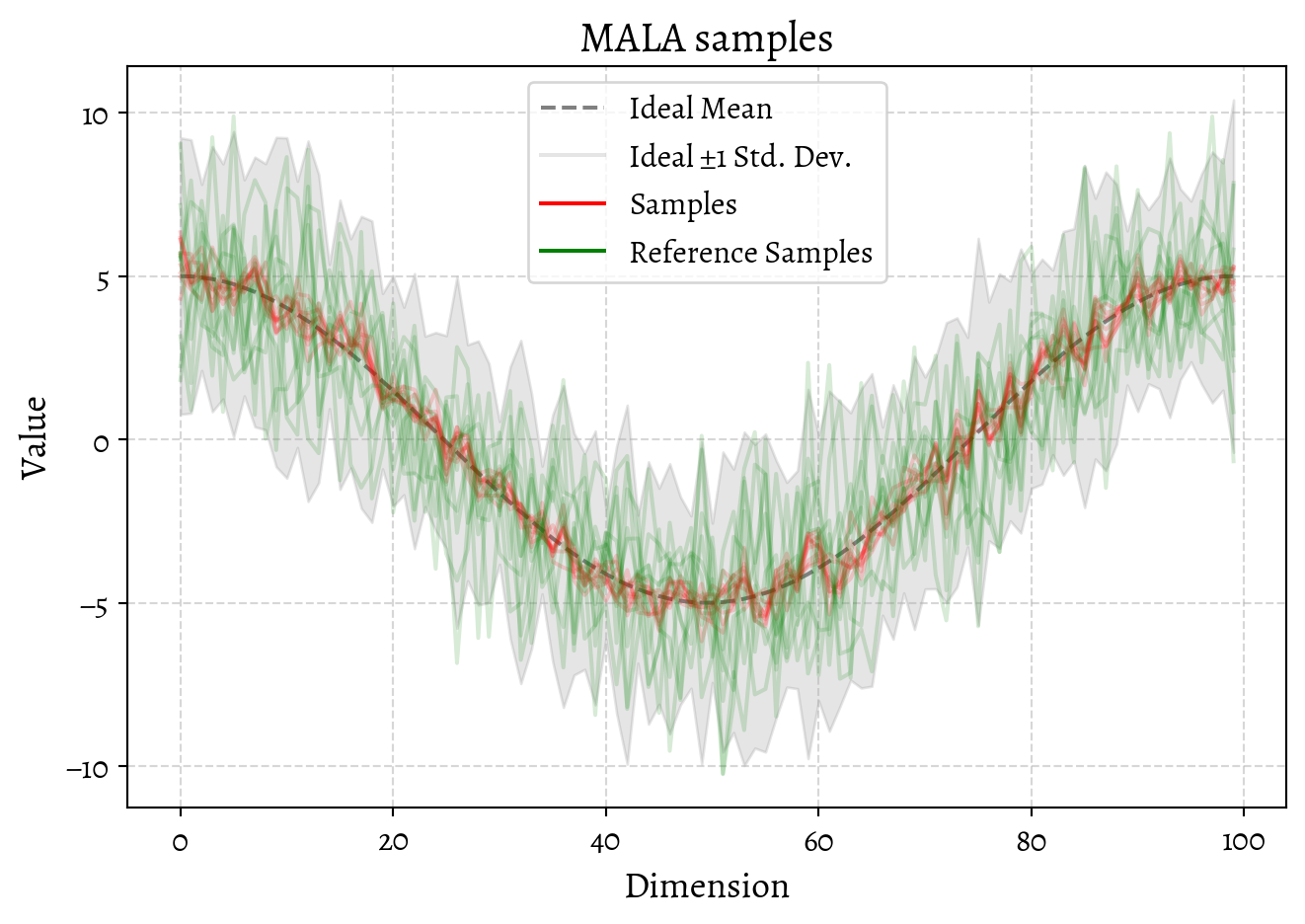
We could investigate the convergence of the MALA sampler by looking at the trace of the samples and think about trade-offs of step size and burn-in etc. I’m not inclined to do that, for a reason that I’ll expand next, which is that this is a silly way of sampling from a Gaussian distribution.
We should ask ourselves when is this method is worth trying at all. This can sample powerfully from tricky Gaussians when we can compute \(\Sigma \mathbf{v}\) but not \(\Sigma\). When can we, in fact, do that? The case here, where \(\Sigma = L L^T + \sigma^2 I\) is a good example, but also kind of useless. There is a way simpler way to sample from that distribution, to wit
- Sample \(\mathbf{z} \sim \mathcal{N}(0, I)\), \(\boldsymbol{\zeta} \sim \mathcal{N}(0, I)\).
- \(\mathbf{x} = \mu + L \mathbf{z} + \sigma \boldsymbol{\zeta}\) is a sample from \(\mathcal{N}(\mu, L L^T + \sigma^2 I)\).
To see this, just calculate the mean and variance of \(\mathbf{x}\). Very simple, very clean, no complicated solvers or burn-in or rejection steps.
So this Langevin example per se is useless (but fun, I hope). But the question might be: are there other occasions when we can calculate \(\Sigma \mathbf{v}\) but not \(\Sigma\)? I cannot think of any right now; to be honest I had a vague idea that one would occur to me when I was writing this; but instead I have persuaded myself that there are no such things.
That is not to say Langevin-type dynamics are not useful; but I think we need to be cleverer; probably score diffusions, which have a very sophisticated way of sampling from punishing (and not even Gaussian) distributions are the interesting case.
8 References
Filippone, and Engler. 2015. “Enabling Scalable Stochastic Gradient-Based Inference for Gaussian Processes by Employing the Unbiased LInear System SolvEr (ULISSE).” In Proceedings of the 32nd International Conference on Machine Learning.
Hodgkinson, Salomone, and Roosta. 2019. “Implicit Langevin Algorithms for Sampling From Log-Concave Densities.” arXiv:1903.12322 [Cs, Stat].
Murray, and Ghahramani. 2004. “Bayesian Learning in Undirected Graphical Models: Approximate MCMC Algorithms.” In Proceedings of the 20th Conference on Uncertainty in Artificial Intelligence. UAI ’04.
Roberts, and Rosenthal. 1998. “Optimal Scaling of Discrete Approximations to Langevin Diffusions.” Journal of the Royal Statistical Society. Series B (Statistical Methodology).
Roberts, and Tweedie. 1996. “Exponential Convergence of Langevin Distributions and Their Discrete Approximations.” Bernoulli.
Welling, and Teh. 2011. “Bayesian Learning via Stochastic Gradient Langevin Dynamics.” In Proceedings of the 28th International Conference on International Conference on Machine Learning. ICML’11.