Physics-informed neural networks
2019-10-15 — 2023-10-19
Wherein a Solution Is Represented by a Neural Network Over Coordinates, the PDE Residual Is Penalized via Automatic Differentiation, and Latent Stochasticity Is Handled by Polynomial Chaos Expansions.

\(\newcommand{\solop}{\mathcal{G}^{\dagger}}\)
Physics-informed neural networks (PINNs) are a particular way of using statistical or machine learning approaches to solve PDEs, and maybe even to perform inference through them, characterised by using the implicit representation to do the work.
AFAICT this is distinct from imposing the conservation law through the network structure to impose symmetries because here we merely penalize deviations.
This body of literature possibly also encompasses DeepONet approaches 🤷. Distinctions TBD.
🚧TODO🚧: To avoid proliferation of unclear symbols by introducing a specific example; which neural nets represent operators, which represent specific functions, between which spaces etc.
🚧TODO🚧: Harmonise the notation used in this section with subsections below; right now they match the papers’ notation but not each other.
🚧TODO🚧: should the intro section actually be filed under PDEs?
🚧TODO🚧: introduce a consistent notation for coordinate space, output spaces, and function space?
1 Deterministic PINN
Archetypally, the PINN. Recently these have been hip (Raissi, Perdikaris, and Karniadakis 2017a, 2017b; Raissi, Perdikaris, and Karniadakis 2019; L. Yang, Zhang, and Karniadakis 2020; Zhang, Guo, and Karniadakis 2020; Zhang et al. 2019). Zhang et al. (2019) credits Lagaris, Likas, and Fotiadis (1998) with originating the idea in 1998, so I suppose this is not super fresh. Thanks Shams Basir who has an earlier date for this. In Basir and Senocak (2022) credit goes to Dissanayake and Phan-Thien (1994) and van Milligen, Tribaldos, and Jiménez (1995). The key insight is that if we are elbows-deep in a neural network framework anyway, we already have access to automatic differentiation, so differential operations over the input field are basically free.
Let us introduce the basic “forward” PINN setup as given in Raissi, Perdikaris, and Karniadakis (2019): In the basic model we have the following problem \[ f +\mathcal{D}[f;\eta]=0, x \in \Omega, t \in[0, T] \] where \(f(t, x)\) denotes the solution (note this \(\mathcal{D}\) has the opposite sign to the convention we used in the intro). We assume the differential operator \(\mathcal{D}\) is parameterised by some \(\eta\) which for now we take to be known and suppress. Time and space axes are not treated specially in this approach but we keep them separate so that we can more closely approximate the terminology of the original paper. Our goal is to learn a neural network \(f:\mathbb{R}^e\to\mathbb{R}^{d}\in\mathscr{A}\) that approximates the solution to this PDE. We also assume we have some observations from the true PDE solutions, presumably simulated or analytically tractable enough to be given analytically. The latter case is presumably for benchmarking, as it makes this entire approach pointless AFAICS if the analytic version is easy.
We define residual network \(r(t, x)\) to be given by the left-hand side of the above \[ r:=f +\mathcal{D}[f] \] and proceed by approximating \(u(t, x;\theta)\) with a deep neural network \(r(t, x;\theta)\).
The approximation is data-driven, with sample set \(S_{t}\) from a run of the PDE solver, \[ S=\left\{ \left\{ f( {t}_{f}^{(i)}, {x}_{f}^{(i)}) \right\}_{i=1}^{N_{f}}, \left\{ r(t_{r}^{(i)}, (x_{r}^{(i)}) \right\}_{i=1}^{N_{r}} \right\}. \]
\(f(t, x;\theta)\) and \(r(t, x;\theta)\) share parameters \(\theta\) (but differ in output). This seems to be a neural implicit representation-style approach, where we learn functions on coordinates. Each parameter set for the simulator to be approximated is a new dataset, and training examples are pointwise-sampled from the solution.
The key insight is that if we are elbows-deep in a neural network framework anyway, we already have access to automatic differentiation, so differential operations over the input field are basically free.
