Neural nets
Designing the fanciest usable differentiable loss surface
2016-10-14 — 2020-09-09
Wherein the revival of deep learning is described, and dependence on incremental algorithmic tweaks and SIMD GPU hardware for training many-layered models on vast datasets is noted, with recurrent and convolutional variants mentioned.
Modern computational neural network methods reascend the hype phase transition. a.k.a deep learning or double plus fancy brainbots or please give the department a bigger GPU budget it’s not to play video games I swear.
I don’t intend to write an introduction to deep learning here; that ground has been tilled already.
Here are some handy links to resources I frequently use, and a bit of under-discussed background.
1 What?
To be specific, deep learning is
- a library of incremental improvements in areas such as Stochastic Gradient Descent, approximation theory, graphical models, and signal processing research, plus some handy advancements in SIMD architectures that, taken together, surprisingly elicit the kind of results from machine learning that everyone was hoping we’d get by at least 20 years ago, yet without requiring us to develop substantially more clever grad students to do so, or,
- the state-of-the-art in artificial kitten recognition.
- a metastasising buzzword
It’s a frothy (some might say foamy-mouthed) research bubble right now, with such cuteness at the extrema as, e.g. Inceptionising inceptionism (Andrychowicz et al. 2016) which learns to learn neural networks using neural networks. (well, it sort of does that, but is a long way from a bootstrapping general AI) Stay tuned for more of this.
There is not much to do with “neurons” left in the paradigm at this stage. What there is, is a bundle of clever tricks for training deep constrained hierarchical predictors and classifiers on modern computer hardware. Something closer to a convenient technology stack than a single “theory”.
Some network methods hew closer to the behaviour of real neurons, although not that close; simulating actual brains is a different discipline with only intermittent and indirect connection.
Subtopics of interest to me:
- recurrent networks
- compressing deep networks
- neural stack machines
- probabilistic learning
- generative models, esp for art
2 Why bother?
There are many answers.
2.1 The ultimate regression algorithm
…until the next ultimate regression algorithm.
It turns out that this particular learning model (class of learning models) and training technologies is surprisingly good at getting ever better models out of ever more data. Why burn three grad students on a perfect tractable and specific regression algorithm when you can use one algorithm to solve a whole bunch of regression problems, and which improves with the number of computers and the amount of data you have? How much of a relief is it to capital to decouple its effectiveness from the uncertainty and obstreperousness of human labour?
2.2 Cool maths
Function approximations, interesting manifold inference. Weird product measure things, e.g. (Montufar 2014).
Even the stuff I’d assumed was trivial, like backpropagation, has a few wrinkles in practice. See Michael Nielson’s chapter and Chrisopher Olah’s visual summary.
Yes, this is a regular paper mill. Not only are there probably new insights to be had, but also you can recycle any old machine learning insight, replace a layer in a network with that and poof — new paper.
2.3 Insight into the mind
🏗 Maybe.
There claims to be communication between real neurology and neural networks in computer vision, but elsewhere neural networks are driven by their similarities to other things, such as being differentiable relaxations of traditional models, (differentiable stack machines!) or of being licensed to fit hierarchical models without regard for statistical niceties.
There might be some kind of occasional “stylised fact”-type relationship.
For some works which lean harder into this, try neural neural networks.
2.4 Trippy art projects
3 Hip keywords for NN models
Not necessarily mutually exclusive; some design patterns you can use.
There are many summaries floating around. Some that I looked at are Tomasz Malisiewicz’s summary of Deep Learning Trends @ ICLR 2016, or the Neural network zoo or Simon Brugman’s deep learning papers.
Some of these are descriptions of topologies, others of training tricks or whatever. Recurrent and convolutional are two types of topologies you might have in your ANN. But there are so many other possible ones: “Grid”, “highway”, “Turing” others…
Many are mentioned in passing in David McAllester’s Cognitive Architectures post.
3.1 Probabilistic/variational
3.2 Convolutional
See the convnets entry.
