Wherein Stochastic Processes on Discrete Measures Are Presented, and a Construction Is Given Whereby Stationary Beta Marginals Are Obtained From Thinned Autoregressive Gamma Components to Model Allele Frequencies.
Stochastic processes indexed by time whose state is a discrete (possibly only countable) measure. Or, to be starker: evolving categorical distributions. Popular in, for example, mathematical models of alleles in biological evolution.
Population genetics keywords, in approximate order of generality and chronology: Fisher-Wright diffusion, Moran process, Viot-Fleming process. Obviously, there are many other processes matching this broad description.
In the simplest case, imagine that we wish to construct a process that is a distribution over \(\{0,1\},\) e.g. for some process \(\{P_t\}_t, P_t\in[0,1] \forall t\) we could imagine that this provides a probability for Bernoulli observation likelihood. We have a lot of candidates for \(P_t\). Here are some examples:
Take two Gamma processes, \(G_t^1, G_t^2\), we could take \(P_t:=\frac{G_t^1}{G_t^1+ G_t^2}\). This would be a marginally Beta distribution.
Take any process \(\{B_t\}_t\) which has instantaneous values \(B_t\in\mathbb{R},\) e.g. a Wiener process or Ornstein-Uhlenbeck process. Now \(\sigma(B_t)\) is the desired process, for \(\sigma:\mathbb{R}\to[0,1].\)
Both these could be generalised in various ways to be Dirichlet distributions of a desired dimensionality.
Option (1) is the most interesting to me for various reasons. We can come back to (2) later with Shakir Mohammed’s classic post on Tricks with Sticks.
Let us look at a basic case, cribbing shamelessly from the Gamma processes notebook:
Code
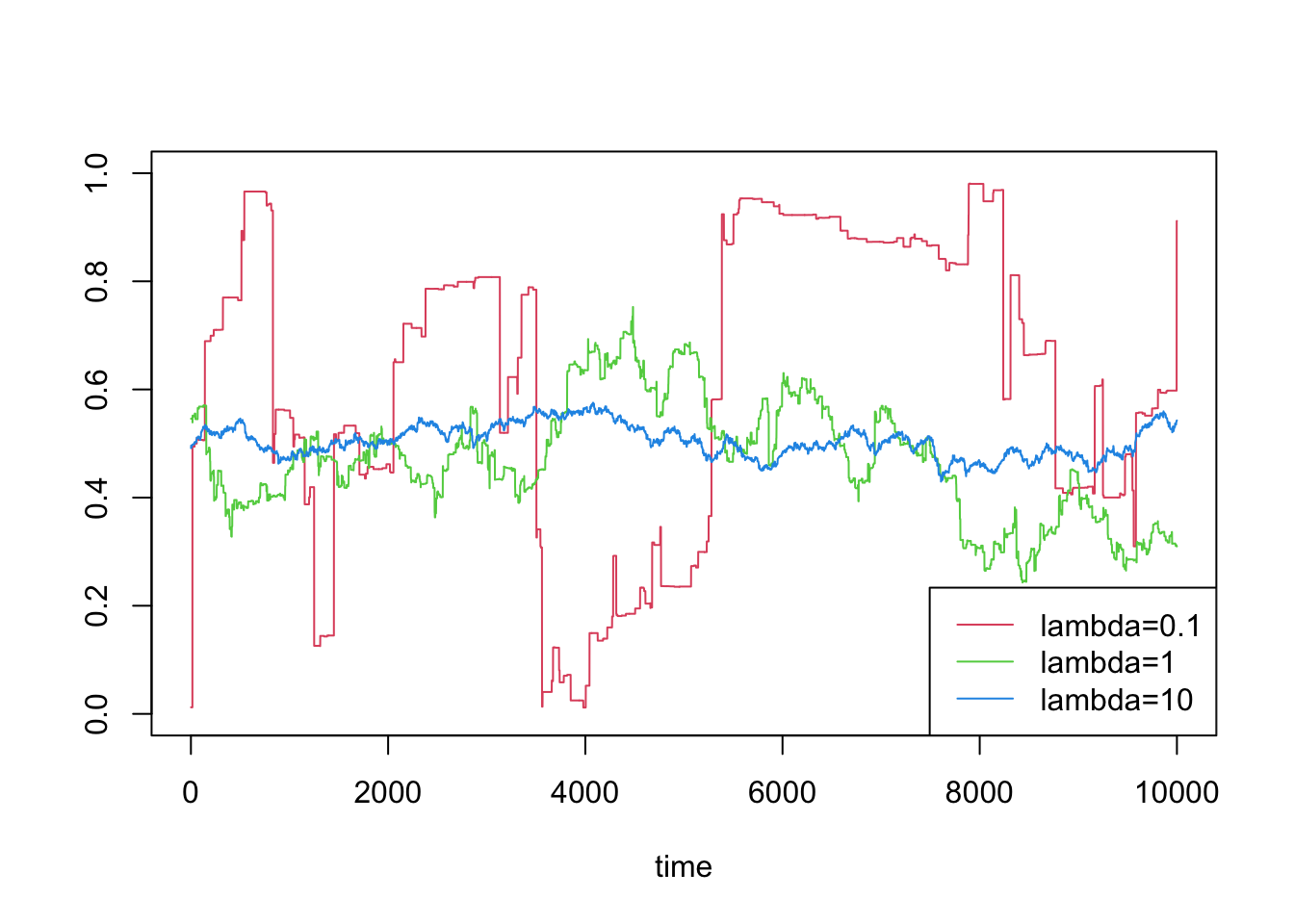