We train by minimising a combined loss, \[ L(\theta)=\operatorname{MSE}_{f}(\theta)+\operatorname{MSE}_{r}(\theta) \] where \[ \operatorname{MSE}_{f}=\frac{1}{N_{f}} \sum_{i=1}^{N_{f}}\left|f\left(t_{f}^{(i)}, x_{f}^{(i)}\right)-f^{(i)}\right|^{2} \] and \[ \operatorname{MSE}_{r}=\frac{1}{N_{r}} \sum_{i=1}^{N_{r}}\left|r\left(t_{r}^{(i)}, x_{r}^{(i)}\right)\right|^{2} \] Loss \(\operatorname{MSE}_{f}\) corresponds to the initial and boundary data while \(\operatorname{MSE}_{r}\) enforces the structure imposed by the defining differential operator at a finite set of collocation points. This trick allows us to learn an approximate solution operator which nearly enforces the desired conservation law.
An example is illustrative. Here is the reference Tensorflow interpretation from Raissi, Perdikaris, and Karniadakis (2019) for the Burger’s equation. In one space dimension, the Burger’s equation with Dirichlet boundary conditions reads \[ \begin{array}{l} f +f f_{x}-(0.01 / \pi) f_{x x}=0, \quad x \in[-1,1], \quad t \in[0,1] \\ f(0, x)=-\sin (\pi x) \\ f(t,-1)=f(t, 1)=0 \end{array} \] We define \(r(t, x)\) to be given by \[ r:=f +f f_{x}-(0.01 / \pi) f_{x x} \]
The python implementation of these two parts is essentially a naïve transcription of those equations.
Because the outputs are parameterised by coordinates, the built-in autodiff does all the work. The authors summarize the resulting network topology so:
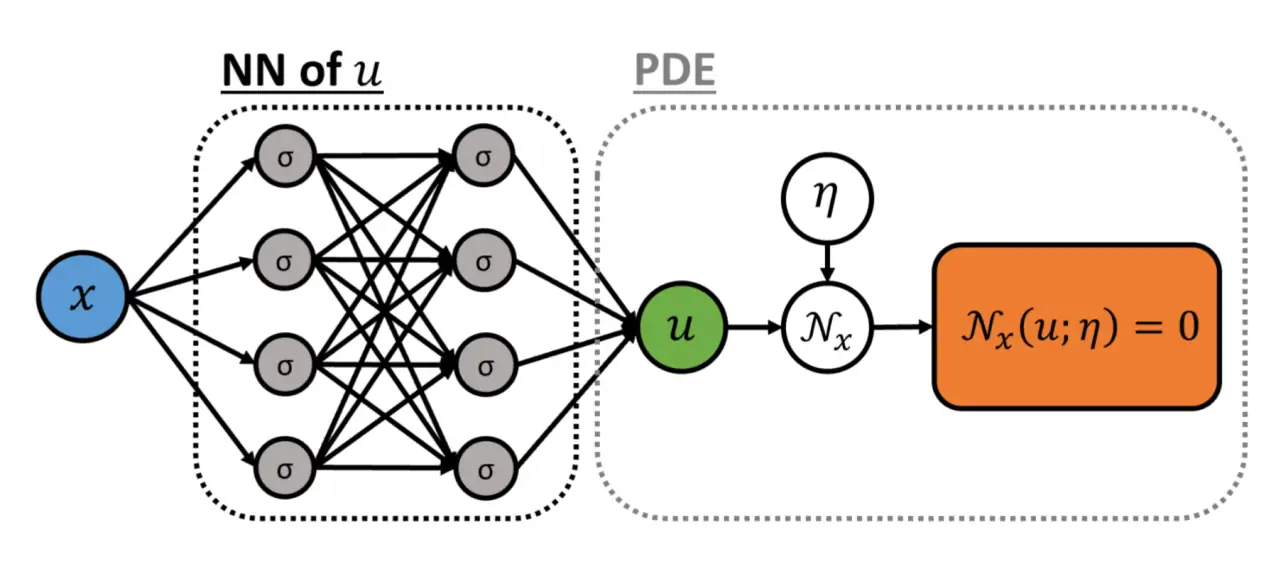
What has this gained us? So far, we have acquired a model which can, the authors assert, solve deterministic PDEs, which is nothing we could not do before. We have sacrificed any guarantee that our method will in fact do well on data from outside our observations. Also, I do not understand how I can plug alternative initial or boundary conditions into this. There is no data input, as such, at inference time, merely coordinates. On the other hand, the authors assert that this is faster and more stable than traditional solvers. It has the nice feature that the solution is continuous in its arguments; there is no grid. As far as NN things go, the behaviour of this model is weird and refreshing: it is simple, requires small data, and has few tuning parameters.