3.3 Generative Adversarial Networks
3.4 Recurrent neural networks
Feedback neural networks structures to have with memory and a notion of time and “current” versus “past” state. See recurrent neural networks.
3.5 Transfer learning
I have seen two versions of this term.
One starts from the idea that if you have, say, a network that solves some particular computer vision problem well, possibly you can use them to solve another one without starting from scratch on another computer vision problem. This is the recycling someone else’s features framing. I don’t know why this has a special term — I think it’s so that you can claim to do “end-to-end” learning, but then actually do what everyone else has done forever and works totally OK, which is to re-use other people’s work like normal scientists.
The other version is you would like to do domain adaptation, which is to say, to learn on one dataset but still make good predictions on a different dataset.
These two things can clearly be related if you squint hard. Using ‘transfer learning’ in this second sense irritates me slightly because it already has so many names: I would describe that problem as external validity, instead of domain adaptation but other names spotted in the wild include dataset shift, covariate shift, data fusion and there are probably more. This is a fundamental problem in statistics, and the philosophy of science generally, and has been for a long time.
3.6 Attention mechanism
See Attention mechanism.
3.7 Spike-based
Most simulated neural networks are based on a continuous activation potential and discrete time, unlike spiking biological ones, which are driven by discrete events in continuous time. There are a great many other differences (to real biology). What difference does this in particular make? I suspect it means that time is handled differently.
3.8 Kernel networks
Kernel trick + ANN = kernel ANNs.
(Stay tuned for reframing more things as deep learning.)
Is this what convex networks (Bengio et al. 2005) are?
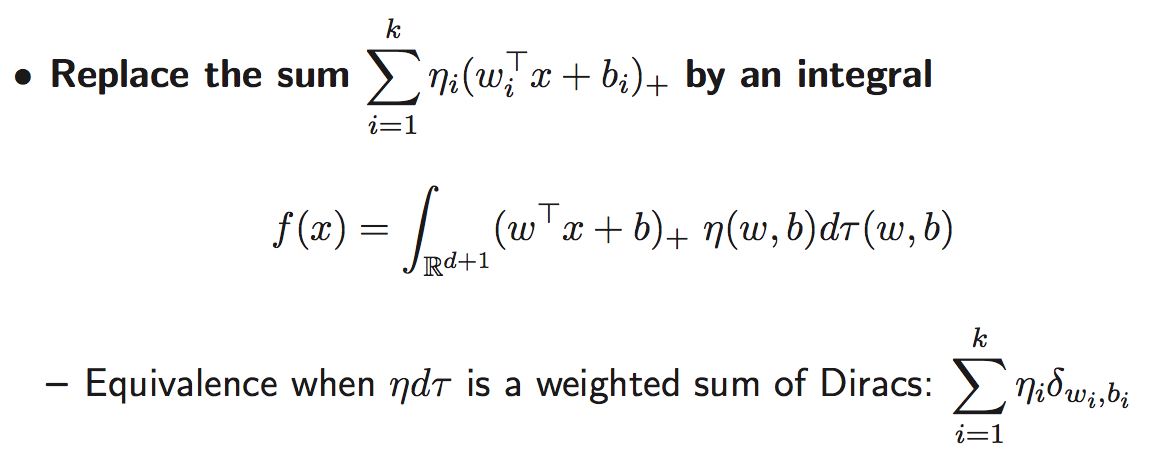
AFAICT these all boil down to rebadged extensions of Gaussian processes but maybe I’m missing something?
3.9 Autoencoding
🏗 Making a sparse encoding of something by demanding your network reproduces the after passing the network activations through a narrow bottleneck. Many flavours.
4 Optimisation methods
Backpropagation plus stochastic gradient descent rules at the moment.
Does anything else get performance at this scale? What other techniques can be extracted from variational inference or MC sampling, or particle filters, since there is no clear reason that shoving any of these in as intermediate layers in the network is any less well-posed than a classical backprop layer? Although it does require more nous from the enthusiastic grad student.