Validating and reproducing science
“Scientist, falsify thyself”. Peer review, academic incentives, credentials, evidence and funding
2020-05-16 — 2025-05-22
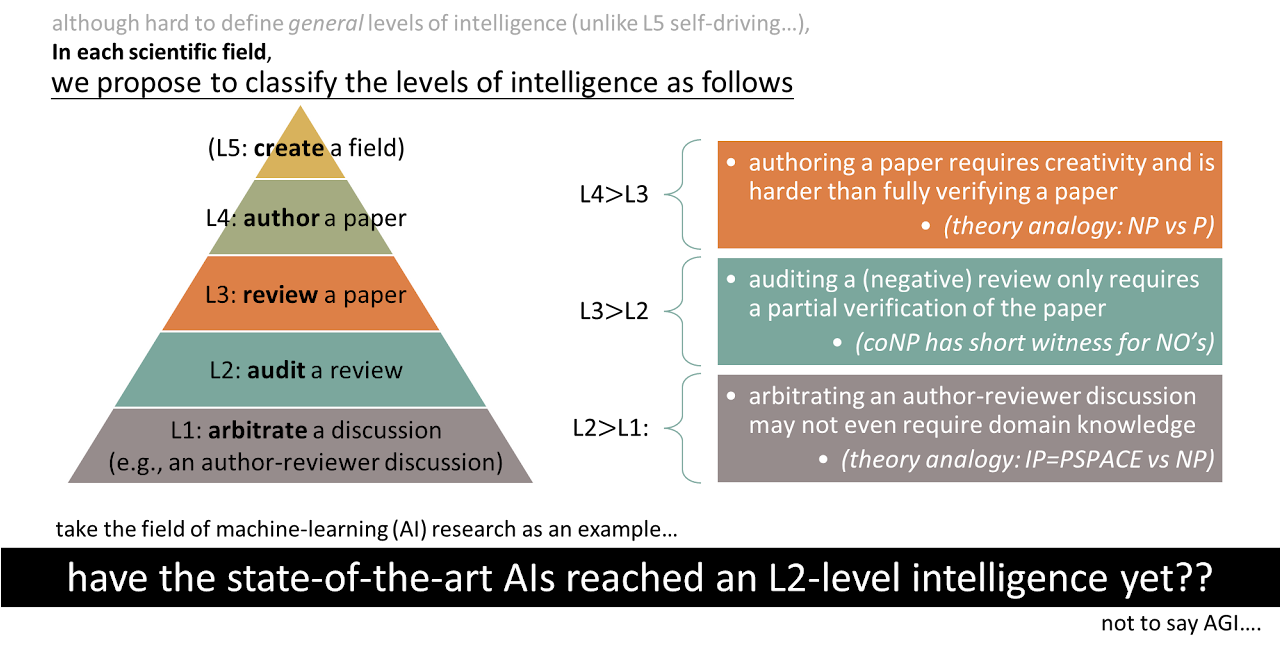
Upon the thing that I presume academic publishing is supposed to do: further science. Reputation systems, collective decision making, groupthink management and other mechanisms for trustworthy science, a.k.a. our collective knowledge of reality itself.
I want to consider the system of peer review, networking, conferencing, publishing and acclaim and see how closely it matches an ideal system for uncovering truth. Further, I imagine how we could make a better system. But I won’t do that right now; I’ll just collect some provocative links to that theme, hoping for time for more thought later.

1 Some open review processes
pubpeer (who are behind peeriodicals) produces a peer-review overlay for web browsers to spread their commentary and peer critique more widely. The site concept is itself brusquely confusing, but well blogged; you’ll get the idea. They are not afraid of invective, and I thought they looked more amateurish than effective. But I have revised that opinion; they are quite selective and effective. This system has been implicated in topical high-profile retractions (e.g. 1 2).
There are many others that have less institutional backing; e.g. Uri Simonsohn.

- Related question: How do we discover research to peer review?
2 Mathematical models of the reviewing process
e.g. Cole, Jr, and Simon (1981);Lindsey (1988);Ragone et al. (2013);Nihar B. Shah et al. (2016);Whitehurst (1984).