But! what if we don’t know the parameters of the PDE? Assume the differential operator has parameter \(\eta\) which is not in fact known. \[ f +\mathcal{D}[f;\eta]=0, x \in \Omega, t \in[0, T] \] The trick, as far as I can tell, is simply to include \(\eta\) in trainable parameters. \[ r(\eta):=f (\eta)+\mathcal{D}[f;\eta] \] and proceed by approximating \(f(t, x;\theta,\eta)\) with a deep neural network \(r(t, x;\theta,\eta)\). Everything else proceeds as before.
Fine; now what? Two obvious challenges from where I am sitting.
- No way of changing inputs in the sense of initial or boundary conditions, without re-training the model
- Point predictions. No accounting for randomness or uncertainty.
2 Stochastic PINN
Zhang et al. (2019) address point 2 via chaos expansions to handle the PDE emulation as a stochastic process regression, which apparently gives us estimates of parametric and process uncertainty. All diagrams in this section come from that paper.
🚧TODO🚧 Terminology warning: I have not yet harmonised the terminology of this section with the rest of the page.
The extended model adds a random noise parameter \(k(x ; \omega)\): \[ \begin{array}{c} \mathcal{D}_{x}[u(x ; \omega) ; k(x ; \omega)]=0, \quad x \in \mathcal{D}, \quad \omega \in \Omega \\ \text { B.C. } \quad \mathcal{B}_{x}[u(x ; \omega)]=0, \quad x \in \Gamma \end{array} \]
The randomness in this could indicate a random coupling term, or uncertainty in some parameter of the model. Think of a Gaussian process prior over the forcing term of the PDE. We sample this noise parameter also and augment the data set with it, over \(N\) distinct realisations, giving a data set like this:
\[ S=\left\{ \left\{ k( {t}_u^{(i)}, {x}_u^{(i)}; \omega_{s}) \right\}_{i=1}^{N_{u}}, \left\{ u( {t}_u^{(i)}, {x}_u^{(i)}; \omega_{s}) \right\}_{i=1}^{N_{u}}, \left\{ r(t_{r}^{(i)}, (x_{r}^{(i)}) \right\}_{i=1}^{N_{r}} \right\}_{s=1}^{N}. \]
Note that I have kept the time variable explicit, unlike the paper, to match the previous section, but it gets cluttered if we continue to do this, so let’s suppress \(t\) hereafter, and make it just another axis of a multidimensional \(x\).
So now we approximate \(k\). Why? AFAICT that is because we are going to make a polynomial basis for \(\xi\) which means that we want few dimensions.
