Model fairness
2018-11-29 — 2022-04-21
Wherein Causal Accounts of Discrimination, Fairness‑accuracy Trade‑offs, and Feedback Effects in Lending and Criminality Prediction Are Examined, the Concentric Manifolds Claimed for Face‑based Criminality Are Noted and Post Hoc Interpretation Methods Are Outlined

Which utilitarian ethical criteria does my model satisfy?
Consider the cautionary tale Automated Inference on Criminality using Face Images (Wu and Zhang 2016)
[…] we find some discriminating structural features for predicting criminality, such as lip curvature, eye inner corner distance, and the so-called nose-mouth angle. Above all, the most important discovery of this research is that criminal and non-criminal face images populate two quite distinctive manifolds. The variation among criminal faces is significantly greater than that of the non-criminal faces. The two manifolds consisting of criminal and non-criminal faces appear to be concentric, with the non-criminal manifold lying in the kernel with a smaller span, exhibiting a law of normality for faces of non-criminals. In other words, the faces of the general law-abiding public have a greater degree of resemblance compared with the faces of criminals, or criminals have a higher degree of dissimilarity in facial appearance than normal people.
Which lessons would you be happy with your local law enforcement authority taking home from this?
Maybe the in-progress textbook will have something to say? Solon Barocas, Moritz Hardt, Arvind Narayanan Fairness and machine learning.
Or maybe I want to do a post hoc analysis on whether my model was in fact using fair criteria when it made a decision. Model interpretation might help with that.
1 Think pieces on fairness in models in practice
- How big data is unfair
- Visualisation of ML discrimination by Google staffers (Hardt, Price, and Srebro 2016)
2 Bias in data
- Excavating AI: The Politics of Images in Machine Learning Training Sets, by Kate Crawford and Trevor Paglen
3 Fairness and causal reasoning
Here’s a thing that was so simple and necessary I assumed it had already been done long before it was. (Kilbertus et al. 2017)
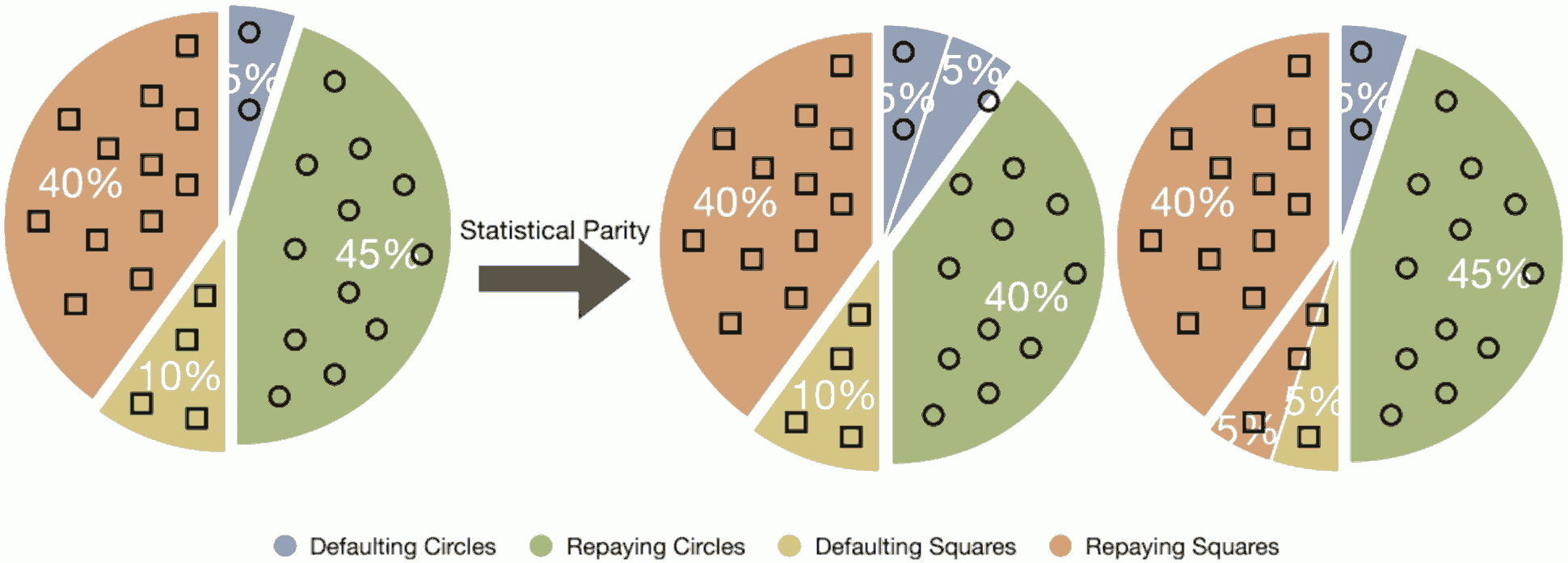
Recent work on fairness in machine learning has focused on various statistical discrimination criteria and how they trade off. Most of these criteria are observational: They depend only on the joint distribution of predictor, protected attribute, features, and outcome. While convenient to work with, observational criteria have severe inherent limitations that prevent them from resolving matters of fairness conclusively.