set.seed(165)# generate a stationary thinned autoregressive Gamma seriesgamp =function(T, alpha, lambda, rho) { g =rgamma(1, alpha, rate=lambda) b =rbeta(T, alpha*rho, alpha*(1-rho)) zeta =rgamma(T, alpha*(1-rho), rate=lambda) gs =numeric(T)for (i in1:T) { g = b[i] * g + zeta[i] gs[i] = g } gs}betap =function(T, alpha, lambda, rho) { g1 =gamp(T, head(alpha,1), head(lambda,1), head(rho,1)) g2 =gamp(T, tail(alpha,1), tail(lambda,1), tail(rho,1)) g1 / (g1+g2)}T =10000ts =1:Tplot(ts, betap(T, 1.0, 0.1, 0.999),type ="l", col =2,ylim =c(0, 1), ylab="", xlab ="time")lines(ts, betap(T, 10, 1.0, 0.999),type ="l", col =3)lines(ts, betap(T, 100, 10.0, 0.999),type ="l", col =4)legend("bottomright", c("lambda=0.1", "lambda=1", "lambda=10"),lty =1, col =2:4)
Some stationary Beta processes
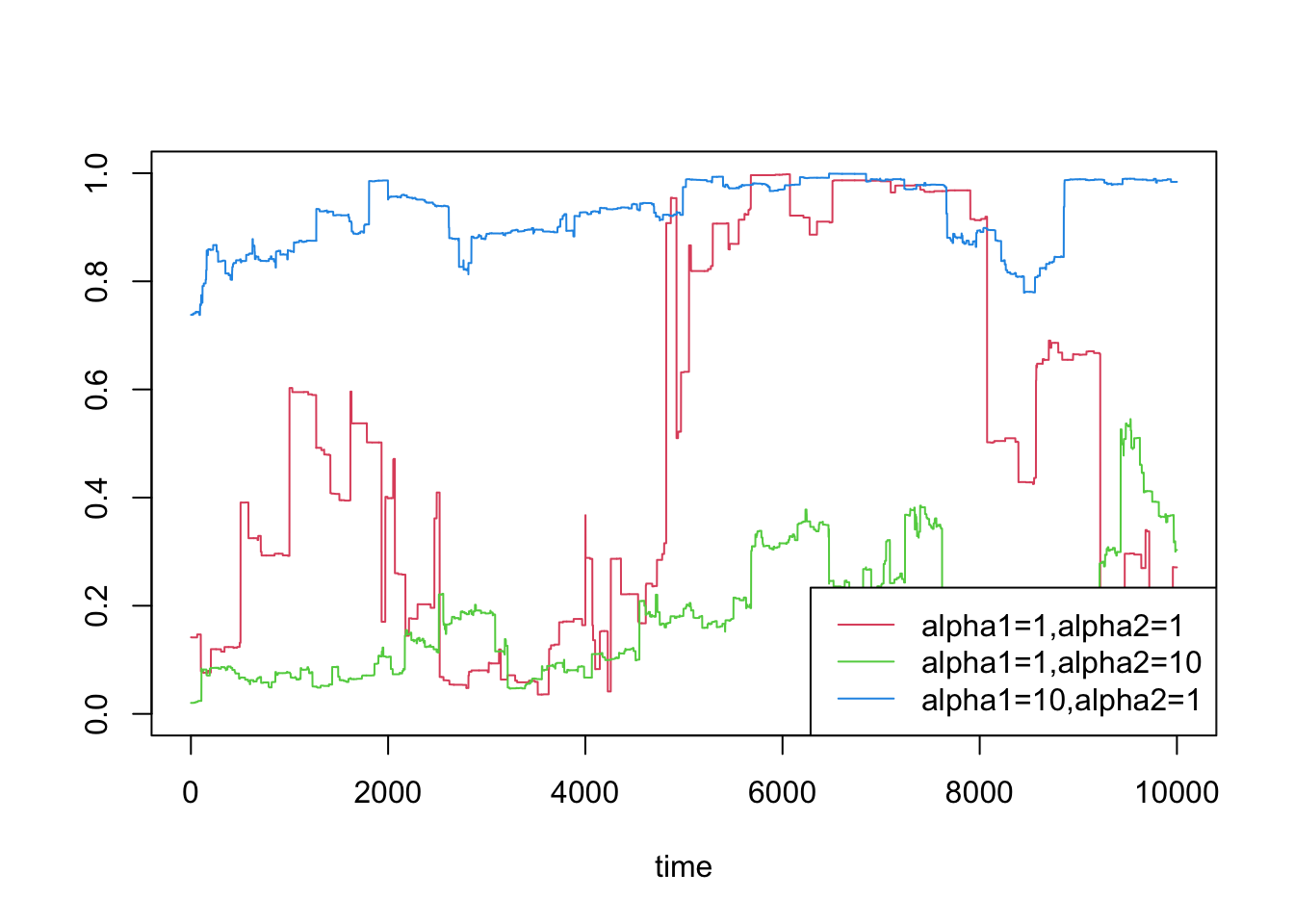
Note that we are not actually required to keep the parameters the same for both latent Gamma processes; we can have different \(\alpha\) and introduce a bias away from \(\mathbb{E}P_t=0.5\):
Code
set.seed(166)plot(ts, betap(T, c(1, 1), 1.0, 0.999),type ="l", col =2,ylim =c(0, 1), ylab="", xlab ="time")lines(ts, betap(T, c(1, 10), 1.0, 0.999),type ="l", col =3)lines(ts, betap(T, c(10, 1), 1.0, 0.999),type ="l", col =4)legend("bottomright", c("alpha1=1,alpha2=1", "alpha1=1,alpha2=10", "alpha1=10,alpha2=1"),lty =1, col =2:4)
Some stationary Beta processes with asymmetric latents
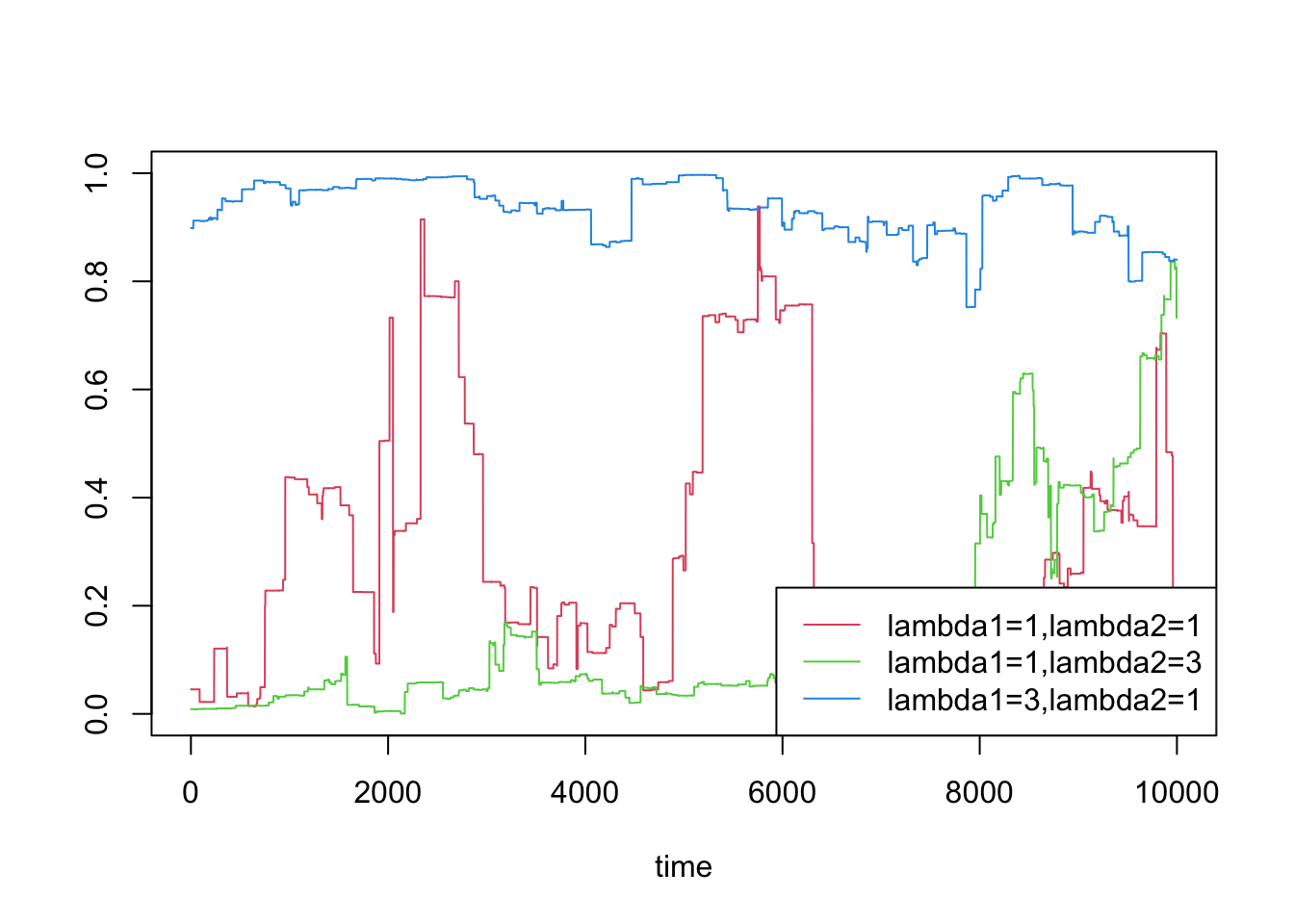
If the \(\lambda\) parameter is not the same between them, then it is no longer marginally Beta, but it is still in the correct \([0,1]\) range to constitute a valid probability. We can get some interesting bias and variance structures this way:
Code
set.seed(167)plot(ts, betap(T, c(1, 1), c(1,1), 0.999),type ="l", col =2,ylim =c(0, 1), ylab="", xlab ="time")lines(ts, betap(T, c(1,3), c(1, 1/3), 0.999),type ="l", col =3)lines(ts, betap(T, c(3, 1), c(1/3, 1), 0.999),type ="l", col =4)legend("bottomright", c("lambda1=1,lambda2=1","lambda1=1,lambda2=3", "lambda1=3,lambda2=1"),lty =1, col =2:4)