We let \(K\) be the \(N_{k} \times N_{k}\) covariance matrix for the sensor measurements on \(k,\) i.e., \[ K_{i, j}=\operatorname{Cov}\left(k^{(i)}, k^{(j)}\right) \] We take an eigendecomposition of \(K\). Let \(\lambda_{l}\) and \(\phi_{l}\) denote \(l\)-th largest eigenvalue and its associated normalized eigenvector of Then we have \[ K=\Phi^{T} \Lambda \Phi \] where \(\mathbf{\Phi}=\left[\phi_{1}, \phi_{2}, \ldots, \phi_{N_{k}}\right]\) is an orthonormal matrix and \(\boldsymbol{\Lambda}=\operatorname{diag}\left(\lambda_{1}, \lambda_{2}, \ldots \lambda_{N_{k}}\right)\) is a diagonal matrix. Let \(\boldsymbol{k}_{s}=\left[k_{s}^{(1)}, k_{s}^{(2)}, \ldots, k_{s}^{\left(N_{k}\right)}\right]^{T}\) be the results of the \(k\) measurements of the \(s\)-th snapshot, then \[ \boldsymbol{\xi}_{s}=\boldsymbol{\Phi}^{T} \sqrt{\boldsymbol{\Lambda}}^{-1} \boldsymbol{k}_{s} \] is a whitened, i.e. uncorrelated, random vector, and hence \(\boldsymbol{k}_{s}\) can be rewritten as a reduced dimensional expansion \[ \boldsymbol{k}_{s} \approx \boldsymbol{k}_{0}+\sqrt{\boldsymbol{\Lambda}^{M}} \boldsymbol{\Phi}^{M} \boldsymbol{\xi}_{s}^{M}, \quad M<N_{k} \] where \(\boldsymbol{k}_0=\mathbb{E}\boldsymbol{k}.\) We fix \(M\ll N_k\) and suppress it hereafter.
Now we have approximated away the correlated \(\omega\) noise and in favour of this \(\xi\) which we have finite-dimensional representations of. \[k\left(x_{k}^{(i)} ; \omega_{s}\right) \approx k_{0}\left(x_{k}^{(i)}\right)+\sum_{l=1}^{M} \sqrt{\lambda_{l}} k_{l}\left(x_{k}^{(i)}\right) \xi_{s, l}, \quad M<N_{k}\] Note that this is defined only at the observation points, though.
Next is where we use the chaos expansion trick to construct an interpolant. Suppose the measure of RV \(\xi\) is \(\rho\). We approximate this unknown measure by its empirical measure $ {S}\(.\)$ () {S}()= {{s} S} {{s}}() $$ where \(\delta_{\xi_{s}}\) is the Dirac measure.
We construct a polynomial basis which is orthogonal with respect to the inner product associated to this measure, specifically \[\begin{aligned} \langle \phi, \psi\rangle &:= \int \phi(x)\psi(x)\rho(x)\mathrm{d}x\\ &\approx \int \phi(x)\psi(x)\nu_{S}(x)\mathrm{d}x \end{aligned}\]
OK, so we construct an orthonormal polynomial basis \(\left\{\psi_{\alpha}(\boldsymbol{\xi})\right\}_{\alpha=0}^{P}\) via the Gram-Schmidt orthogonalization process.1 With the polynomial basis \(\left\{\psi_{\alpha}(\boldsymbol{\xi})\right\}\) we can write a function \(g(x ; \boldsymbol{\xi})\) in the form of the aPC expansion, \[ g(x ; \boldsymbol{\xi})=\sum_{\alpha=0}^{P} g_{\alpha}(x) \psi_{\alpha}(\boldsymbol{\xi}) \] where each \(g_{\alpha}(x)\) is calculated by \[ g_{\alpha}(x)=\frac{1}{N} \sum_{s=1}^{N} \psi_{\alpha}\left(\boldsymbol{\xi}_{s}\right) g\left(x ; \boldsymbol{\xi}_{s}\right). \]
So we are going to pick \(g\) to be some quantity of interest in our sim, and in fact, we take it to be two separate quantities, \(u\) and \(k\).