The experimental data from Neurips experiments might be useful: See e.g. Nihar B. Shah et al. (2016) or a blog post on the 2014 experiment (1, 2).
3 Economics of publishing
See academic publishing.

4 Assignment for peer review process
There is some fun mechanism design and algorithmic work involved in peer review, e.g.
- Charlin and Zemel (2013)
- Gasparyan et al. (2015)
- Jan (2018)
- Merrifield and Saari (2009)
- Solomon (2007)
- Xiao, Dörfler, and van der Schaar (2014)
- Y. Xu, Zhao, and Shi (2017)
- Experiments with the ICML 2020 Peer-Review Process
- NeurIPS 2024 Experiment on Improving the Paper-Reviewer Assignment. The literature review in this post is also good (Budish et al. 2009; Charlin, Zemel, and Boutilier 2011; Charlin and Zemel 2013; Flach et al. 2010; Goldsmith and Sloan 2007; Jecmen et al. 2020, 2022; Littman 2021; Liu, Suel, and Memon 2014; Mimno and McCallum 2007; Rodriguez and Bollen 2008; Nihar B. Shah 2022; Stelmakh, Shah, and Singh 2021; Tang, Tang, and Tan 2010; Taylor 2008; Tran, Cabanac, and Hubert 2017; Vijaykumar 2020; Y. E. Xu et al. 2024).
- Matthew Feeney, Markets in fact-checking
5 Gatekeeping
Almost by definition we will be dissatisfied with how much gatekeeping academia does; we all have skin in this game.
Baldwin (2018):
This essay traces the history of refereeing at specialist scientific journals and at funding bodies and shows that it was only in the late twentieth century that peer review came to be seen as a process central to scientific practice. Throughout the nineteenth century and into much of the twentieth, external referee reports were considered an optional part of journal editing or grant making. The idea that refereeing is a requirement for scientific legitimacy seems to have arisen first in the Cold War United States. In the 1970s, in the wake of a series of attacks on scientific funding, American scientists faced a dilemma: there was increasing pressure for science to be accountable to those who funded it, but scientists wanted to ensure their continuing influence over funding decisions. Scientists and their supporters cast expert refereeing—or “peer review,” as it was increasingly called—as the crucial process that ensured the credibility of science as a whole. Taking funding decisions out of expert hands, they argued, would be a corruption of science itself. This public elevation of peer review both reinforced and spread the belief that only peer-reviewed science was scientifically legitimate.
Thomas Basbøll says
It is commonplace today to talk about “knowledge production” and the university as a site of innovation. But the institution was never designed to “produce” something nor even to be especially innovative. Its function was to conserve what we know. It just happens to be in the nature of knowledge that it cannot be conserved if it does not grow.
Andrew Marzoni, Academia is a cult.
Adam Becker on the assumptions and pathologies revealed by Wolfram’s latest branding and positioning:
So why did Wolfram announce his ideas this way? Why not go the traditional route? “I don’t really believe in anonymous peer review,” he says. “I think it’s corrupt. It’s all a giant story of somewhat corrupt gaming, I would say. I think it’s sort of inevitable that happens with these very large systems. It’s a pity.”
So what are Wolfram’s goals? He says he wants the attention and feedback of the physics community. But his unconventional approach—soliciting public comments on an exceedingly long paper—almost ensures it shall remain obscure. Wolfram says he wants physicists’ respect. The ones consulted for this story said gaining it would require him to recognise and engage with the prior work of others in the scientific community.
And when provided with some of the responses from other physicists regarding his work, Wolfram is singularly unenthused. “I’m disappointed by the naivete of the questions that you’re communicating,” he grumbles. “I deserve better.”
An interesting edge case in peer review and scientific reputation: Adam Becker, Junk Science or the Real Thing? ‘Inference’ Publishes Both. As far as I’m concerned, publishing crap in itself is not catastrophic. A process that fails to discourage crap by eventually identifying it would be bad.
6 Style guide for reviews and rebuttals
See scientific writing.
7 Reformers
8 Grants
TBD
9 Publication bias
Multiple testing across a whole scientific field, with a side helping of biased data release and terrible incentives.