Some stationary processes on the unit interval
You get the idea.
It would be nice if we had a formulation for which it were easy to marginalize out the implied latent processes and various other statistical operations of use. Can we get there using Gamma-Dirichlet relations?
One obvious recipe that might work in discrete time is
Given \(P_{t-1}\sim\operatorname{Beta}(\alpha,K-\alpha),\) draw some \(G_t\sim\operatorname{Gamma}(K, \lambda)\). Now \(G_t^1:=P_{t-1}G_t\sim \operatorname{Gamma}(\alpha, \lambda)\) and \(G_t^1:=(1-P_{t-1})G_t\sim \operatorname{Gamma}(K-\alpha, \lambda)\) independently 🚧TODO🚧: check this.
We can perturb either or both of those Gamma variates to another one by thinning and addition, as in thinned autoregressive Gamma processes with some correlation param \(\rho\), giving us \(G_t^1{}',G_t^2{}'\).
Finally, \(P_t=\frac{G_t^1{}'}{G_t^1{}'+G_t^2{}'}\sim\operatorname{Beta}(\alpha,K-\alpha),\) i.e. it has the same distribution.
This circuitous method has the virtue that there are no dependencies on unobserved latent dependent time series, and the process thus depends only on the previous timestep, i.e. it is \(\{P_{t-1}\}\)-measurable, whereas process (1) is \(\{G_{t-1}^1,G_{t-1}^2\}\)-measurable. However, that generation process is weird and lengthy.
Exercise: What is the density of \(P_t|P_{t-1}\) in this formulation?
2 Discrete multivariate state
How do we generalize the discrete model to multivariate observations? Imagine our observations are \(d\)-dimensional lattice-structured. This looks contrived to the statistician, but is bread-and-butter to computer scientists, who deal with binary vectors all the time. In the maximally general case relationships between variables can be… arbitrary of course.
But there are models that assume some structure and I reckon some of those might be useful for inference.
Classics include
Discrete state graphical models which can exploit knowledge of relationships, and which have a well-developed and reliable belief propagation theory.
Spin glasses-type stochastic physics models, which impose an undirected graphical structure on the variates. Classically this is a lattice structure (the Ising model) but many other structures can be found now, including random structures. Spin glasses can be computationally impractical, as with many undirected graphical model problems. Physicists have spent a lot of sweat and blood developing rather complicated vocabulary for these models, which is similar but not quite the same as the vocabulary that statisticians use in inference over such models.
Network models, stochastic block models etc, would probably fit naturally in here.
I would like something that uses spatial adjacency in a non-parametric way and which has convenient inference. Are there models in this class, which make the “right” assumptions to be tractable for use in inference?
2.1 Discrete stick breaking process
We can break up a discrete vector of length \(d\) into regions of equal mass, and then use a stick-breaking process to sample those regions; the stick breaking distribution in this case would naturally be, say, Binomial. We can also imagine Indian Buffet/Chinese restaurant style constructions. In fact, maybe that would be even easier.
Does this get us anywhere? What dependency could we naturally introduce here? One candidate would be to randomly allocate a small number of cells in each partition to random other partitions at each timestep.