Then, we can approximate \(k\) and \(u\) at the \(s\)-th snapshot by \[ \tilde{k}\left(x ; \omega_{s}\right)=\widehat{k_{0}}(x)+\sum_{i=1}^{M} \sqrt{\lambda_{i}} \widehat{k_{i}}(x) \xi_{s, i} \] and \[ \tilde{u}\left(x ; \omega_{s}\right)=\sum_{\alpha=0}^{P} \widehat{u_{\alpha}}(x) \psi_{\alpha}\left(\boldsymbol{\xi}_{s}\right). \]
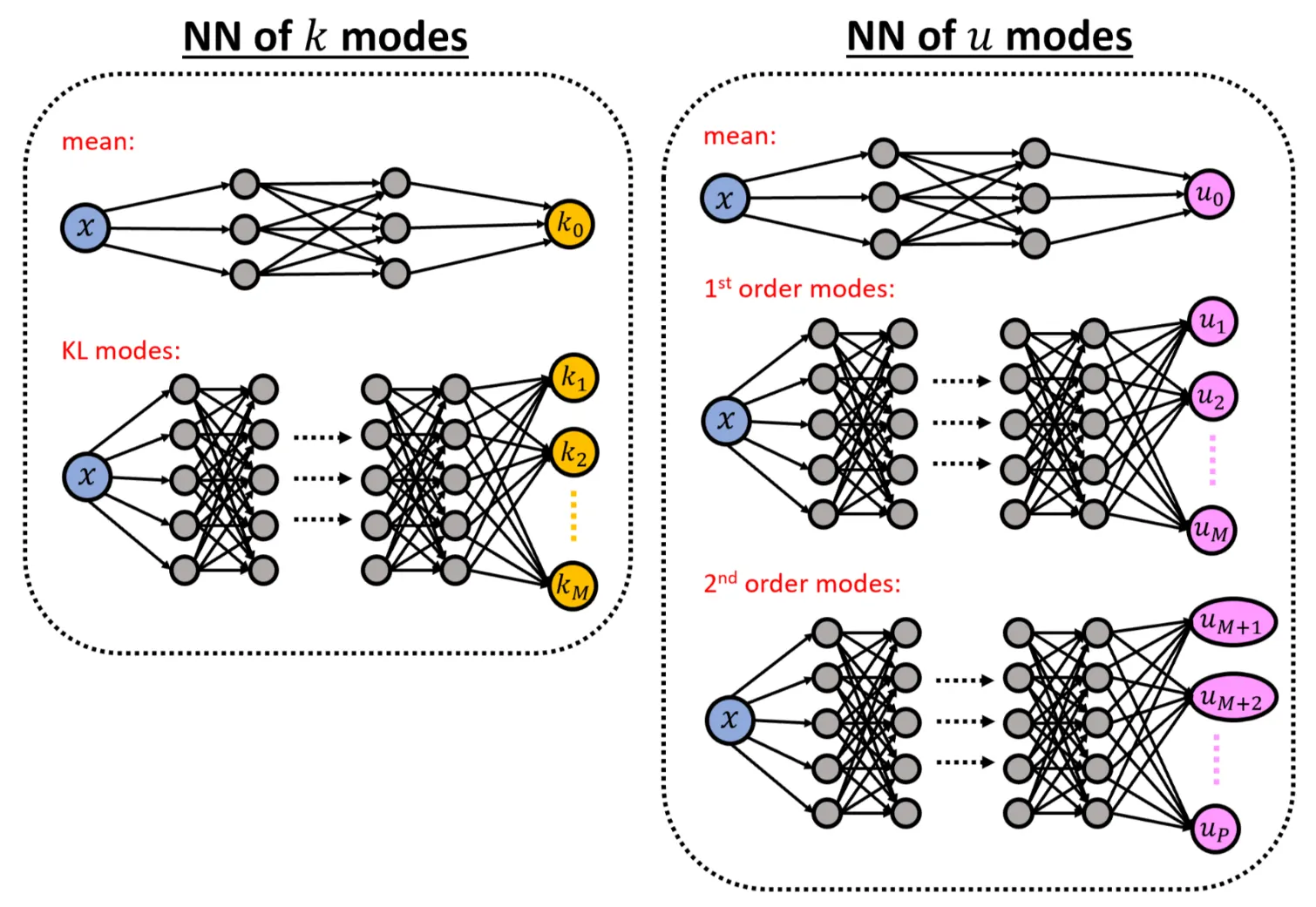
We construct two networks,
- the network \(\widehat{u_{\alpha}}\), which takes the coordinate \(x\) as the input and outputs a \((P+1) \times 1\) vector of the aPC modes of \(u\) evaluated at \(x\), and
- the network \(\widehat{k_{i}}\) that takes the coordinate \(x\) as the input and outputs a \((M+1) \times 1\) vector of the \(k\) modes.