Going beyond observational criteria, we frame the problem of discrimination based on protected attributes in the language of causal reasoning. This viewpoint shifts attention from “What is the right fairness criterion?” to “What do we want to assume about the causal data generating process?” Through the lens of causality, we make several contributions. First, we crisply articulate why and when observational criteria fail, thus formalising what was before a matter of opinion. Second, our approach exposes previously ignored subtleties and why they are fundamental to the problem. Finally, we put forward natural causal non-discrimination criteria and develop algorithms that satisfy them.
4 Fairness-accuracy trade-offs
There are certain impossibility theorems around what we can do. That is, let us assume we have a perfectly unbiased dataset and an efficient algorithm to exploit it for the best possible accuracy (which is extremely non-trivial to get but let us assume). How accurate can we be if we constrain our model to use only fair solutions (for some value of fairness) even if it reduces the accuracy by being blind to features which are informative about the question? The fairness-accuracy trade-offs quantify the “cost” of fairness in terms of reduced accuracy, so we can quantify various possible degrees of trade-offs. There are lots of very beautiful results in this area (Menon and Williamson 2018; Wang et al. 2021).
In a certain sense, the only fair model is no model at all. Who should our automated model extend a loan to? Everyone! No one! All other decision rules impinge upon the impenetrable thicket of cause and effect and historical after-effects that characterise human moral calculus.
Chris Tucchio, at crunch conf makes some points about marginalist allocative/procedural fairness and net utility versus group rights.
If we choose to service Hyderabad with no disparities, we’ll run out of money and stop serving Hyderabad. The other NBFCs won’t.
Net result: Hyderabad is redlined by competitors and still gets no service.
Our choice: Keep the fraudsters out, utilitarianism over group rights.
He does a good job of explaining some impossibility theorems via examples, esp (Kleinberg, Mullainathan, and Raghavan 2016). Note the interesting intersection of two types of classifications implicit in his model — uniformly reject, versus biased accept/reject, subject to capital constraints. I need to revisit that and think some more.
Han Zhao is an actual researcher in this area. Inherent Tradeoffs in Learning Fair Representations, including two of their own results Zhao et al. (2019);Zhao and Gordon (2019).
In practice, argues (Hutter 2019), the beauty of these theorems can hide the messiness of reality, where the definition of fairness and even the accuracy objective are both underspecified. This leaves the door open to the parameters of our fairness constraint and our model objective jointly to set the arbitrary parameters such that they can reduce discrepancy.
5 Fairness criteria
And in fact, what even is fairness? Turns out that there are lots of difficulties with codifying it.
- When and how do fairness-accuracy trade-offs occur?
- Ziyuan Zhong, A Tutorial on Fairness in Machine Learning
Hedden (2021) has recently argued that many recent attempts are incoherent. Loi et al. (2021) attempt to salvage fairness by distinguishing group and individual fairness.
6 Beauty contest problems and mythic fairness
🚧TODO🚧 think about fairness problems that arise when the model is supposed to be rewarded on the basis of being a good bet for the future, which is to say, when it is choosing people for participation in a self-fulfilling prophecy. Models that are supposed to predict credit risk have a feedback/reinforcing dimension — people in a poverty trap are bad credit risks, even if they got into the poverty trap because of lack of credit, and despite the fact that if they were not in a poverty trap they might not be bad credit risks. Of course, also people who have a raging meth addiction and will spend all the loans on drugs are in the trap. A beauty contest problem is a model for this kind of situation, although there is a time-dimension also. There is presumably a game-theory equilibrium problem. One imagines the Chinese restaurant process or something like it popping up, perhaps even the classic Pareto distribution or other Matthew Effect models.
7 Matthew effects
Related but I think distinct from beauty-contest problems. Algorithmic decisions as part of a larger feedback loop. Venkatasubramanian et al. (2021)’s abstract:
As ML systems have become more broadly adopted in high-stakes settings, our scrutiny of them should reflect their greater impact on real lives. The field of fairness in data mining and machine learning has blossomed in the last decade, but most of the attention has been directed at tabular and image data. In this tutorial, we will discuss recent advances in network fairness. Specifically, we focus on problems where one’s position in a network holds predictive value (e.g., in a classification or regression setting) and favorable network position can lead to a cascading loop of positive outcomes, leading to increased inequality. We start by reviewing important sociological notions such as social capital, information access, and influence, as well as the now-standard definitions of fairness in ML settings. We will discuss the formalizations of these concepts in the network fairness setting, presenting recent work in the field, and future directions.
8 Compliance
- Parity.ai looks interesting for showing processes have certain types of fairness.