On one hand, we hope that journals will help us find things that are relevant. On the other hand, we hope the things they help us find are actually true. It’s not at all obvious how to solve these kinds of classification problems economically, but we kind of hope that peer review does it.
To read: My likelihood depends on your frequency properties.
Keywords: “file-drawer process” and the “publication sieve”, which are the large-scale models of how this works in a scientific community and “researcher degrees of freedom” which is the model for how this works at the individual scale.
This is particularly pertinent in social psychology, where it turns out there is too much bullshit with
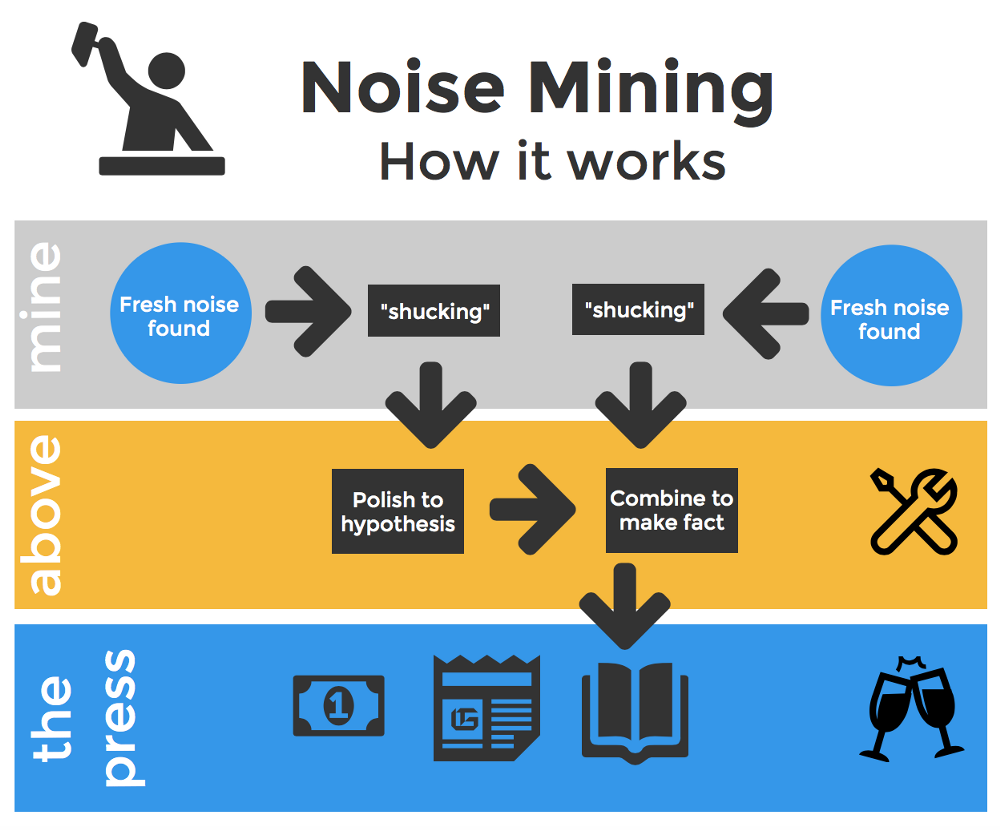
Sanjay Srivastava, Everything is fucked, the syllabus.

10 Fixing P-hacking and related science-at-large problems

Oliver Traldi reviews Stuart Ritchie’s book Science Fictions which uses the replication crisis in psychology as a lens to understand science’s flaws.
Serious though this is, there is also something more specifically pernicious about the replication crisis in psychology. We saw that the bias in psychological research is in favour of publishing exciting results. An exciting result in psychology is one that tells us that something has a large effect on people’s behaviour. And the things that the studies that have failed to replicate have found to have large effects on people’s behaviour are not necessarily things that ought to affect people’s behaviour, were those people rational. Think of the studies I mentioned above: a mess makes people more prejudiced; a random assignment of roles makes people sadistic; a list of words makes people walk at a different speed; a strange pose makes people more confident. And so on.
Experiment guide maintains a list of refuted claims from observational studies.
Uri Simonsohn’s article on detecting the signature of p-hacking is interesting.