The resulting network topology is
For concreteness, here is the topology for an example problem \(\mathcal{D}:=-\frac{\mathrm{d}}{\mathrm{d} x}\left(k(x ; \omega) \frac{\mathrm{d}}{\mathrm{d} x} u\right)-f\):
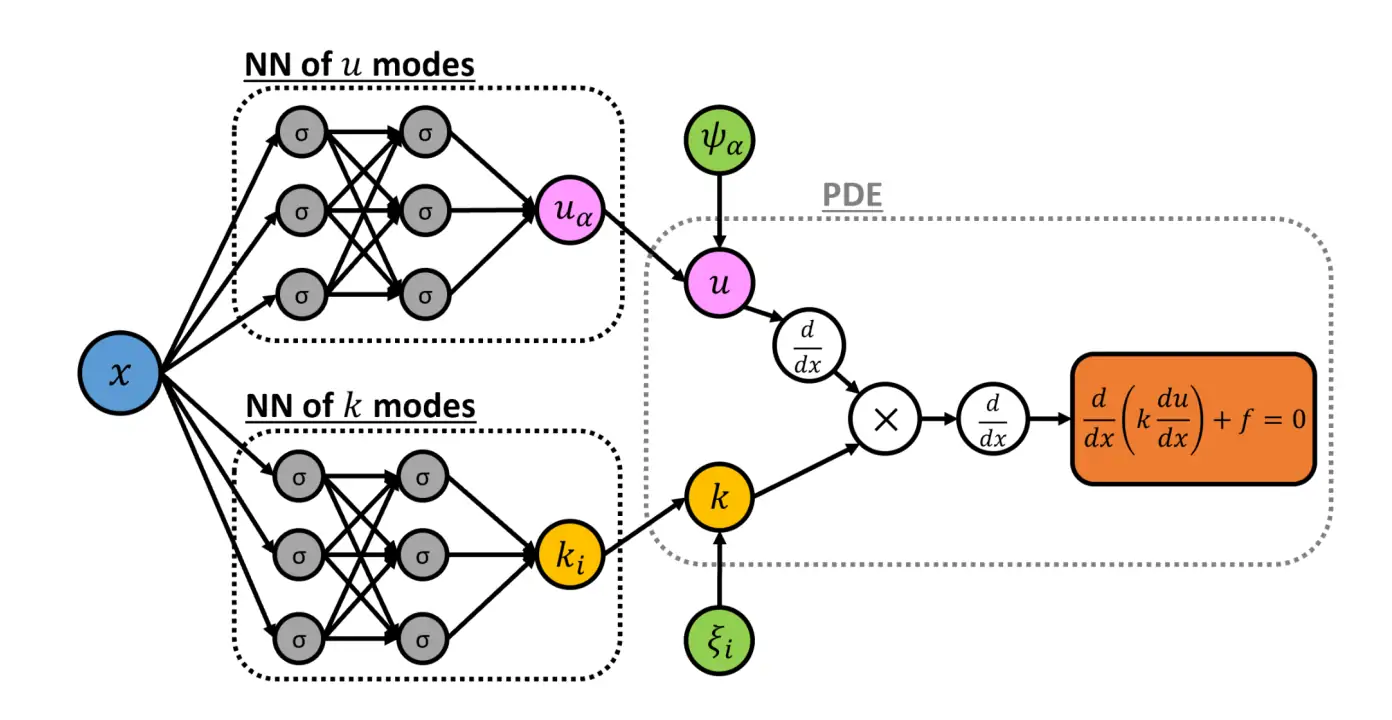
At inference time we take observations of \(k\), calculate the whitened \(\xi\), then use the chaos expansion representation to calculate the values at unobserved locations. \[ \mathcal{L}\left(S_{t}\right)=\operatorname{MSE}_{u}+\operatorname{MSE}_{k}+\operatorname{MSE}_{f} \] where \[ \begin{array}{l} \operatorname{MSE}_{u}=\frac{1}{N N_{u}} \sum_{s=1}^{N} \sum_{i=1}^{N_{u}}\left[\left(\tilde{u}\left(x_{u}^{(i)} ; \omega_{s}\right)-u\left(x_{u}^{(i)} ; \omega_{s}\right)\right)^{2}\right] \\ \operatorname{MSE}_{k}=\frac{1}{N N_{k}} \sum_{s=1}^{N} \sum_{i=1}^{N_{k}}\left[\left(\tilde{k}\left(x_{k}^{(i)} ; \omega_{s}\right)-k\left(x_{k}^{(i)} ; \omega_{s}\right)\right)^{2}\right] \end{array} \] and \[ \operatorname{MSE}_{f}=\frac{1}{N N_{f}} \sum_{s=1}^{N} \sum_{i=1}^{N_{f}}\left[\left(\mathcal{D}_{x}\left[\tilde{u}\left(x_{f}^{(i)} ; \omega_{s}\right) ; \tilde{k}\left(x_{f}^{(i)} ; \omega_{s}\right)\right]\right)^{2}\right] \]
After all that I would describe this as a method to construct a stochastic PDE with the desired covariance structure, which is a hard thing to do. OK, all that was very complicated. Although, it was a complicated thing to do; Consider the mess this gets us into in the Karhunen Loéve expansion and spectral expansion Anyway, after all this, presuming the neural networks are perfect, we have a good estimate of the distribution of random parameters and random output of a stochastic PDE evaluated over the whole surface from partial discrete measurements.
How do we estimate the uncertainty introduced by the neural net? Dropout.
Further questions:
- Loss scale; gradient errors may not be comparable to value errors in the loss function.
- Network capacity: What size networks are necessary (not the ones we learn are tiny, with only hundreds of parameters)
- How do we generalize this to different initial conditions? Can we learn an observation-conditional PDE?
- After all this work it looks like I still can’t do inference on this thing. How do I update a distribution over \(k\) by this method from observations of a new PDE?
- Notice how the parameter inference problem for \(\eta\) vanished for the stochastic PDE? Can we learn an estimate for \(u\), \(\eta\) and \(k\) simultaneously in this setting? I imagine we repeat the trick where that parameter is learned along with the \(u\) network.
3 Weak formulation
🚧TODO🚧: should this be filed with PINNs?
A different network topology using the implicit representation trick is explored in Zang et al. (2020) and extended to inverse problems in Bao et al. (2020), They discuss this in terms of a weak formulation of a PDE.
🚧TODO🚧 Terminology warning: I have not yet harmonised the terminology of this section with the rest of the page.
We start with the example second-order elliptic2 PDE with on domain \(\Omega \subset \mathbb{R}^{d}\) given \[\mathcal{D}[u]-f:=-\sum_{i=1}^{d} \partial_{i}\left(\sum_{j=1}^{d} a_{i j} \partial_{j} u\right)+\sum_{i=1}^{d} b_{i} \partial_{i} u+c u-f=0\] where \(a_{i j}, b_{i}, c: \Omega \rightarrow \mathbb{R}\) for \(i, j \in[d] \triangleq\{1, \ldots, d\}, f: \Omega \rightarrow \mathbb{R}\) and \(g: \partial \Omega \rightarrow \mathbb{R}\) are all given. We start by assuming Dirichlet boundary conditions, \(u(x)-g(x)=0\), although this is rapidly generalised.