Some might say, just fix the incentives, but apparently that is off the table because it would require political energy. There is open notebook science, that could be a thing.
Failing the budget for that… pre-registration?
Tom Stafford’s 2 minute guide to experiment pre-registration:
Pre-registration is easy. There is no single, universally accepted, way to do it.
you could write your data collection and analysis plan down and post it on your blog.
you can use the Open Science Framework to timestamp and archive a pre-registration, so you can prove you made a prediction ahead of time.
you can visit AsPredicted.org which provides a form to complete, which will help you structure your pre-registration (making sure you include all relevant information).
“Registered Reports”: more and more journals are committing to published pre-registered studies. They review the method and analysis plan before data collection and agree to publish once the results are in (however they turn out).
But should you in fact pre-register?
Morally, for the good of science, perhaps. But not in the sense that it’s something that you should do if you want to progress in your career. Rather the opposite. As argued by Ed Hagen, academic success is either a crapshoot or a scam:
The problem, in a nutshell, is that empirical researchers have placed the fates of their careers in the hands of nature instead of themselves. […]
Academic success for empirical researchers is largely determined by a count of one’s publications, and the prestige of the journals in which those publications appear […]
the minimum acceptable number of pubs per year for a researcher with aspirations for tenure and promotion is about three. This means that, each year, I must discover three important new things about the world. […] […]
Let’s say I choose to run 3 studies that each has a 50% chance of getting a sexy result. If I run 3 great studies, mother nature will reward me with 3 sexy results only 12.5% of the time. I would have to run 9 studies to have about a 90% chance that at least 3 would be sexy enough to publish in a prestigious journal.
I do not have the time or money to run 9 new studies every year.
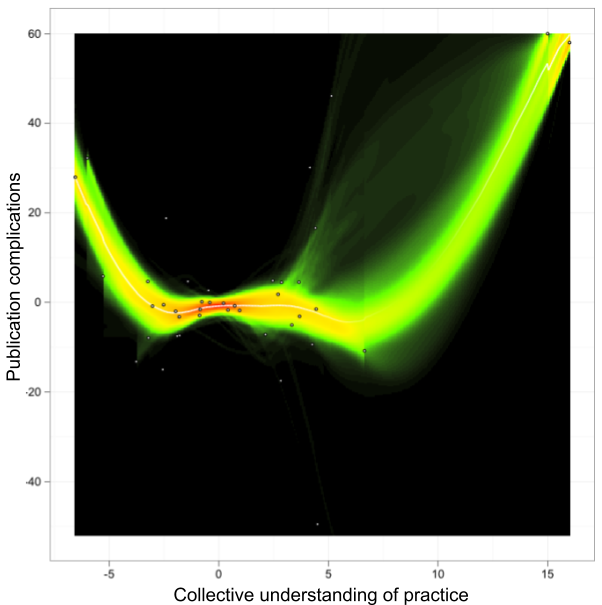
So, when does a certain practice—e.g., a study design, a way to collect data, a particular statistical approach—“succeed” and start to dominate journals?
It must be capable of surviving a multi-stage selection procedure:
- Implementation must be sufficiently affordable so that researchers can actually give it a shot
- Once the authors have added it to a manuscript, it must be retained until submission
- The resulting manuscript must enter the peer-review process and survive it (without the implementation of the practice getting dropped on the way)
- The resulting publication needs to attract enough attention post-publication so that readers will feel inspired to implement it themselves, fueling the eternally turning wheel of
Samsarapublication-oriented science
Erik van Zwet, Shrinkage Trilogy Explainer models the publication process
The Control Group Is Out Of Control provides good links for parapsychology as a control group for science.
11 On the easier problem of local theories
On the other hand, we can all agree that finding small-effect universal laws in messy domains like human society is a hard problem. In machine learning, we frequently give up on that and just try to solve a local problem — does this work in this domain with enough certainty to help this problem? Then we still need to solve a problem about domain adaptation when we try to work out if we are still working on this problem, or at least one similar enough to this. But that feels like it might be easier by virtue of being less ambitious.
12 Incoming

Saloni Dattani, Real peer review has never been tried
Matt Clancy, What does peer review know?