By multiplying both sides by a test function \(\varphi \in H_{0}^{1}(\Omega ; \mathbb{R})\) and integrating by parts: \[\left\{\begin{array}{l}\langle\mathcal{D}[u], \varphi\rangle \triangleq \int_{\Omega}\left(\sum_{j=1}^{d} \sum_{i=1}^{d} a_{i j} \partial_{j} u \partial_{i} \varphi+\sum_{i=1}^{d} b_{i} \varphi \partial_{i} u+c u \varphi-f \varphi\right) \mathrm{d} x=0 \\ \mathcal{B}[u]=0, \text { on } \partial \Omega\end{array}\right.\]
The clever insight is that this inspires an adversarial problem to find the weak solutions, by considering the \(L^2\) operator norm of \(\mathcal{D}[u](\varphi) \triangleq\langle\mathcal{D}[u], \varphi\rangle\). Then the operator norm of \(\mathcal{D}[u]\) is defined \[\|\mathcal{D}[u]\|_{o p} \triangleq \max \left\{\langle\mathcal{D}[u], \varphi\rangle /\|\varphi\|_{2} \mid \varphi \in H_{0}^{1}, \varphi \neq 0\right\}.\] Therefore, \(u\) is a weak solution of the PDE if and only if \(\|\mathcal{D}[u]\|_{o p}=0\) and the boundary condition \(\mathscr{B}[u]=0\) is satisfied on \(\delta \Omega\). As \(\|\mathcal{D}[u]\|_{o p} \geq 0\), we know that a weak solution \(u\) thus solves the following two equivalent problems in observation: \[\min _{u \in H^{1}}\|\mathcal{D}[u]\|_{o p}^{2} \Longleftrightarrow \min _{u \in H^{1}} \max _{\varphi \in H_{0}^{1}}|\langle\mathcal{D}[u], \varphi\rangle|^{2} /\|\varphi\|_{2}^{2}.\]
Specifically the solutions \(u_{\theta}: \mathbb{R}^{d} \rightarrow \mathbb{R}\) are realized as a deep neural network with parameter \(\theta\) to be learned, such that \(\mathscr{S}\left[u_{\theta}\right]\) minimizes the (estimated) operator norm. The test function \(\varphi\), is a deep adversarial network with parameter $, which adversarially challenges \(u_{\theta}\) by maximising \(\left\langle\mathcal{D}\left[u_{\theta}\right], \varphi_{\eta}\right\rangle/\left\|\varphi_{\eta}\right\|_{2}\) for every given \(u_{\theta}\).
To train the deep neural network \(u_{\theta}\) and the adversarial network \(\varphi_{\eta}\) we construct appropriate loss functions \(u_{\theta}\) and \(\varphi_{\eta}\). Since the logarithm function is monotone and strictly increasing, we can for convenience formulate the objective of \(u_{\theta}\) and \(\varphi_{\eta}\) in the interior of \(\Omega\) as \[L_{\text {int }}(\theta, \eta) \triangleq \log \left|\left\langle\mathcal{D}\left[u_{\theta}\right], \varphi_{\eta}\right\rangle\right|^{2}-\log \left\|\varphi_{\eta}\right\|_{2}^{2}.\] In addition, the weak solution \(u_{\theta}\) must also satisfy the boundary condition \(\mathscr{B}[u]=0\) on \(\delta \Omega\) which we fill in as above, calling it \(L_{\text {bdry }}(\theta).\) The total adversarial objective function is the weighted sum of the two objectives for which we seek for a saddle point that solves the minimax problem: \[\min _{o} \max L(\theta, \eta), \text{ where } L(\theta, \eta) \triangleq L_{\text {int }}(\theta, \eta)+\alpha L_{\text {bdry }}(\theta).\] \(\alpha\) might seem arbitrary; apparently it is useful as a tuning parameter.
This is a very elegant idea, although the implicit representation thing is still a problem for my use cases.
4 PINO
Combines operator learning with physics-informed neural networks. Li et al. (2021):
Code at neuraloperator/PINO.
5 Implementation
pytorch via TorchPhysics
Tensorflow
6 Incoming
- idrl-lab/PINNpapers: Must-read Papers on Physics-Informed Neural Networks.
- X. Chen et al. (2021) uses an attention mechanism to improve the performance of PINNs. I’m curious.
- Introduction to Scientific Machine Learning 2: Physics-Informed Neural Networks
- Introduction to Scientific Machine Learning through Physics-Informed Neural Networks