Adam Mastroianni, The rise and fall of peer review
Étienne Fortier-Dubois, Why Is ‘Nature’ Prestigious?
Science and the Dumpster Fire | Elements of Evolutionary Anthropology
F1000Research | Open Access Publishing Platform | Beyond a Research Journal
F1000Research is an Open Research publishing platform for scientists, scholars and clinicians offering rapid publication of articles and other research outputs without editorial bias. All articles benefit from transparent peer review and editorial guidance on making all source data openly available.
Reviewing is a Contract - Rieck on the social expectations of reviewing and chairing.
Jocelynn Pearl proposes some fun ideas, including blockchainy ones, in Time for a Change: How Scientific Publishing is Changing For The Better.
Andrew Gelman in conversation with Noah Smith
Anyway, one other thing I wanted to get your thoughts on was the publication system and the quality of published research. The replication crisis and other skeptical reviews of empirical work have got lots of people thinking about ways to systematically improve the quality of what gets published in journals. Apart from things you’ve already mentioned, do you have any suggestions for doing that?
I wrote about some potential solutions in pages 19–21 of Gelman (2018) from a few years ago. But it’s hard to give more than my personal impression. As statisticians or methodologists we rake people over the coals for jumping to causal conclusions based on uncontrolled data, but when it comes to science reform, we’re all too quick to say, Do this or Do that. Fair enough: policy exists already and we shouldn’t wait on definitive evidence before moving forward to reform science publication, any more than journals waited on such evidence before growing to become what they are today. But we should just be aware of the role of theory and assumptions in making such recommendations. Eric Loken and I made this point several years ago in the context of statistics teaching (Gelman and Loken 2012), and Berna Devezer et al. published an article (Devezer et al. 2020) last year critically examining some of the assumptions that have at times been taken for granted in science reform. When talking about reform, there are so many useful directions to go, I don’t know where to start. There’s post-publication review (which, among other things, should be much more efficient than the current system for reasons discussed here), there are all sorts of things having to do with incentives and norms (for example, I’ve argued that one reason that scientists act so defensive when their work is criticised is because of how they’re trained to react to referee reports in the journal review process), and various ideas adapted to specific fields. One idea I saw recently that I liked was from the psychology researcher Gerd Gigerenzer, who wrote that we should consider stimuli in an experiment as being a sample from a population rather than thinking of them as fixed rules (Gigerenzer n.d.), which is an interesting idea in part because of its connection to issues of external validity or out-of-sample generalisation that are so important when trying to make statements about the outside world. * The Black Spatula Project - by Steve Newman
A 10 page paper caused a panic because of a math error. I was curious if Al would spot the error by just prompting: “carefully check the math in this paper” especially as the info is not in training data.
o1 gets it in a single shot. Should Al checks be standard in science?
Repo here: nick-gibb/black-spatula-project: Verifying scientific papers using LLMs
(Smaldino2020Interdisciplinarity?):
Why do bad methods persist in some academic disciplines, even when they have been clearly rejected in others? What factors allow good methodological advances to spread across disciplines? In this paper, we investigate some key features determining the success and failure of methodological spread between the sciences. We introduce a formal model that considers factors like methodological competence and reviewer bias towards one’s own methods. We show how self-preferential biases can protect poor methodology within scientific communities, and lack of reviewer competence can contribute to failures to adopt better methods. We then use a second model to further argue that input from outside disciplines, especially in the form of peer review and other credit assignment mechanisms, can help break down barriers to methodological improvement. This work therefore presents an underappreciated benefit of interdisciplinarity.
when does a certain practice–e.g., a study design, a way to collect data, a particular statistical approach–”succeed” and start to dominate journals?
It must be capable of surviving a multi-stage selection procedure:
- Implementation must be sufficiently affordable so that researchers can actually give it a shot
- Once the authors have added it to a manuscript, it must be retained until submission
- The resulting manuscript must enter the peer-review process and survive it (without the implementation of the practice getting dropped on the way)
- The resulting publication needs to attract enough attention post-publication so that readers will feel inspired to implement it themselves, fueling the eternally turning wheel of
Samsarapublication-oriented science